决策树---连续值处理
Posted holly-blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树---连续值处理相关的知识,希望对你有一定的参考价值。
最近在复习机器学习的基本算法,再看周志华老师的《机器学习》决策树这一章时,发现,之前学习时都没决策树的连续值和缺失值处理。这两天看完了,这里记录一下
因为连续属性的可取值数目不再有限,因此不能像处理离散属性那样通过枚举离散属性取值来对结点进行划分。有点像处理连续信号那样,需要连续属性离散化,常用的离散化策略是二分法,这个技术也是C4.5中采用的策略。

下面以西瓜数据集的“密度”属性为例具体介绍下,如何采用二分法对连续属性离散化:
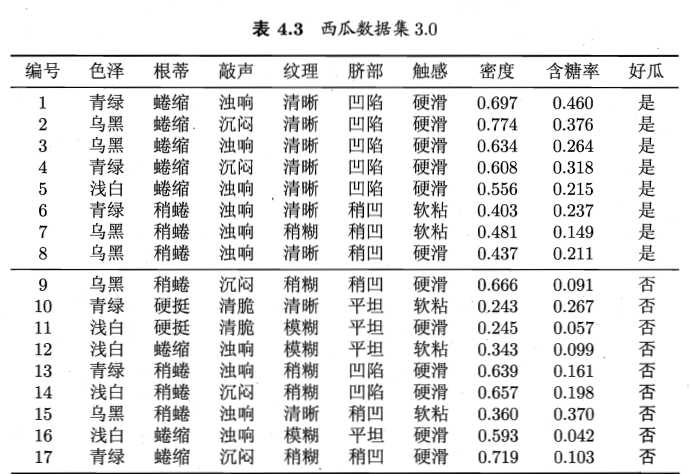
计算过程:
1.将根节点(要划分的节点)属性值(“密度”’)进行排序(由小到大)
2.计算划分点集合
3.计算划分点信息增益
具体过程如下:
1.对密度值进行划分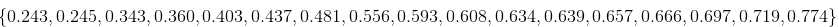
2.划分点集合: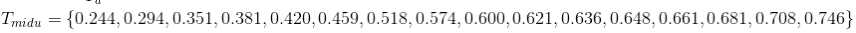
3.计算划分点信息增益

以此类推,计算出该根节点所有划分点t的信息增益,选出最大的信息增益0.263,此时,划分点为t= 0.381,选择该划分点。同理,可计算出含糖率作为划分属性时的最大信息增益为0.349,只是,根节点还是以纹理属性作为划分属性,因为,之前计算过,各属性作为划分属性时的信息增益。

以上是关于决策树---连续值处理的主要内容,如果未能解决你的问题,请参考以下文章