分布式缓存系列之guava cache
Posted linlinismine
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式缓存系列之guava cache相关的知识,希望对你有一定的参考价值。
guava是google的一个开源java框架,其github地址是 https://github.com/google/guava。guava工程包含了若干被Google的 Java项目广泛依赖的核心库,例如:集合 [collections] 、缓存 [caching] 、原生类型支持 [primitives support] 、并发库 [concurrency libraries] 、通用注解 [common annotations] 、字符串处理 [string processing] 、I/O 等等。 所有这些工具每天都在被Google的工程师应用在产品服务中。 其中caching这一块是我常用的模块的之一,今天就来分享一下我对guava cache的一些见解。
guava cache使用简介
guava cache 是利用CacheBuilder类用builder模式构造出两种不同的cache加载方式CacheLoader,Callable,共同逻辑都是根据key是加载value。不同的地方在于CacheLoader的定义比较宽泛,是针对整个cache定义的,可以认为是统一的根据key值load value的方法,而Callable的方式较为灵活,允许你在get的时候指定load方法。看以下代码
Cache<String,Object> cache = CacheBuilder.newBuilder()
.expireAfterWrite(10, TimeUnit.SECONDS).maximumSize(500).build();
cache.get("key", new Callable<Object>() { //Callable 加载
@Override
public Object call() throws Exception {
return "value";
}
});
LoadingCache<String, Object> loadingCache = CacheBuilder.newBuilder()
.expireAfterAccess(30, TimeUnit.SECONDS).maximumSize(5)
.build(new CacheLoader<String, Object>() {
@Override
public Object load(String key) throws Exception {
return "value";
}
});
这里面有几个参数expireAfterWrite、expireAfterAccess、maximumSize其实这几个定义的都是过期策略。expireAfterWrite适用于一段时间cache可能会发先变化场景。expireAfterAccess是包括expireAfterWrite在内的,因为read和write操作都被定义的access操作。另外expireAfterAccess,expireAfterAccess都是受到maximumSize的限制。当缓存的数量超过了maximumSize时,guava cache会要据LRU算法淘汰掉最近没有写入或访问的数据。这里的maximumSize指的是缓存的个数并不是缓存占据内存的大小。 如果想限制缓存占据内存的大小可以配置maximumWeight参数。
看代码:
CacheBuilder.newBuilder().weigher(new Weigher<String, Object>() {
@Override
public int weigh(String key, Object value) {
return 0; //the value.size()
}
}).expireAfterWrite(10, TimeUnit.SECONDS).maximumWeight(500).build();
weigher返回每个cache value占据内存的大小,这个大小是由使用者自身定义的,并且put进内存时就已经确定后面就再不会发生变动。maximumWeight定义了所有cache value加起的weigher的总和不能超过的上限。
注意一点就是maximumWeight与maximumSize两者只能生效一个是不能同时使用的!
guava cache的设计
guava cache作为一个被广泛使用的缓存组件,设计上它有哪些过人之处?
先看下cache的类实现定义
class LocalCache<K, V> extends AbstractMap<K, V> implements ConcurrentMap<K, V> {....}
我们看到了ConcurrentMap,所以我们知道了一点guava cache基于ConcurrentHashMap的基础上设计。所以ConcurrentHashMap的优点它也具备。既然实现了 ConcurrentMap那再看下guava cache中的Segment的实现是怎样?
