分布式系列之缓存设计中常见的问题
Posted linlinismine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式系列之缓存设计中常见的问题相关的知识,希望对你有一定的参考价值。
缓存这个东西相信大家工作中都接触得比较多,相应的在不同场景下也会遇到各种各样的问题。下面我列举几种可能会遇到的问题并提供一些解决建议。
1、如何把海量数据存放在缓存中并提供快速查询
现实中我们的缓存通常都是以string,map,array,list,set,tree等具体的类型或者集合存放内存中,它们的共同点都在于把元素具体内容放到内存里面。这种在元素数量小的时候是没问题。但一旦数据量过大,消耗的内存也会呈现线性增长,最终达到瓶颈,并且查询效率也可能随着元素数量增长而下降。比如list与array,没有数字下标的情况下只能是0(n)遍历,有人也许会说到map的效率不是很高吗,查询效率可以达到O(1)。但这只是理想情况而已,hash冲突大的情况下map的查询也会退化,并且map也并没有解决内存消耗的问题。难道就没有办法解决这个问题吗?当然有!答案就是Bit-map和布隆过滤器!
什么是Bit-map?
所谓的Bit-map就是用一个bit位来标记某个元素对应的Value, 而Key即是该元素或者元素经过转换(比如hash)得到的值。由于采用了Bit为单位来存储数据,因此在存储空间方面,可以大大节省。原理如下图:
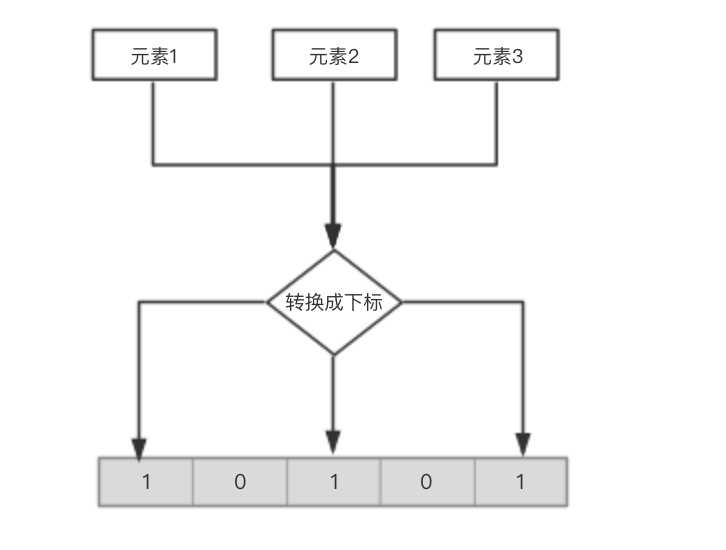
那1M的Bit-map可以表示多少数据呢,1兆字节(mb)=8388608比特(bit),也就是指我们可以用1M的内存表示800W+的数据。。。。
举个情景比如运营方给了一批100W用户ID,如果这批用户在指定时间内购买了某个商品就给用户派一张优惠劵,假设这100W的用户的userId都是64位的长整型数。那如何把这100W的用户存起来节省空间然后访问的性能也不差?我的建议是放到redis缓存里面利用redis的setbit,getbit的命令存储起来和访问,这样要比你存db要节省更多的空间并且查询速度也快~。如果这100W的用户ID分布范围比较随机,我建议是本地排好序,然后分成几段用不同Bit-map表示~,这样就不会造成过多不必要的空间浪费。别外本地排序也要以用Bit-map实现哦。
什么又是布隆过滤器?
