LinkedHashMap源码浅析jdk1.7
Posted kin1492
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了LinkedHashMap源码浅析jdk1.7相关的知识,希望对你有一定的参考价值。
LinkedHahsMap的继承关系
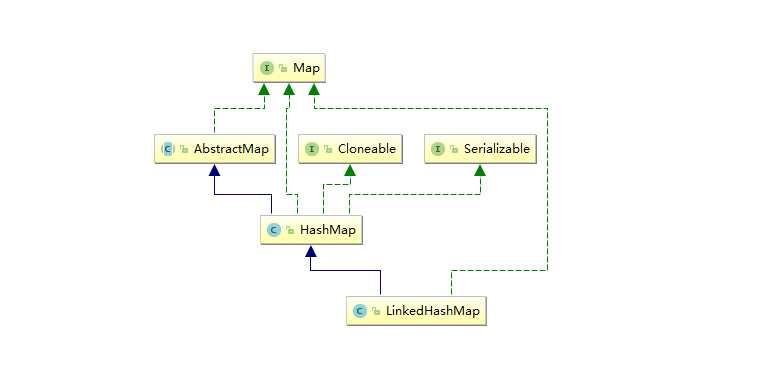
LinkedHashMap直接继承了HahsMap,而linkedHashMap和HashMap在同一个包下,因此HashMap中所有的非private的属性都能拿过来直接用。
LinkedHashMap继承HashMap原来的功能同时进行了修改。主要对原来Entry的结构进行了扩展,在继承父类Entry的基础上,有添加的两个属性Entry<K,V> before, after;和addBefore方法。同时覆盖了父类的init,addEntry,createEntry,transfer等方法,添加了header成员变量。
private transient Entry<K,V> header;
private static class Entry<K,V> extends HashMap.Entry<K,V> { // These fields comprise the doubly linked list used for iteration. Entry<K,V> before, after; Entry(int hash, K key, V value, HashMap.Entry<K,V> next) { super(hash, key, value, next); } /** * Removes this entry from the linked list. */ private void remove() { before.after = after; after.before = before; } /** * Inserts this entry before the specified existing entry in the list. */ private void addBefore(Entry<K,V> existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; } /** * This method is invoked by the superclass whenever the value * of a pre-existing entry is read by Map.get or modified by Map.set. * If the enclosing Map is access-ordered, it moves the entry * to the end of the list; otherwise, it does nothing. */ void recordAccess(HashMap<K,V> m) { LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m; if (lm.accessOrder) { lm.modCount++; remove(); addBefore(lm.header); } } void recordRemoval(HashMap<K,V> m) { remove(); } }
LinkedHashMap的初始化
linkedHashMap所有的构造方法里都调用了父类相关的构造方法,在父类构造中有调用了init方法,而linkedHashMap又覆盖了init方法,因此初始化先执行父类相关的操作,在执行自己init方法
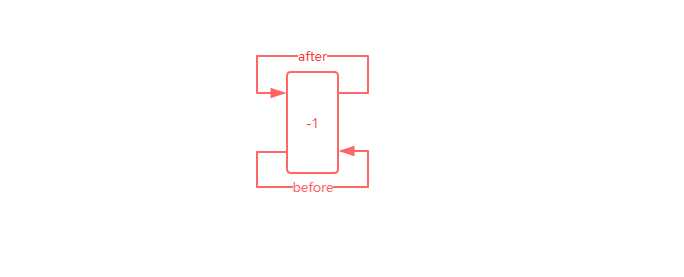
@Override void init() { header = new Entry<>(-1, null, null, null); header.before = header.after = header; }
