Hive-1.2.1_06_累计报表查询
Posted zhanglianghhh
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hive-1.2.1_06_累计报表查询相关的知识,希望对你有一定的参考价值。
1. 数据准备
1 # 本地数据准备 2 [[email protected] hive]$ pwd 3 /app/software/hive 4 [[email protected] hive]$ ll /app/software/hive/t_access_times.dat 5 -rw-rw-r-- 1 yun yun 153 Jul 17 16:15 /app/software/hive/t_access_times.dat 6 [[email protected] hive]$ cat /app/software/hive/t_access_times.dat 7 A,2015-01-01,5 8 A,2015-01-05,15 9 B,2015-01-07,5 10 A,2015-01-10,8 11 B,2015-01-20,25 12 A,2015-01-31,5 13 A,2015-02-01,4 14 A,2015-02-10,6 15 B,2015-02-15,10 16 B,2015-02-25,5 17 A,2015-03-02,1 18 B,2015-03-02,2 19 A,2015-03-04,4 20 B,2015-03-07,4 21 A,2015-03-10,1 22 B,2015-03-12,8 23 A,2015-03-14,3 24 B,2015-03-17,6 25 A,2015-03-28,2 26 # hive 建表 27 hive (test_db)> create table t_access_times(username string,month string,salary int) 28 > row format delimited fields terminated by ‘,‘; 29 OK 30 Time taken: 0.16 seconds 31 32 # 数据上传 从desc formatted t_access_times; 可获取Location信息 33 0: jdbc:hive2://mini01:10000> load data local inpath ‘/app/software/hive/t_access_times.dat‘ [overwrite] into table t_access_times; # 上传 34 INFO : Loading data to table test_db.t_access_times from file:/app/software/hive/t_access_times.dat 35 INFO : Table test_db.t_access_times stats: [numFiles=1, totalSize=153] 36 No rows affected (0.764 seconds) 37 0: jdbc:hive2://mini01:10000> select * from t_access_times; # 查询数据 38 +--------------------------+-----------------------+------------------------+--+ 39 | t_access_times.username | t_access_times.month | t_access_times.salary | 40 +--------------------------+-----------------------+------------------------+--+ 41 | A | 2015-01-01 | 5 | 42 | A | 2015-01-05 | 15 | 43 | B | 2015-01-07 | 5 | 44 | A | 2015-01-10 | 8 | 45 | B | 2015-01-20 | 25 | 46 | A | 2015-01-31 | 5 | 47 | A | 2015-02-01 | 4 | 48 | A | 2015-02-10 | 6 | 49 | B | 2015-02-15 | 10 | 50 | B | 2015-02-25 | 5 | 51 | A | 2015-03-02 | 1 | 52 | B | 2015-03-02 | 2 | 53 | A | 2015-03-04 | 4 | 54 | B | 2015-03-07 | 4 | 55 | A | 2015-03-10 | 1 | 56 | B | 2015-03-12 | 8 | 57 | A | 2015-03-14 | 3 | 58 | B | 2015-03-17 | 6 | 59 | A | 2015-03-28 | 2 | 60 +--------------------------+-----------------------+------------------------+--+ 61 19 rows selected (0.102 seconds) 62 # 根据月份查询 去掉月份字段中的天信息 63 0: jdbc:hive2://mini01:10000> select a.username, substr(a.month,1,7) month, a.salary from t_access_times a; 64 +-------------+----------+-----------+--+ 65 | a.username | month | a.salary | 66 +-------------+----------+-----------+--+ 67 | A | 2015-01 | 5 | 68 | A | 2015-01 | 15 | 69 | B | 2015-01 | 5 | 70 | A | 2015-01 | 8 | 71 | B | 2015-01 | 25 | 72 | A | 2015-01 | 5 | 73 | A | 2015-02 | 4 | 74 | A | 2015-02 | 6 | 75 | B | 2015-02 | 10 | 76 | B | 2015-02 | 5 | 77 | A | 2015-03 | 1 | 78 | B | 2015-03 | 2 | 79 | A | 2015-03 | 4 | 80 | B | 2015-03 | 4 | 81 | A | 2015-03 | 1 | 82 | B | 2015-03 | 8 | 83 | A | 2015-03 | 3 | 84 | B | 2015-03 | 6 | 85 | A | 2015-03 | 2 | 86 +-------------+----------+-----------+--+ 87 19 rows selected (0.078 seconds)
2. 用户一个月总金额