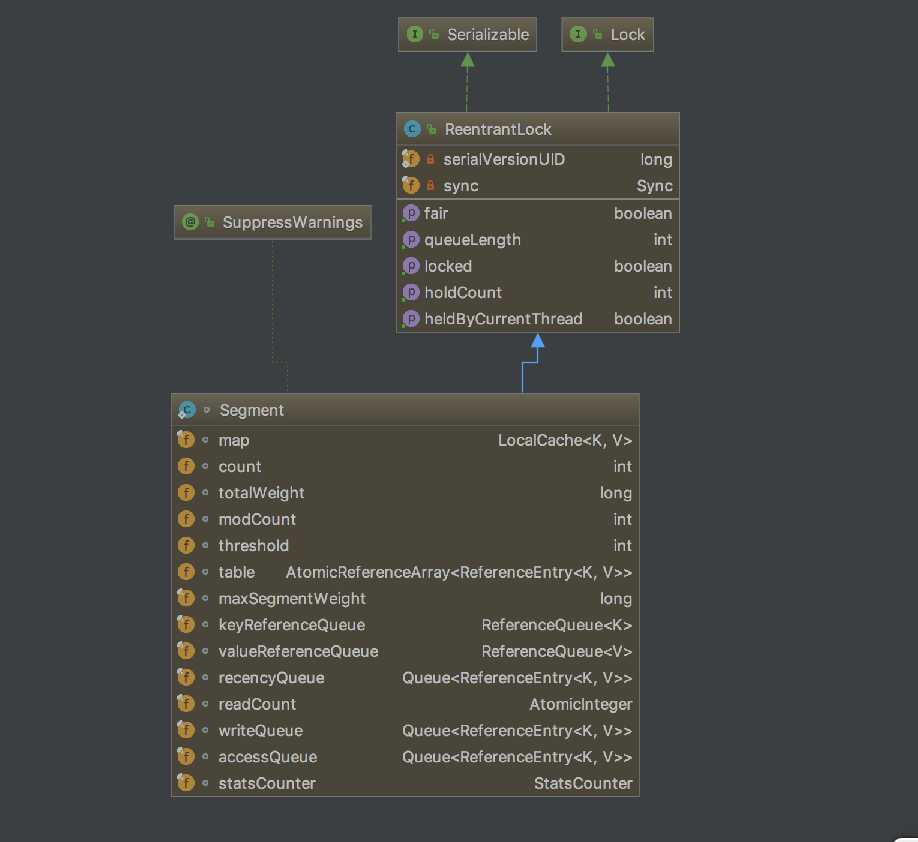
我们看到guava cache 中的Segment本质是一个ReentrantLock。内部定义了table,wirteQueue,accessQueue定义属性。其中table是一个ReferenceEntry原子类数组,里面就存放了cache的内容。wirteQueue存放的是对table的写记录,accessQueue是访问记录。guava cache的expireAfterWrite,expireAfterAccess就是借助这个两个queue来实现的。
了解了guava cache的大概存储结构,下面看通过对cache的操作来进行更深入的了解。
put(key,val)操作。
public V put(K key, V value) {
checkNotNull(key);
checkNotNull(value);
int hash = hash(key);
return segmentFor(hash).put(key, hash, value, false);
}
设置缓存大概的过程:根据key 哈希到对应的segment,然后对segment加锁lock(),然后获取segment.table对应的结点
int index = hash & (table.length() - 1); ReferenceEntry<K, V> first = table.get(index);
之后入队的过程和hashMap的入队过程类似。入队完之后还会进行相关操作比如更新accessQueue和wiriteQueue,累加totalWeight
void recordWrite(ReferenceEntry<K, V> entry, int weight, long now) {
// we are already under lock, so drain the recency queue immediately
drainRecencyQueue();
totalWeight += weight;
if (map.recordsAccess()) {
entry.setAccessTime(now);
}
if (map.recordsWrite()) {
entry.setWriteTime(now);
}
accessQueue.add(entry);
writeQueue.add(entry);
}
get(key)操作 。
第一步也是先定位到所在segment
V get(K key, CacheLoader<? super K, V> loader) throws ExecutionException {
int hash = hash(checkNotNull(key));
return segmentFor(hash).get(key, hash, loader);
}
判断key对应的ReferenceEntry存在
ReferenceEntry<K, V> e = getEntry(key, hash);
if (e != null) {
long now = map.ticker.read();
V value = getLiveValue(e, now);
if (value != null) {
recordRead(e, now);
statsCounter.recordHits(1);
return scheduleRefresh(e, key, hash, value, now, loader);
}
ValueReference<K, V> valueReference = e.getValueReference();
if (valueReference.isLoading()) {
return waitForLoadingValue(e, key, valueReference);
}
}
getLiveValue(e, now)如果返回了null就表示当前cache已经过期了,不为null时recordRead(e, now)记录最新访问时间为now,然后统计命中率。scheduleRefresh(e, key, hash, value, now, loader)相当于一个双重检查,再次检查cache有没有过期或者有不有其它线程在更新。如果都没有旧返回拿原值返回,有则调用loader方法去获取最新的值然后返回。
这时注意如果是loadingCache,并且valueReference.isLoading()为true的时候就表示有其它线程正在更新该cache,其它所有线程都要wait到这个线程loading完
才能返回。
key对应的ReferenceEntry不存在:缓存没有加载进来或者已经被remove掉。
return lockedGetOrLoad(key, hash, loader);
lockedGetOrLoad执行逻辑是先加锁lock(),判断当前是否有其它线程在loading该cache,如果有等待其加载完毕然后返回。否自己执行loader把值设进cache中然后返回。
try {
// Synchronizes on the entry to allow failing fast when a recursive load is
// detected. This may be circumvented when an entry is copied, but will fail fast most
// of the time.