init方法主要是将header实例化,实例化之后就会出现一个Entry类型的header的指针,其before和after都指向自己,如下图所示
LinkedHashMap put操作
linkedHashMap没有覆盖put方法,还是用父类的,因此调用父类的put会完成table属性的初始化,以及计算元素在table中的索引(调用的都是父类相关方法),然后调用addEntry方法,这时会调用自己的addEntry方法,因为linkedHashMap重写了addEntry方法
void addEntry(int hash, K key, V value, int bucketIndex) { // 调用父类的addEntry super.addEntry(hash, key, value, bucketIndex); // Remove eldest entry if instructed Entry<K,V> eldest = header.after; if (removeEldestEntry(eldest)) { removeEntryForKey(eldest.key); } }
在自己的addEntry方法里面又调用了父类的方法,父类的方法如下:
void addEntry(int hash, K key, V value, int bucketIndex) { //看是否需要扩容 if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } // 又调用createEntry createEntry(hash, key, value, bucketIndex); }
addEntry方法里有调用createEntry,同样linkedHashMap覆盖了父类的createEntry,调用本地的
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<>(hash, key, value, old);
table[bucketIndex] = e;
e.addBefore(header);
size++;
}
把entry添加到数组里面后,有调用了entry的addBefore方法
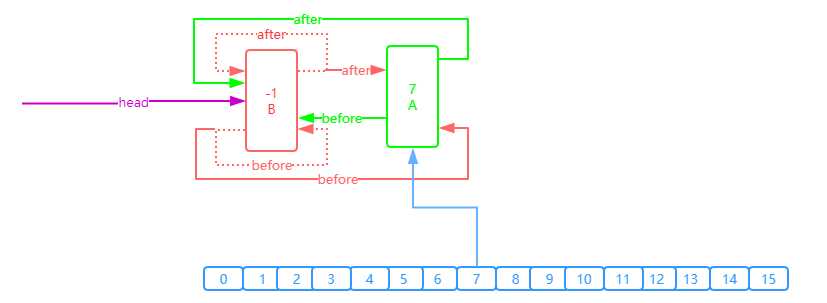
private void addBefore(Entry<K,V> existingEntry) { after = existingEntry; before = existingEntry.before; before.after = this; after.before = this; }
addBefore传进来的是header,进行如下操作
1. after = existingEntry;
把当前节点(比如是A)的after指向header(existingEntry传递的都是header), 因此A.after--->header
2. before = existingEntry.before;
当前节点的before指向 header所指向的before(header.before=B),A.before---->B
3. before.after = this;
也就是 B.after---->A
4. after.before = this;
相当于header.before--->A
如果是第一次添加,上面的B就是header对应如下图
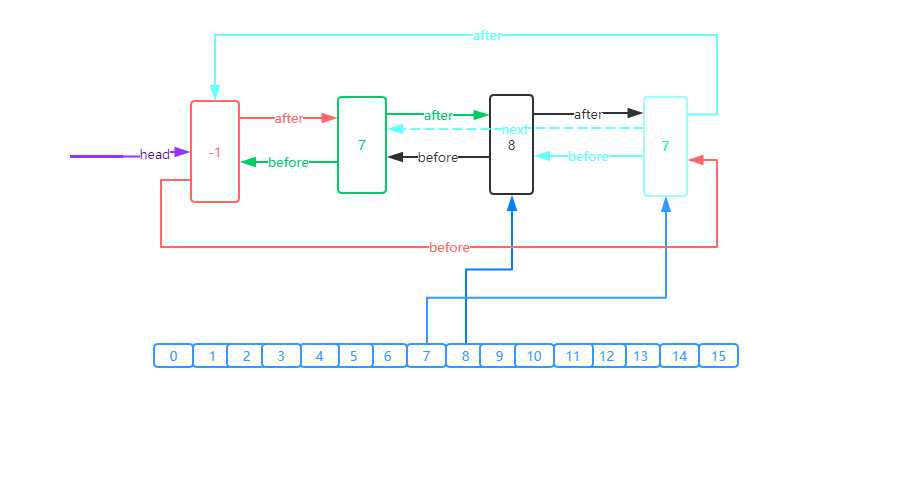
linkedHashMap的Entry之间按照元素的put的先后顺序形成了双向循环链表,hashMap中元素与元素没有先后顺序,没法知道元素的put先后顺序,而linkedHashMap每次添加元素时都能通过header找到上一次添加的元素,并建立各元素之间的联系。
LinkedHashMap和HashMap的结构的比较
linkedHashMap
HashMap
以上是关于LinkedHashMap源码浅析jdk1.7的主要内容,如果未能解决你的问题,请参考以下文章