1 # 或者使用 select x.username, x.month, sum(x.salary) from (select a.username, substr(a.month,1,7) month, a.salary from t_access_times a) x group by x.username, x.month; 2 0: jdbc:hive2://mini01:10000> select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7); 3 INFO : Number of reduce tasks not specified. Estimated from input data size: 1 4 INFO : In order to change the average load for a reducer (in bytes): 5 INFO : set hive.exec.reducers.bytes.per.reducer=<number> 6 INFO : In order to limit the maximum number of reducers: 7 INFO : set hive.exec.reducers.max=<number> 8 INFO : In order to set a constant number of reducers: 9 INFO : set mapreduce.job.reduces=<number> 10 INFO : number of splits:1 11 INFO : Submitting tokens for job: job_1531893043061_0002 12 INFO : The url to track the job: http://mini02:8088/proxy/application_1531893043061_0002/ 13 INFO : Starting Job = job_1531893043061_0002, Tracking URL = http://mini02:8088/proxy/application_1531893043061_0002/ 14 INFO : Kill Command = /app/hadoop/bin/hadoop job -kill job_1531893043061_0002 15 INFO : Hadoop job information for Stage-1: number of mappers: 1; number of reducers: 1 16 INFO : 2018-07-18 14:04:19,689 Stage-1 map = 0%, reduce = 0% 17 INFO : 2018-07-18 14:04:25,077 Stage-1 map = 100%, reduce = 0%, Cumulative CPU 3.08 sec 18 INFO : 2018-07-18 14:04:32,638 Stage-1 map = 100%, reduce = 100%, Cumulative CPU 5.53 sec 19 INFO : MapReduce Total cumulative CPU time: 5 seconds 530 msec 20 INFO : Ended Job = job_1531893043061_0002 21 +-------------+----------+------+--+ 22 | a.username | month | _c2 | 23 +-------------+----------+------+--+ 24 | A | 2015-01 | 33 | 25 | A | 2015-02 | 10 | 26 | A | 2015-03 | 11 | 27 | B | 2015-01 | 30 | 28 | B | 2015-02 | 15 | 29 | B | 2015-03 | 20 | 30 +-------------+----------+------+--+ 31 6 rows selected (18.755 seconds)
3. 将月总金额表 自己连接 自己连接
1 0: jdbc:hive2://mini01:10000> select * from 2 0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A 3 0: jdbc:hive2://mini01:10000> inner join 4 0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B 5 0: jdbc:hive2://mini01:10000> on A.username = B.username 6 0: jdbc:hive2://mini01:10000> ORDER BY A.username, A.`month`, B.`month`; 7 INFO : Number of reduce tasks not specified. Estimated from input data size: 1 8 ………………………… 9 INFO : Ended Job = job_1531893043061_0029 10 +-------------+----------+-----------+-------------+----------+-----------+--+ 11 | a.username | a.month | a.salary | b.username | b.month | b.salary | 12 +-------------+----------+-----------+-------------+----------+-----------+--+ 13 | A | 2015-01 | 33 | A | 2015-01 | 33 | 14 | A | 2015-01 | 33 | A | 2015-02 | 10 | 15 | A | 2015-01 | 33 | A | 2015-03 | 11 | 16 | A | 2015-02 | 10 | A | 2015-01 | 33 | 17 | A | 2015-02 | 10 | A | 2015-02 | 10 | 18 | A | 2015-02 | 10 | A | 2015-03 | 11 | 19 | A | 2015-03 | 11 | A | 2015-01 | 33 | 20 | A | 2015-03 | 11 | A | 2015-02 | 10 | 21 | A | 2015-03 | 11 | A | 2015-03 | 11 | 22 | B | 2015-01 | 30 | B | 2015-01 | 30 | 23 | B | 2015-01 | 30 | B | 2015-02 | 15 | 24 | B | 2015-01 | 30 | B | 2015-03 | 20 | 25 | B | 2015-02 | 15 | B | 2015-01 | 30 | 26 | B | 2015-02 | 15 | B | 2015-02 | 15 | 27 | B | 2015-02 | 15 | B | 2015-03 | 20 | 28 | B | 2015-03 | 20 | B | 2015-01 | 30 | 29 | B | 2015-03 | 20 | B | 2015-02 | 15 | 30 | B | 2015-03 | 20 | B | 2015-03 | 20 | 31 +-------------+----------+-----------+-------------+----------+-----------+--+ 32 18 