技术瓶颈?如何解决MongoDB超大块数据问题?
Posted 哪 吒
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了技术瓶颈?如何解决MongoDB超大块数据问题?相关的知识,希望对你有一定的参考价值。

目录
大家好,我是哪吒,最近项目在使用MongoDB作为图片和文档的存储数据库,为啥不直接存mysql里,还要搭个MongoDB集群,麻不麻烦?
让我们一起,一探究竟,继续学习解决MongoDB超大块数据问题,实现快速入门,丰富个人简历,提高面试level,给自己增加一点谈资,秒变面试小达人,BAT不是梦。
一、MongoDB服务器管理
1、添加服务器
可以在任何时间添加mongos进程,只要确保,它们的 --configdb选项指定了正确的配置服务器副本集,并且客户端可以立即与其建立连接。
2、修改分片中的服务器
要修改一个分片的成员,需要直接连接到该分片的主节点,并重新配置副本集。集群配置会检测到变更并自动更新 config.shards。
3、删除分片
一般情况下,不应该从集群中删除分片,会给系统带来不必要的压力。
删除分片时,要确保均衡器的打开状态。
均衡器的作用是把要删除分片上的所有数据移动到其它分片,这个过程称为排空。可以通过 removeShard命令执行排空操作。

二、均衡器
可以通过 sh.setBalancerState(false)关闭均衡器。关闭均衡器不会将正在进行的过程停止,也就是说迁移过程不会立即停止。
通过db.locks.find("_id","balancer")["state"]查看均衡器是否关闭。0表示均衡器已关闭。
均衡过程会增加系统的负载,目标分片必须查询源分片的所有文档,并将文档插入目标分片的块中,然后源分片必须删除这些文档。
数据迁移是很消耗性能的,此时可以在config.settings集合中为均衡过程指定一个时间窗口。将其指定在一个闲暇时间执行。
如果设置了均衡窗口,应该对其进行监控,确保mongos能够在所分配的时间内保持集群的均衡。
均衡器使用块的数量而不是数据的大小作为度量。移动一个块被称为迁移,这是MongoDB平衡数据的方式。可能会存在一个大块的分片称为许多小分片迁移的目标。
三、修改块的大小
一个块可以存放数百万个文档,块越大,迁移到另一个分片所花费的时间就越长,默认情况下,块的大小为64MB。
但对于64MB的块,迁移时间太长了,为了加快迁移速度,可以减少块的大小。
比如将块的大小改为32MB。
db.settings.save("_id","chunksize","value":32)
已经存在的块不会发生改变,自动拆分仅会在插入或更新时发生,拆分操作是无法恢复的,如果增加了块的大小,那么已经存在的块只会通过插入或更新来增长,直到它们达到新的大小。块大小的取值范围在1MB到1024MB。
这是一个集群范围的设置,会影响所有的集合和数据库。因此,如果一个集合需要较小的块,另一个集合需要较大的块,那么可能需要在这两个大小间取一个折中的值。
如果MongoDB的迁移过于频繁或者使用的文档太大,则可能需要增加块的大小。
四、超大块
一个块的所有数据都位于某个特定的分片上。如果最终这个分片拥有的块比其它分片多,那么MongoDB会将一些块移动到其它分片上。
当一个块大于 config.settings中所设置的最大块大小时,均衡器就不允许移动这个块了。这些不可拆分、不可移动的块被称为超大块。
1、分发超大块
要解决超大块引起的集群不均衡问题,就必须将超大块均匀地分配到各个分片中。
2、分发超大块步骤:
- 关闭均衡器
sh.setBalancerState(false); - 因为MongoDB不允许移动超过最大块大小的块,所以要暂时先增大块大小,使其超过现有的最大块块大小。记录下当时的块大小。
db.settings.save("_id","chunksize","value":maxInteger); - 使用
moveChunk命令移动分片中的超大块; - 在源分片剩余的块上运行
splitChunk命令,直到其块数量与目标分片块数量大致相同; - 将块大小设置为其最初值;
- 开启均衡器

