mapreduce中加入combiner
Posted amyheartxy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了mapreduce中加入combiner相关的知识,希望对你有一定的参考价值。
combiner相当于是一个本地的reduce,它的存在是为了减少网络的负担,在本地先进行一次计算再叫计算结果提交给reduce进行二次处理。
现在的流程为:
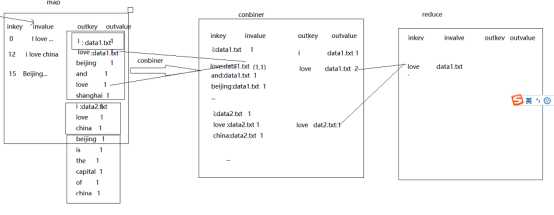
对于combiner我们有这些理解:


Mapper代码展示:


package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileSplit; public class MyMap extends Mapper<LongWritable, Text, Text, Text> { @Override protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, Text>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub //获取到单词 String line=value.toString(); String[] words=line.split(" "); //获取到文件名 FileSplit filesplit = (FileSplit)context.getInputSplit(); String fileName = filesplit.getPath().getName().trim();//.substring(0,5). String outkey=null; for (String word : words) { //字母+:+文件名 outkey=word.trim()+":"+fileName; System.out.println("map:"+outkey); context.write(new Text(outkey), new Text("1")); } } }
Combiner代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyCombiner extends Reducer<Text, Text, Text, Text>{ @Override protected void reduce(Text key, Iterable<Text> values,Context context) throws IOException, InterruptedException { Text n = null;//输出key int count=0; Text m=null;//输出value for(Text v :values){ //对同一个map输出的k,v对进行按k进行一次汇总。不同map的k,v汇总必须要用reduce方法 String[] words=key.toString().split(":"); n=new Text(words[0].trim());//字母--key System.out.println("MyCombiner KEY:"+n); count+=Integer.parseInt(v.toString()); m=new Text("("+words[1].trim()+" "+count+")"); } System.out.println("MyCombiner value:"+m); context.write(n, m); } }
Reduce代码展示:
package com.nenu.mprd.test; import java.io.IOException; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; public class MyReduce extends Reducer<Text, Text, Text, Text> { @Override protected void reduce(Text key, Iterable<Text> values, Reducer<Text, Text, Text, Text>.Context context) throws IOException, InterruptedException { // TODO Auto-generated method stub System.out.println("reduce: key"+key); String out=""; for (Text Text : values) { //sum+=intWritable.get(); out+=Text.toString()+" "; } System.out.println("reduce value:"+out); context.write(key, new Text(out)); } }
Job代码展示:
package com.nenu.mprd.test; import java.net.URI; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class MyJob extends Configured implements Tool{ public static void main(String[] args) throws Exception { MyJob myJob=new MyJob(); ToolRunner.run(myJob, null); } @Override public int run(String[] args) throws Exception { // TODO Auto-generated method stub Configuration conf=new Configuration(); conf.set("fs.defaultFS", "hdfs://192.168.64.141:9000"); //添加自动删除hadoop下的文件 //如果导成架包则需要改变一些参数作为手动输入 FileSystem filesystem =FileSystem.get(new URI("hdfs://192.168.64.141:9000"), conf, "root"); Path deletePath=new Path("/hadoop/wordcount/city/out"); if(filesystem.exists(deletePath)){ filesystem.delete(deletePath,true);//str: b: } Job job=Job.getInstance(conf); job.setJarByClass(MyJob.class); job.setMapperClass(MyMap.class); //设置combiner 如果combiner和reduce一样则可以不用设置 job.setCombinerClass(MyCombiner.class); job.setReducerClass(MyReduce.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(Text.class); FileInputFormat.addInputPath(job, new Path("/hadoop/wordcount/city")); FileOutputFormat.setOutputPath(job, new Path("/hadoop/wordcount/city/out")); job.waitForCompletion(true); return 0; } }
以上是关于mapreduce中加入combiner的主要内容,如果未能解决你的问题,请参考以下文章