关于open falcon 与nightingale 的一些调研
Posted xiaobaiskill
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了关于open falcon 与nightingale 的一些调研相关的知识,希望对你有一定的参考价值。
针对 open-falcon 与 nightingale 的调研
一、open-falcon
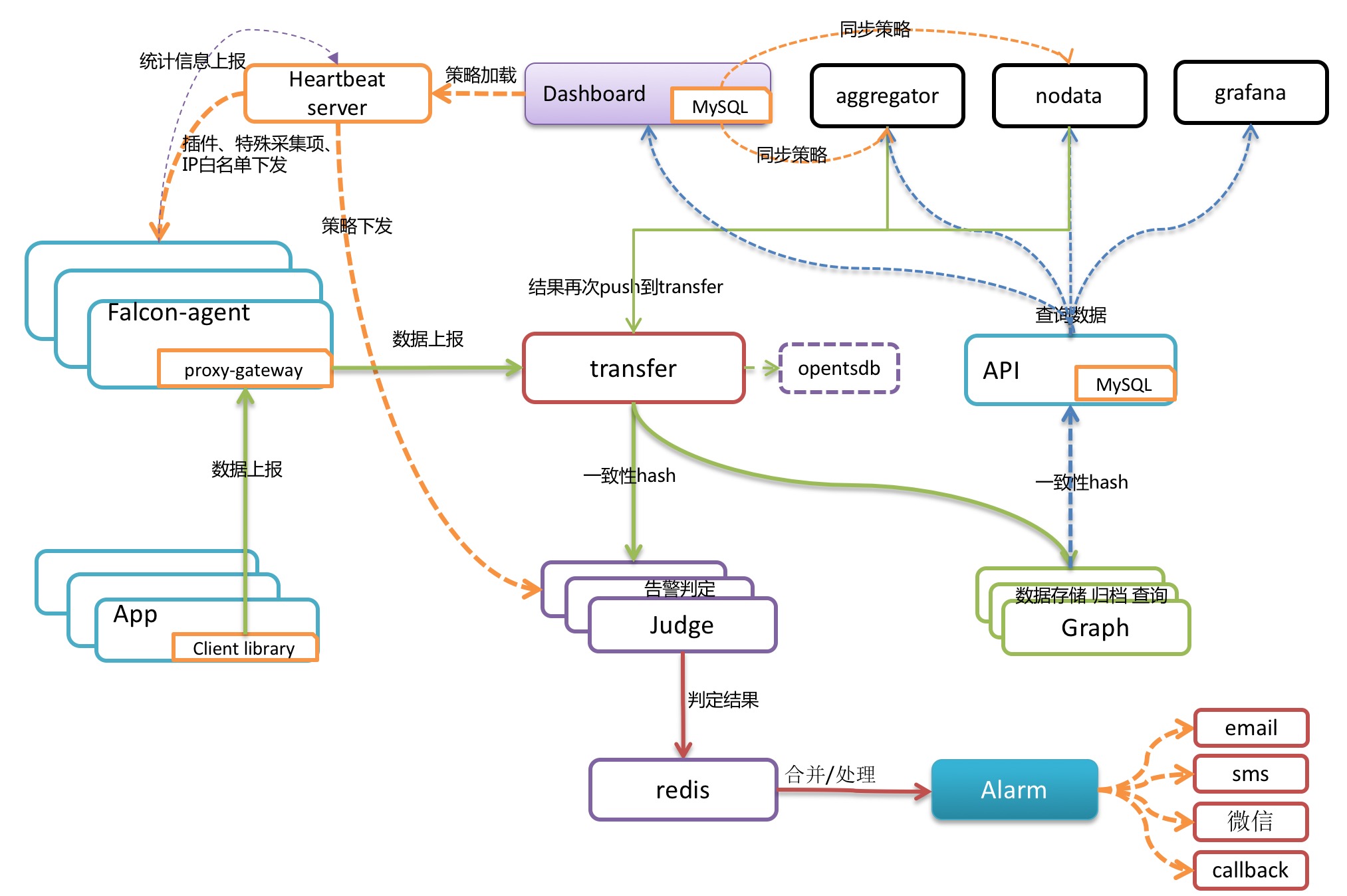
1.1 组件介绍
1.1.1 agent
> agent用于采集机器负载监控指标,比如cpu.idle、load.1min、disk.io.util等等,每隔60秒push给Transfer。agent与Transfer建立了长连接,数据发送速度比较快,agent提供了一个http接口/v1/push用于接收用户手工push的一些数据,然后通过长连接迅速转发给Transfer。
> agent需要部署到所有要被监控的机器上,比如公司有10万台机器,那就要部署10万个agent。agent本身资源消耗很少,不用担心。
1.1.2 transfer
> transfer是数据转发服务。它接收agent上报的数据,然后按照哈希规则进行数据分片、并将分片后的数据分别push给graph&judge等组件。同时 transfer 也支持将数据转发给 opentsdb 和 influxdb,也可以转发给另外一个 transfer。
1.1.3 graph
> graph是存储绘图数据的组件。graph组件 接收transfer组件推送上来的监控数据,同时处理api组件的查询请求、返回绘图数据。
1.1.4 api
> api组件,提供统一的restAPI操作接口。比如:api组件接收查询请求,根据一致性哈希算法去相应的graph实例查询不同metric的数据,然后汇总拿到的数据,最后统一返回给用户。
1.1.5 dashboard
控制台
1.1.6 hbs
> 心跳服务器,公司所有agent都会连到HBS,每分钟发一次心跳请求。
> agent发送心跳信息给HBS的时候,会把hostname、ip、agent version、plugin version等信息告诉HBS,HBS负责更新host表
> hbs是可以水平扩展的,至少部署两个实例以保证可用性。一般一个实例可以搞定5000台机器,所以说,如果公司有10万台机器,可以部署20个hbs实例,前面架设lvs,agent中就配置上lvs vip即可。
> HBS去获取所有的报警策略缓存在内存里
1.1.7 judge
> Judge用于告警判断,agent将数据push给Transfer,Transfer不但会转发给Graph组件来绘图,还会转发给Judge用于判断是否触发告警。
> HBS去获取所有的报警策略缓存在内存里,然后Judge去向HBS请求
1.1.8 alarm
> alarm模块是处理报警event的,judge产生的报警event写入redis,alarm从redis读取处理,并进行不同渠道的发送。
1.1.9 task
task是监控系统一个必要的辅助模块。定时任务,实现了如下几个功能:
> index更新。包括图表索引的全量更新 和 垃圾索引清理。
> falcon服务组件的自身状态数据采集。定时任务了采集了transfer、graph、task这三个服务的内部状态数据。
> falcon自检控任务。
1.1.10 gateway
> 如果您没有遇到机房分区问题,请直接忽略此组件。
1.1.11 nodata
> nodata用于检测监控数据的上报异常
> nodata和实时报警judge模块协同工作,过程为: 配置了nodata的采集项超时未上报数据,nodata生成一条默认的模拟数据;用户配置相应的报警策略,收到mock数据就产生报警。采集项上报异常检测,作为judge模块的一个必要补充,能够使judge的实时报警功能更加可靠、完善。
1.1.12 aggregator
集群聚合模块。聚合某集群下的所有机器的某个指标的值,提供一种集群视角的监控体验。
1.2 流程
二、nightingale
2.1 组件介绍
2.1.1 collector
类似于agent ,可以采集机器常见指标,支持日志监控,支持插件机制,支持业务通过接口直接上报数据
2.1.2 transfer
transfer提供rpc接口接收collector上报的数据,然后通过一致性哈希,将数据转发给多台tsdb和多台judge
2.1.3 tsdb
原来的graph组件,用于存储历史数据,支持配置为双写模式提升系统容灾能力,tsdb会把监控数据转发一份给index