synchronized (e) {
return loadSync(key, hash, loadingValueReference, loader);
}
} finally {
statsCounter.recordMisses(1);
}
guava cache的淘汰策略
guava cache总体来说有四种淘汰策略。
1、size-based 基本于使用量。
当缓存个数超过CacheBuilder.maximumSize(long)设置的值时,优先淘汰最近没有使用或者不常用的元素。同理CacheBuilder.maximumWeight(long)也是一样逻辑。
2、timed eviction 基于时间驱逐。
expireAfterAccess(long, TimeUnit)仅在指定上一次读/更新操作过了指定持续时间之后才考虑淘汰,淘汰逻辑与size-based是类似的。优先淘汰最近没有使用或者不常用的元素
expireAfterWrite(long, TimeUnit) 仅在指定上一次写/更新操作过了指定持续时间之后才考虑淘汰,淘汰逻辑与size-based是类似的。优先淘汰最近没有使用或者不常用的元素
3、Reference-based Eviction 基本于引用驱逐
在JDK1.2之后,Java对引用的概念进行了扩充,将引用分为强引用(Strong Reference)、软引用(Soft Reference)、弱引用(Weak Refernce)、虚引用(Phantom Reference)。四种引用强度依次减弱。这四种引用除了强引用(Strong Reference)之外,其它的引用所对应的对象来JVM进行GC时都是可以确保被回收的。所以通过使用弱引用的键、或弱引用的值、或软引用的值,Guava Cache可以把缓存设置为允许垃圾回收:
- CacheBuilder.weakKeys():使用弱引用存储键。当键没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用键的缓存用==而不是equals比较键。
- CacheBuilder.weakValues():使用弱引用存储值。当值没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用值的缓存用==而不是equals比较值。
- CacheBuilder.softValues():使用软引用存储值。软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。考虑到使用软引用的性能影响,我们通常建议使用更有性能预测性的缓存大小限定(使用软引用值的缓存同样用==而不是equals比较值)
这样的好处就是当内存资源紧张时可以释放掉到缓存的内存。注意!CacheBuilder如果没有指明默认是强引用的,GC时如果没有元素到达指定的过期时间,内存是不能被回收的。
4、显示删除
任何时候,你都可以显式地清除缓存项,而不是等到它被回收:
- 个别清除:Cache.invalidate(key)
- 批量清除:Cache.invalidateAll(keys)
- 清除所有缓存项:Cache.invalidateAll()
提一下guava cache 是怎么触发元素回收的。guava的元素回收与其它的一些框架不一样比如redis,redis是起额外的线程去回收元素。而guava是进行get,put操作的时候顺便把元素回收的。这样比一般的缓存另起线程监控清理相比,可以减少开销,但如果长时间没有调用方法的话,会导致不能及时的清理释放内存空间的问题。回收时主要处理四个Queue:1. keyReferenceQueue;2. valueReferenceQueue;3. writeQueue;4. accessQueue。前两个queue是因为WeakReference、SoftReference被垃圾回收时加入的,清理时只需要遍历整个queue,将对应的项从LocalCache中移除即可,这里keyReferenceQueue存放ReferenceEntry,而valueReferenceQueue存放的是ValueReference。而对后面两个Queue,只需要检查是否配置了相应的expire时间,然后从头开始查找已经expire的Entry,将它们移除即可。
总的来说,guava cache基于ConcurrentHashMap的优秀设计借鉴,在高并发场景支持线程安全,使用Reference引用命令,保证了GC的可回收到相应的数据,有效节省空间;同时write链和access链的设计,能更灵活、高效的实现多种类型的缓存清理策略,包括基于容量的清理、基于时间的清理、基于引用的清理等;
以上是关于分布式缓存系列之guava cache的主要内容,如果未能解决你的问题,请参考以下文章