布隆过滤器(英语:Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
基本概念和原理:
如果想判断一个元素是不是在一个集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表(又叫哈希表,Hash table)等等数据结构都是这种思路。但是随着集合中元素的增加,我们需要的存储空间越来越大。同时检索速度也越来越慢,上述三种结构的检索时间复杂度分别为O(n),O(logn),O(n/k)
布隆过滤器的原理是,当一个元素被加入集合时,通过K个散列函数将这个元素映射成一个位数组中的K个点,把它们置为1。检索时,我们只要看看这些点是不是都是1就(大约)知道集合中有没有它了:如果这些点有任何一个0,则被检元素一定不在;如果都是1,则被检元素很可能在。这就是布隆过滤器的基本思想。
所以说布隆过滤器底层还是依赖Bit-map的存储原理,因为是通过散列函数来进行映射就会有冲突的可能性,当元素a,b的hash出来index是一样的时候就无法判断到底Bit-map里面存的是a还是b。所以一般布隆过滤器是不允许删除元素的,因为真不知道删除的是哪个元素。。。。
布隆过滤器hash冲突性与散列函数的设计和Bit-map的大小有关,如果Bit-map太小那必然很多元素都会落到同一个下标,并且后面数量越大冲突也就越大。不过不用太担心毕竟1M的Bit-map就可以保存800W+数据~。
当你存储元素量不是很大的话,可以优先考虑散列表(map),数量大时布隆过滤器会不错的选择~。
2、高并发时缓存如何更新
在更新缓存时我们通常会加锁更新,为了减少锁住的资源,通常用分段锁的设计,只锁需要更新的资源。但在高并发的情景下大多数发请求都集中在一个key的时候也就是hot-key的情形下,对缓存进行更新。如果采用加锁的形式,就只能有一个线程去更新,其它的线程就只能同步阻塞,瞬间就有会大量线程hold住,甚至有可能把线程打满,这个时候系统的性能就会大打折扣。所以在高并发hot-key的情景下,加锁更新很影响性能。如果把读取和更新的操作隔离开来会怎样,如下图
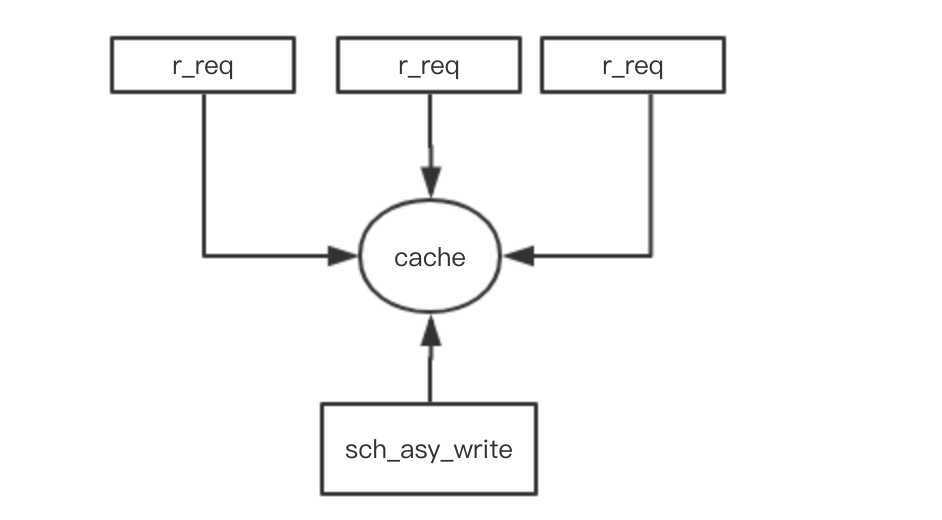
这种方案就是起额外的线程定时去定时去更新cache,这样读取线程就不会存在锁争的问题。这种通常cache不会设置超时时间,比如guava cache的refreshAfterWrite策略的cache就是永远不会超时的,只是每次读取的时候判断是否到了刷新周期,如果到了选取其中一个线程去更新,其它线程仍然返回旧值。所以这异步更新cache也不失为一个方法。只是要注意的控制好异步更新频率,频率太小那cache的实时性就会受影响。
3、Redis OR Memcache?
每当有人问我这个东西是用redis还是memcache存起来时,我会建议他从下面几个方面去考虑:
1、缓存的更新设置是怎样的?每次都get,set全部数据吗还是部分。
2、除了get,set还有其它操作吗?比如排序,获取前面5个元素?
3、预计缓存的qps有多少?
4、缓存需要持久化吗
5、单个缓存有多大
对于redis、memcache来说,我觉得如果是一般业务首先考虑的不应该是两者的性能问题,而是这两者提供的数据结构哪个更适切合你当前的业务需求还有将来业务的发展。在这一点方面redis无疑是占据了绝大优势,因为redis提供了String、Hash、List、Set和Sorted Set五种数据结构,而memcache只有key-value。所以一般我是优先考虑redis的。另外在单个缓存大小方面memcache的value存储,最大为1M,如果存储的value很大,只能使用redis。刚提到为什么不优先考虑性能问题呢?因为这两者的性能都不算差,并且后面都是可以横向扩展的,甚至还可以通过其它方式比如增加多层cache如local cache去提升。其实更多还是考虑业务的维护与迭代。如果你是纯k-v操作,并且数据量非常大,并发量非常大的业务,这个时候我建议你memcache会更适合你~,如果是其它redis可能会更适合你~。
以上是关于分布式系列之缓存设计中常见的问题的主要内容,如果未能解决你的问题,请参考以下文章