2.1.4 index
index是索引模块,替换原来的mysql方案,在内存里构建索引,便于后续数据检索,性能大幅提升
2.1.5 judge
judge是告警引擎,从monapi(portal)同步监控策略,然后对接收到的数据做告警判断,如满足阈值,则生成告警事件推到redis
2.1.6 monapi(alarm)
> monapi(alarm)从redis读取judge生成的事件,进行二次处理,补充一些元信息,生成告警消息,重新推回redis
> 写入event 至mysql
2.1.7 通知消息个组件
各发送组件,比如mail-sender、sms-sender等,从redis读取告警消息,发送告警,抽出各类sender是为了后续定制方便
2.1.8 monapi
monapi集成了原来多个模块的功能,提供接口给js调用,api前缀为/api/portal,数据查询走transfer,干掉了原来的query组件,api前缀为/api/transfer,索引查询的api前缀/api/index,于是,前面搭建nginx,即可通过不同location将请求转发到不同后端
2.2 流程

三、对比
3.1 相同点
> nightingale 和 open falcon 再整体流程上较为相似。一些组件只是名称的变化,功能较为类似
3.2 不同点
> 数据存储 graph 在nightingale 中被改为了TSDB 内存存储.提升了数据查询效率(仅存储近几个小时的数据)
> open falcon:alarm 处理报警event 并进行发送; nightingale: monapi(alarm)从redis读取event处理后重新推回redis,再由各发送组件读取告警消息发送
> nighthingale 增加了index索引模块,代替了open falcon mysql方案,由内存中构建索引
> nightingale 将 openfalcon 中的api、uic、dashboard、hbs、alarm 合并为一个模块 monapi,简化部署难度
3.3 nightingale官方对比open-falcon的异同
3.3.1 不同点
> 告警引擎重构为推拉结合模式,通过推模式保证大部分策略判断的效率,通过拉模式支持了nodata告警,去除原来的nodata组件,简化系统部署难度
> 引入了服务树,对endpoint进行层级管理,去除原来扁平的HostGroup,同时干掉告警模板,告警策略直接与服务树节点绑定,大幅提升灵活度和易用性
> 干掉原来的基于数据库的索引库,改成内存模式,单独抽出一个index模块处理索引,避免了原来MySQL单表达到亿级的尴尬局面,索引基于内存之后效率也大幅提升
> 存储模块Graph,引入facebook的Gorilla,即内存TSDB,近期几个小时的数据默认存内存,大幅提升数据查询效率,硬盘存储方式仍然使用rrdtool
> 告警引擎judge模块通过心跳机制做到了故障自动摘除,再也不用担心单个judge挂掉导致部分策略失效的问题,index模块也是采用类似方式保证可用性
> 客户端中内置了日志匹配指标抽取能力,web页面上支持了日志匹配规则的配置,同时也支持读取目标机器特定目录下的配置文件的方式,让业务指标监控更为易用
> 将portal(falcon-plus中的api)、uic、dashboard、hbs、alarm合并为一个模块:monapi,简化了系统整体部署难度,原来的部分模块间调用变成进程内方法调用,稳定性更好
3.3.2 相同点
> 数据模型没有变化,仍然是metric、endpoint、tags的组织方式,所以agent基本是可以复用的,Nightingale中的agent叫collector,融合了原来Open-Falcon的agent和falcon-log-agent的逻辑,各种监控插件也都是可以复用的
> 数据流向和整体处理逻辑是类似的,仍然使用灵活的推模型,分为数据存储和告警判断两条链路,下一节我们基于架构图详细展开
四、调研
4.1、是否能否满足我们的需求
| cpu | mem | 网络 | 安全审计 | 采集器是否可扩展 | |
|---|---|---|---|---|---|
| nightingale | ? | ? | ? | ? | ? |
| open falcon | ? | ? | ? | ? | ? |
4.2、部署难度
两者之间的部署难度相近
nightingale 都是用go编写需额外用到 redis mysql 和nginx代理
open-falcon 后台使用go编写,前端使用python ,需额外redis 和 mysql