rows selected (85.593 seconds) 33 ###################################################### 34 # 查询后排序 35 0: jdbc:hive2://mini01:10000> select * from 36 0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A 37 0: jdbc:hive2://mini01:10000> inner join 38 0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B 39 0: jdbc:hive2://mini01:10000> on A.username = B.username 40 0: jdbc:hive2://mini01:10000> where A.month >= B.month 41 0: jdbc:hive2://mini01:10000> ORDER BY A.username, A.month, B.month; 42 INFO : Number of reduce tasks not specified. Estimated from input data size: 1 43 ………………………… 44 INFO : Ended Job = job_1531893043061_0016 45 +-------------+----------+--------+-------------+----------+--------+--+ 46 | a.username | a.month | a._c2 | b.username | b.month | b._c2 | 47 +-------------+----------+--------+-------------+----------+--------+--+ 48 | A | 2015-01 | 33 | A | 2015-01 | 33 | 49 | A | 2015-02 | 10 | A | 2015-01 | 33 | 50 | A | 2015-02 | 10 | A | 2015-02 | 10 | 51 | A | 2015-03 | 10 | A | 2015-01 | 33 | 52 | A | 2015-03 | 10 | A | 2015-02 | 10 | 53 | A | 2015-03 | 10 | A | 2015-03 | 10 | 54 | B | 2015-01 | 30 | B | 2015-01 | 30 | 55 | B | 2015-02 | 15 | B | 2015-01 | 30 | 56 | B | 2015-02 | 15 | B | 2015-02 | 15 | 57 | B | 2015-03 | 20 | B | 2015-01 | 30 | 58 | B | 2015-03 | 20 | B | 2015-02 | 15 | 59 | B | 2015-03 | 20 | B | 2015-03 | 20 | 60 +-------------+----------+--------+-------------+----------+--------+--+ 61 12 rows selected (83.385 seconds)
4. 累计报表
4.1. 类似数据在mysql数据库查询
1 # 使用这个SQL语句就可了,但是在HIVE中运行不了 2 select A.username, A.month, A.salary , sum(B.salary) countSala from 3 (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A 4 inner join 5 (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B 6 on A.username = B.username 7 where A.month >= B.month 8 group by A.username, A.month 9 ORDER BY A.username, A.month, B.month;
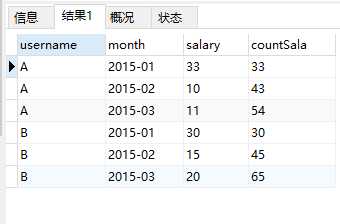
4.2. Hive中运行
1 # 上面的SQL不能运行 所以查询列表改为了max(A.salary) salary ; order by 中去掉了 B.month 。 2 0: jdbc:hive2://mini01:10000> select A.username, A.month, max(A.salary) salary, sum(B.salary) countSala from 3 0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) A 4 0: jdbc:hive2://mini01:10000> inner join 5 0: jdbc:hive2://mini01:10000> (select a.username, substr(a.month,1,7) month, sum(a.salary) salary from t_access_times a group by a.username, substr(a.month,1,7)) B 6 0: jdbc:hive2://mini01:10000> on A.username = B.username 7 0: jdbc:hive2://mini01:10000> where A.month >= B.month 8 0: jdbc:hive2://mini01:10000> group by A.username, A.month 9 0: jdbc:hive2://mini01:10000> ORDER BY A.username, A.month; 10 INFO : Number of reduce tasks not specified. Estimated from input data size: 1 11 ……………… 12 INFO : Ended Job = job_1531893043061_0052 13 +-------------+----------+---------+------------+--+ 14 | a.username | a.month | salary | countsala | 15 +-------------+----------+---------+------------+--+ 16 | A | 2015-01 | 33 | 33 | 17 | A | 2015-02 | 10 | 43 | 18 | A | 2015-03 | 11 | 54 | 19 | B | 2015-01 | 30 | 30 | 20 | B | 2015-02 | 15 | 45 | 21 | B | 2015-03 | 20 | 65 | 22 +-------------+----------+---------+------------+--+ 23 6 rows selected (106.718 seconds)
以上是关于Hive-1.2.1_06_累计报表查询的主要内容,如果未能解决你的问题,请参考以下文章
为啥 GraphQL 片段在查询中需要 __typename?