当Elasticsearch进行文档索引时,它是怎样工作的?
Posted elasticsearchalgolia
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了当Elasticsearch进行文档索引时,它是怎样工作的?相关的知识,希望对你有一定的参考价值。
我的Elasticsearch系列文章,逐渐更新中,欢迎关注
0A.关于Elasticsearch及实例应用
00.Solr与ElasticSearch对比
01.ElasticSearch能做什么?
02.Elastic Stack功能介绍
03.如何安装与设置Elasticsearch API
04.如果通过elasticsearch的head插件建立索引_CRUD操作
05.Elasticsearch多个实例和head plugin使用介绍
06.当Elasticsearch进行文档索引时,它是怎样工作的?
另外对于入门小白,我强烈推荐这篇Elasticsearch教程小白指南给你,小白会碰到的坑,这里都已经写了答案。
从这个博客中,我们进入该博客系列的阶段02,名为“索引,分析和映射”。在此阶段中,您将详细了解文档索引编制过程以及文档索引编制过程中的内部过程,例如分析,映射等。这个简短的博客第02期系列将向您介绍发生以下情况时的一般过程:在Elasticsearch中为文档建立索引。
索引文件及其他
让我们将如下所示的文档索引到Elasticsearch
curl -XPUT localhost:9200/testindex0201/testtype/1 -d ‘{
“name”: “Arun Mohan”,
“age”: 31
}’
现在,我们可以开始使用头插件了(这里有更多关于头插件的信息),并以索引名称“ testindex0201”查看索引文件。因此,我们很快就在Elasticsearch中为文档建立了索引,但是与此简单的过程有关的问题很多。其中一些问题是:
-
我刚刚创建的文档在磁盘上的哪个位置?
-
如果它位于磁盘上,我可以更改位置吗?
-
Elasticsearch是按原样存储数据还是在索引过程中对其进行修改?
-
在Elasticsearch中如何更快地搜索文档?
让我们在接下来的部分中看到这些问题的答案。
1.文档在磁盘中的什么位置存储?
在此博客中,我们讨论的是elasticsearch的.deb文件安装。elasticsearch的默认数据路径是文件夹“ / var / lib / elasticsearch /”。这里要注意的一点是,在版本5.x之前,在上述路径下,创建了该节点所属的群集名称中的文件夹并将数据存储在其中。从5.x开始不推荐使用,并且不存储任何群集名称。因此,实际上,5.x及其之前版本的数据路径如下所示:

2.更改数据位置
我们已经看到了Elasticsearch在磁盘中存储数据的位置。这带来了一个基本问题,即我们是否可以更改数据的位置?在诸如包含较少存储空间的数据的默认路径之类的情况下,需要进行此类自定义,因此我们决定专门为数据存储安装另一个卷。
Elasticsearch绝对提供了用于定制数据路径的选项。可以在位于以下位置的elasticsearch.yml文件中配置数据路径
/etc/elasticsearch/elasticsearch.yml
在此,自定义路径将应用于“ path.data”字段。
3.数据索引过程
下图显示了Elasticsearch中数据索引过程的高级流程。

从上图可以看到,该文档未在Elasticsearch中进行索引,而是由Analyzer组件对其执行一些操作并将其拆分为标记/术语。然后将这些术语作为反向索引存储在磁盘中。因此,让我们简要介绍一下上图中的分析器部分(我们将在下一个博客中详细介绍分析器)。
要开始使用Analyzers,最好对输入文档的外观和外观进行一些简要回顾。文档是具有自己的一组键值对的JSON对象。在上面给出的示例中,我们有两个名为“ name”和“ age”的键,它们的值也是如此。因此,当要将文档索引到Elasticsearch时,Elasticsearch的Analyzers部分将获取每个键,并以某些定界符(有默认定界符,例如空格,句号等)将它们分割开。此拆分的输出称为令牌。然后,对每个令牌应用特定的过滤器(标准过滤过程包括所有拆分令牌的下半部分)。因此,有效地,分析器完成分析后,密钥由一系列令牌组成。经过分析的这些标记称为术语。然后将这些术语针对该字段(键)存储在反向索引中。
4. Elasticsearch速度和倒排索引
如上一节所述,分析器生成的“术语”被发送到反向索引。现在该详细介绍一下“倒排索引”这个术语。
反向索引是Elasticsearch搜索的鲁棒性和速度的主要原因。最好用示例进行解释。考虑下面有两个文档:
Document 1
{
“name” : “this is a cat”
}
Document 2
{
“name”: “there is a cat and a dog”
}
经过分析,文件中的术语如下
Document 1
Field Terms
“name”: “this”,”is”,”a”,”cat”
document 2
Field Terms
“name” : “there”,”is”,”a”,”cat”,”and”,”dog”
现在,让我们结合以上两个用于“名称”字段的术语表,使其成为一个像下面这样的术语:
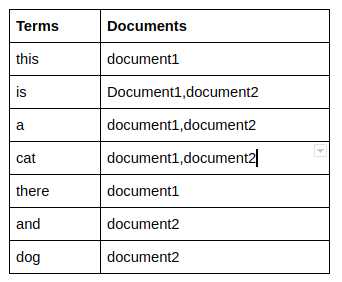
现在,上表称为“名称”字段的倒排索引。使用倒排索引的优势在于,可以在“术语”列中查找搜索词,然后,如果存在匹配项,则查找存在搜索词的文档非常简单。相应的列。例如,如果在这种情况下有100万个文档。在传统方法中,我们必须遍历每个文档以及每个字段的值以检索匹配的搜索结果。使用倒排索引,我们仅搜索一组选定的术语,然后由于没有术语的重复,如果找到匹配项,我们将在“文档”列中查找哪些文档中包含这些术语,然后将这些文档作为结果。因此,与传统方法相比,节省了大量的搜索时间。
如果数据集包含n个文档,并且这些文档中的字段数为m,则为该数据集生成的倒排索引总数等于n * m。
通过避免使用常见的停用词(如“ the”,“ is”等),从而进一步优化了每个倒排索引,从而创建了非常短的术语列表。这使搜索超级快。
结论
在此博客中,我简要介绍了Elasticsearch中的索引编制过程。现在,在第二阶段系列的下一个博客中,我们将更深入地研究Elasticsearch中的分析过程。我们将通过实际示例了解分析器的组件,分析器和令牌生成器的类型以及更多内容。
以上是关于当Elasticsearch进行文档索引时,它是怎样工作的?的主要内容,如果未能解决你的问题,请参考以下文章
Elasticsearch:使用 pipelines 路由文档到想要的 Elasticsearch 索引中去