后端程序两者都可以一键启动多个组件
nightingale 节点的部署 略复杂于 open-falcon
4.3、各组件资源占用(初期)
nightingale :( 虚拟机 centos 1cpu 2G)
cpu mem module
0.2 1.1 /home/go-www/src/github.com/didi/nightingale/n9e-monapi
0.3 1.0 /home/go-www/src/github.com/didi/nightingale/n9e-transfer
0.0 0.8 /home/go-www/src/github.com/didi/nightingale/n9e-tsdb
0.0 0.8 /home/go-www/src/github.com/didi/nightingale/n9e-index
0.0 0.8 /home/go-www/src/github.com/didi/nightingale/n9e-judge
0.4 4.1 /home/go-www/src/github.com/didi/nightingale/n9e-collector
open-falcon :( 虚拟机 centos 1cpu 2G)
cpu mem module
0.0 0.5 /home/work/open-falcon/graph/bin/falcon-graph
0.0 0.5 /home/work/open-falcon/hbs/bin/falcon-hbs
0.0 0.5 /home/work/open-falcon/judge/bin/falcon-judge
0.2 0.4 /home/work/open-falcon/transfer/bin/falcon-transfer
0.0 0.5 /home/work/open-falcon/nodata/bin/falcon-nodata
0.0 0.6 /home/work/open-falcon/aggregator/bin/falcon-aggregator
0.0 0.6 /home/work/open-falcon/agent/bin/falcon-agent
0.2 0.4 /home/work/open-falcon/gateway/bin/falcon-gateway
0.0 0.6 /home/work/open-falcon/api/bin/falcon-api
0.2 0.5 /home/work/open-falcon/alarm/bin/falcon-alarm
4.4、其他对比
# 数据查询
> nightinge 采用TSDB + mysql 存储方式,TSDB 会保存近几个小时的数据,在查询时这段时间内的数据查询会很快,当然也会占用到一定的内存(nightingale原文:tsdb是分片的,tsdb来做缓存的话,只需要缓存自己分片的数据,内存占用较少)
> open falcon 查询数据主要存在在MySQL中,依靠索引查询,速度相对较慢。
# 活跃度对比
> 从github 上的start fork 和contributors 数 nightingale都远少于 open-falcon
> nightingale 开源时间短 ,但关注度正成迅猛上升趋势,相较于open-falcon 的关注度 2015-2018 这段时间是其高峰
4.5、开发难度
> nightinagle 模块少,流程清晰,易于理解。
> 二次开发的API接口 nightingale 要远远少于 open-falcon, 即nightingale 提供的功能要少于open-falcon,相应的也减少了对其他功能关注
> 百度搜索 open-falcon相关的资料明显多于nightingale。 个人推测在遇到开发难题时,open-falcon可参考的资料较多
> 两个都是采用go语言编写
4.6 结论
个人推荐使用 nightingale,理由如下:
> 查询速度更快,TSDB 保存了近几个小时的数据。
> 内容相对简单,流程清晰。
> 整体上延续了open-falcon,但又做了很多的改进。例如改变了原来gragh的数据存贮方式;将原有的 hbs,alerm,dashboard 组合为一个模块(monapi).
> 开源时间较短,但是发展迅猛
> nightingale 与 open falcon的插件可以复用,api的数量较少, 复杂度不高,开发应较为容易一些
> nightingale 和 open-falcon 都可以满足我们除安全审计外的需求
以上是关于关于open falcon 与nightingale 的一些调研的主要内容,如果未能解决你的问题,请参考以下文章