爬虫-根据公司名抓取相关员工的linkedin数据
Posted 九茶
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了爬虫-根据公司名抓取相关员工的linkedin数据相关的知识,希望对你有一定的参考价值。
前言:
几个月前,应朋友要求,写了一个linkedin爬虫,难度不大,但功能还算好玩,所以就整理了一下放出来了。代码见Github:LinkedinSpider。
爬虫功能:输入一个公司名称,抓取相关员工的linkedin数据,字段见下方截图。
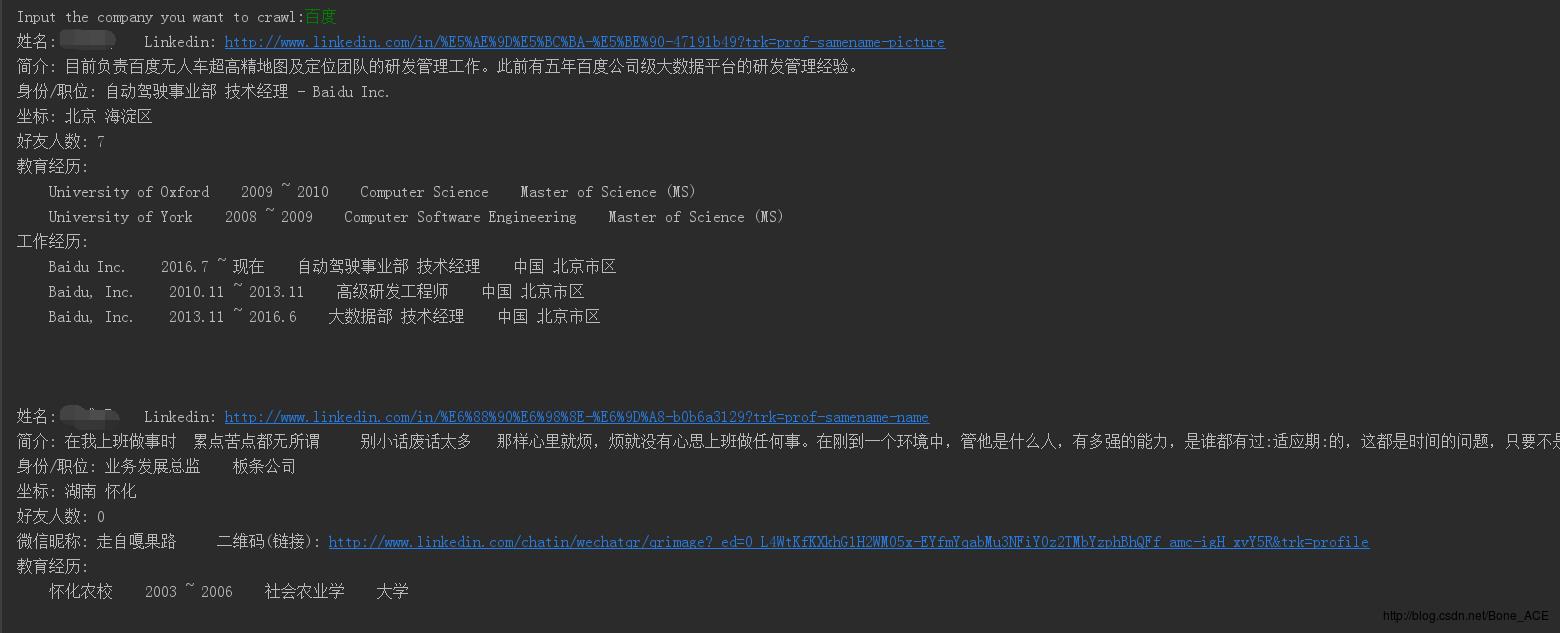
正文:
先来说一下linkedin的限制:
- 不登录的状态,不能进行搜索,但是可以查看某个用户的linkedin信息(不够全)。
- linkedin可以搜用户(最多显示100页),也可以搜公司,但不能查看公司下面的员工信息(显示的是“领英会员”,没有权限查看详细内容,要求先建立联系,如下图,可能开通linkedin高级账号可以查看,未知)。
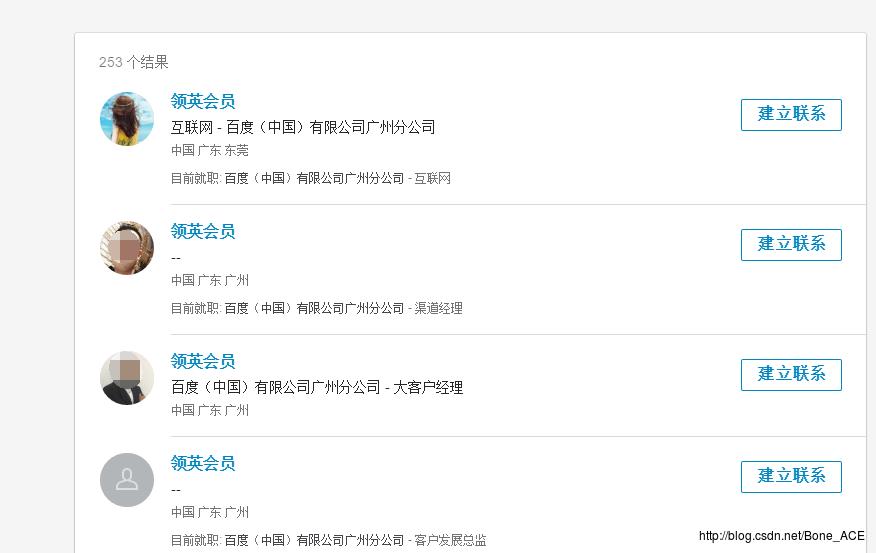
那么如果要抓取某个公司员工的linkedin信息,该怎么做?
方法一、银子多,开通高级账号也许可以查看。
方法二、去搜linkedin用户,尽量抓取全量的linkedin用户,从中筛选出某公司的员工。(难度在于如何搜用户,并且因为页数限制,几乎无法抓取全量)。
方法三、借助第三方平台。暂时未发现哪些网站有用到linkedin的数据,但是灵机一动想到了百度收录!我们用百度搜索,搜某个公司名,域名要求linkedin.com(例如抓取对象为百度,可以在百度搜索中搜 “百度 site:linkedin.com”),从中筛选出linkedin用户ID,有了用户ID我们就可以直接去linkedin抓员工信息了。
我们现在用的就是方法三。说一下爬虫流程:
先登录linkedin,带着linkedin的Cookie进行百度搜索,从中筛选出linkedin用户的(跳转到linkedin的)跳转链接,然后抓取、解析。
注意:为了抓取到最新的数据,一般不直接抓取百度收录到的内容,只是通过百度收录抓取到用户ID;另外,要待着linkedin的Cookie去打开搜索出来的链接,不然会跳转到linkedin登录页面,或者抓取到的信息不全。
结语:
代码放在Github,链接上文有提。此文主要作注释说明。
这只是一个小爬虫,我想要分享的,不仅仅是linkedin的登录、linkedin数据的抓取和解析,更重要的,是通过百度收录抓取目标数据这个方法。
对于做爬虫,或者是想学爬虫的同学来说,路子一定要宽,只要能够保证数据准确、完整,应该从各个途径去嗅探、抓取数据,抓取难度越小、速度越快,就越好!
转载请注明出处,谢谢!(原文链接:http://blog.csdn.net/bone_ace/article/details/71055153)
以上是关于爬虫-根据公司名抓取相关员工的linkedin数据的主要内容,如果未能解决你的问题,请参考以下文章