3、避免出现超大块
更改片键,使其拥有更细粒度的分片。
通过db.currentOp()查看当前操作,``db.currentOp()```最常见的用途是查找慢操作。
MongoDB Enterprise > db.currentOp()
"inprog" : [
"type" : "op",
"host" : "LAPTOP-P6QEH9UD:27017",
"desc" : "conn1",
"connectionId" : 1,
"client" : "127.0.0.1:50481",
"appName" : "MongoDB Shell",
"clientMetadata" :
"application" :
"name" : "MongoDB Shell"
,
"driver" :
"name" : "MongoDB Internal Client",
"version" : "5.0.14"
,
"os" :
"type" : "Windows",
"name" : "Microsoft Windows 10",
"architecture" : "x86_64",
"version" : "10.0 (build 19044)"
,
"active" : true,
"currentOpTime" : "2023-02-07T23:12:23.086+08:00",
"threaded" : true,
"opid" : 422,
"lsid" :
"id" : UUID("f83e33d1-9966-44a4-87de-817de0d804a3"),
"uid" : BinData(0,"47DEQpj8HBSa+/TImW+5JCeuQeRkm5NMpJWZG3hSuFU=")
,
"secs_running" : NumberLong(0),
"microsecs_running" : NumberLong(182),
"op" : "command",
"ns" : "admin.$cmd.aggregate",
"command" :
"aggregate" : 1,
"pipeline" : [
"$currentOp" :
"allUsers" : true,
"idleConnections" : false,
"truncateOps" : false
,
"$match" :
],
"cursor" :
,
"lsid" :
"id" : UUID("f83e33d1-9966-44a4-87de-817de0d804a3")
,
"$readPreference" :
"mode" : "primaryPreferred"
,
"$db" : "admin"
,
"numYields" : 0,
"locks" :
,
"waitingForLock" : false,
"lockStats" :
,
"waitingForFlowControl" : false,
"flowControlStats" :
,
"type" : "op",
"host" : "LAPTOP-P6QEH9UD:27017",
"desc" : "Checkpointer",
"active" : true,
"currentOpTime" : "2023-02-07T23:12:23.086+08:00",
"opid" : 3,
"op" : "none",
"ns" : "",
"command" :
,
"numYields" : 0,
"locks" :
,
"waitingForLock" : false,
"lockStats" :
,
"waitingForFlowControl" : false,
"flowControlStats" :
,
"type" : "op",
"host" : "LAPTOP-P6QEH9UD:27017",
"desc" : "JournalFlusher",
"active" : true,
"currentOpTime" : "2023-02-07T23:12:23.086+08:00",
"opid" : 419,
"op" : "none",
"ns" : "",
"command" :
,
"numYields" : 0,
"locks" :
,
"waitingForLock" : false,
"lockStats" :
,
"waitingForFlowControl" : false,
"flowControlStats" :
],
"ok" : 1
4、输出内容详解:
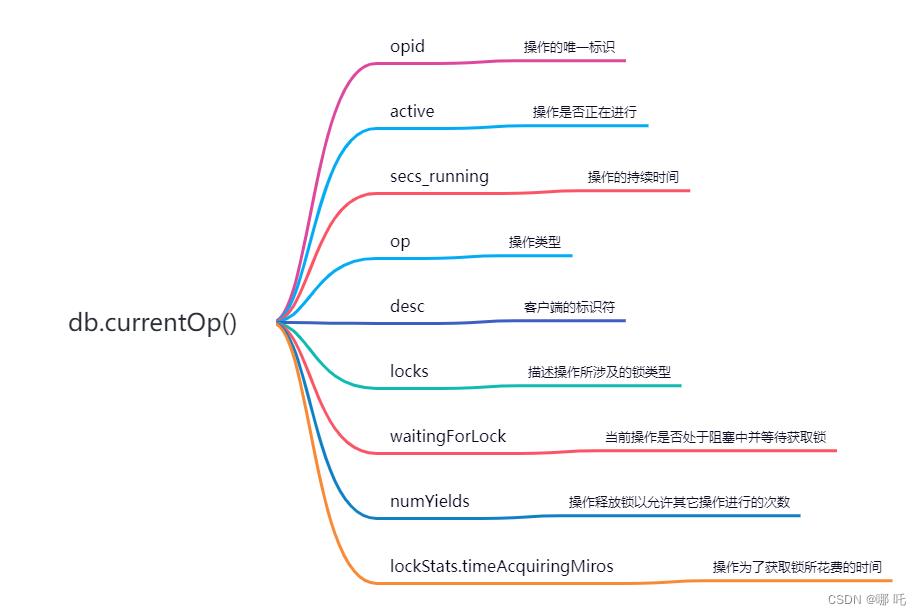
- opid,操作的唯一标识,可以使用这个字段来终止操作;
- active,操作是否正在进行,如果为false,意味着此操作已经让出或者正在等待其它操作交出锁;
- secs_running,操作的持续时间,可以使用这个字段查询耗时过长的操作;
- op,操作类型,通常为query、insert、update、remove;
- desc,客户端的标识符,可以与日志中的消息相关联;
- locks,描述操作所涉及的锁类型;
- waitingForLock,当前操作是否处于阻塞中并等待获取锁;
- numYields,操作释放锁以允许其它操作进行的次数。一个操作只有在其它操作进入队列并等待获取它的锁时才会让出自己的锁,如果没有操作处于
waitingForLock状态,则当前操作不会让出锁; - lockStats.timeAcquiringMiros,操作为了获取锁所花费的时间;
通过``db.currentOp()找到慢查询后,可以通过db.killOp(opid)```的方式将其终止。
并不是所有操作都可以被终止,只有当操作让出时,才能终止,因此,更新、查找、删除操作都可以被终止,但持有或等待锁的操作不能被终止。
如果MongoDB中的请求发生了堆积,那么这些写操作将堆积在操作系统的套接字缓冲区,当终止MongoDB正在运行的写操作时,MongoDB依旧会处理缓冲区的写操作。可以通过开启写入确认机制,保证每次写操作都要等前一个写操作完成后才能执行,而不是仅仅等到前一个写操作处于数据库服务器的缓冲区就开始下一次写入。
五、系统分析器
系统分析器可以提供大量关于耗时过长操作的信息,但系统分析器会严重的降低MongoDB的效率,因为每次写操作都会将其记录在system.profile中记录一下。每次读操作都必须等待system.profile写入完毕才行。
开启分析器:
MongoDB Enterprise > db.setProfilingLevel(2)
"was" : 0, "slowms" : 100, "sampleRate" : 1, "ok" : 1
slowms决定了在日志中打印慢速操作的阈值。比如slowms设置为100,那么每个耗时超过100毫秒的操作都会被记录在日志中,即使分析器是关闭的。
查询分析级别:
MongoDB Enterprise > db.getProfilingLevel()
2
重新启动MongoDB数据库会重置分析级别。
六、一些常见的辅助命令
通过Object.bsonsize函数获取其在磁盘中存储大小,单位是字节。
> Object.bsonsize(db.worker.find())
65194
使用mongotop统计哪些集合最繁忙。
使用mongotop --locks统计每个数据库的锁信息。
mongostat提供了整个服务器范围的信息。


以上是关于技术瓶颈?如何解决MongoDB超大块数据问题?的主要内容,如果未能解决你的问题,请参考以下文章