说话人识别概述
Posted ytxwzqin
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了说话人识别概述相关的知识,希望对你有一定的参考价值。
说话人识别(Speaker Recognition,SR),又称声纹识别(Voiceprint Recognition,VPR),顾名思义,即通过声音来识别出来“谁在说话”。语音识别(Automatic Speech Recognition,ASR)是通过声音识别出来“在说什么”。为了区分,本文的主题称为声纹识别VPR。
传统的VPR多是采用MFCC特征以及GMM模型框架,也取得了非常优秀的结果,不再赘述。后续也出现了I-ivector,深度学习等更多的算法框架。
说话人识别中的经典方法是I-Vector,I-Vector建模方式称为全局差异空间建模(Total Variability Modeling, TVM),采用该方法提取的I-Vector记为TVM-I-Vector。
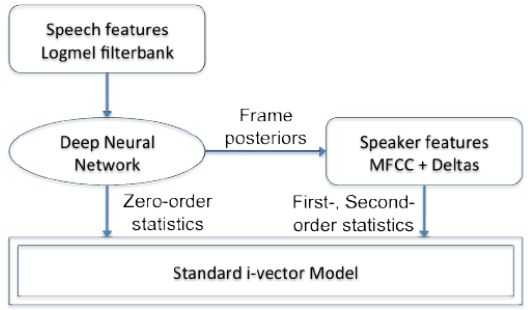
在基于TVM-I-Vector的声纹识别系统中,我们一般可以分为三个步骤。第一步是统计量的提取,第二步是提取I-Vector,第三步是进行信道补偿技术。统计量的提取是指将语音数据的特征序列,比如MFCC特征序列,用统计量来进行描述,提取的统计量属于高维特征,然后经过TVM建模,投影至低维空间中得到I-Vector。
在TVM-I-Vector建模中,统计量的提取是以UBM为基础的,根据UBM的均值及方差进行相应统计量的计算。
基于DNN的说话人识别的基本思想是取代TVM中的UBM产生帧级后验概率。即采用DNN进行帧级对齐的工作,继而计算训练数据的统计量,进行全局差异空间的训练以及I-Vector的提取。
目前没有详细证据证明深度神经网络或组合i-vector的深度神经网络性能一定优于i-vector方法,可能原因是说话人识别中信道干扰较多,难以搜集足够数据训练深度神经网络。
以上是关于说话人识别概述的主要内容,如果未能解决你的问题,请参考以下文章