文本提取分析和修改工具
Posted hongjinping
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了文本提取分析和修改工具相关的知识,希望对你有一定的参考价值。
一、提取文本工具:
1.文件内容:less和cat
less通过n/N进行查找到搜索的内容
2.文本摘要:head和tail
head使用-n显示头部行数
tail也可以使用-n显示尾部行数,具体用法如下:#cat test.txt | tail -n3或者#cat test.txt | heal -n4
可以用来截取某个文件里面第五行之后的7行内容如:#cat test.xtx | head -n 11 | tail -n 7
3.通过列提取:cut
4.通过关键字提取:grep
打印出模式匹配到的文件或者标准输入行
$grep ‘john‘ /etc/passwd
$date --help | grep year
。使用-i查询时不区分大小写
。使用-n打印匹配到的行号
。使用-v打印不包含匹配模式的行
。使用-AX包括在每次匹配之后X行
。Use -BX包括每次匹配之前X行
使用vim可以指定打开对应文件的行号,如:vim +34 /etc/passwd 进入/etc/passwd文件中的第34行
如过滤文件中配置有效的文件,即取出空行和#的行,如下:#cat test.txt | grep ^# -v | grep -v ^$等同于命令:
#cat test.txt | grep -Ev ‘^(#|$)‘=#cat test.txt | grep -Ev ‘(^#|^$)‘。
以下图片为修改文件的操作:

通过列提出文本cut
显示文件指定的列或者标准输入的数据
.$cut -d :-f1 /etc/passwd //提取/etc/passwd 文件中分隔符按照":“,第一个字段的内容
.$grep root /etc/passwd | cut -d:-f7
使用-d指定列的分隔符(默认为TAB)
使用-f指定要打印的列
使用-c按字符切分
.cut -c2-5 /usr/share/dict/words
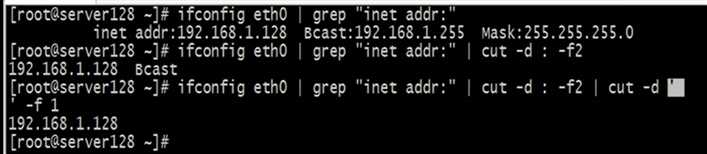
eg:通过以下方式获取网卡里面的ip地址:
eg:通过以下方式获取字符串中5-12为字符:

排序文本sort
.排序文本到标准输出-未修改源文件
.$sort [options] file(s)
.命令选项
。-r执行反响(降序)排序
。-n按数字执行排序
。-f忽略字符串中的大小写
。-u(唯一)移除输出中重复的行
。-t c使用c作为字符分隔符
。-k X对字段X排序
。能使用多次
eg:使用sort命令对/etc/passwd文件第三列进行排序:
#cat /etc/passwd | sort -t : -k 3 -n
去除重复的行:sort和uniq
sort -u:从输入中移除重复的行
uniq:从输入中移除重复相邻行
.使用-c来统计重复的次数
.最好与sort一起使用:$sort userlist.txt | uniq -c (先排序然后使用uniq统计次数)
分析文本的工具:
.文本统计:wc
收集文本统计信息wc(单词统计)
。统计单词,行,字节和字符
。能使用在一个文件后者标准输入上
。$cat /etc/passwd | wc [-w|-l|-c]
。使用-l作为行数统计
。使用-w作为单词统计
。使用-c作为字节统计
。使用-m作为字符统计(不显示)
.文本排序:sort
.对比文件:diff和patch
对比两个文件找出差异$diff foo.conf-broken foo.conf-works(对比结果<箭头是foo.con-broken,>箭头是foo.conf-works文件内容,其中6c6中c表示被修改了5d4
复制文件所做的改变patch
diff输出保存到一个文件里,称呼其为“补丁文件”
。使用-u作为“统一”格式的diff,适用于补丁文件
patch复制所做的改变到其他文件中(小心使用!)
。使用-b自动备份欲改变的文件
$diff -u foo.conf-broken foo.conf-works >foo.patch //比较foo.conf-broken(v1.0版本)与foo.conf-works(v2.0版本)对比,将结果重定向到foo.patch中
$patch -b foo.conf-broken <foo.patch //将补丁包foo.patch文件写入到foo.conf-broken文件中,实现版本v1.0到2.0升级,之后可以比对foo.conf-broken和foo.conf-works发现此时两个文件内容已经相同
.拼写检查:aspell
操作文本的工具tr和sed:
.修改(转换)字符:tr 。将一些列字符转化成对应的另外一系列字符 。只从标准输入中读取数据 $tr ‘a-z‘ ‘A-Z‘ <lowercase.txt .修改字符串:sed 。流编辑器 。对文本流做查询/替换操作 。通常不会修改原文件 。使用-i.bak来备份并修改原文件
实例:
。用引号括起查询和替换指令!
。sed寻址:
#sed ‘s/dog/cat/g‘ pets
#sed ‘1,50s/dog/cat/g‘ pets
#sed ‘/digby/,/duncan/s/dog/cat/g‘ pets
。多个sed指令
sed -e ‘s/dog/cat/‘ -e ‘s/hi/lo/‘ pets
sed -f myedits pets //这里-f是调用已经写好替换规则的myedits的文件,pets是需要使用该规则的文件名
sed格式(下面的/、#、@为分界定位符): sed ‘s/查找内容1 /替换内容2/‘用于没有/的替换
sed ‘s# # #‘
sed ‘s@ @ @‘
sed修饰符:g(global)全局;i(case-insensitive)无视大小写;d(delete)
区间替换:sed m,n s/ / / //使用m,n,m为起始位置,n为结束为止,来实现区间查找替换。
#cat ./iptables.lst | sed ‘87,93s/172.24./10.0./‘ //将iptables.lst文件中数字87到93的区间内容为172.24.替换为10.0.
#cat animal.txt | sed ‘/cat/,/dog/s/$/ <----/‘ 猫狗游戏,在animal.txt文件中找到猫,知道找到狗这个区间的$结尾符号替换成<----,其他不替换。
-e开关可以讲多个表达式合并起来,实现多个替换。
以上命令中的方法有多个替换语句,可以使用-f参数文件来实现,调用的时候使用sed -f 被调用的文件
以上是关于文本提取分析和修改工具的主要内容,如果未能解决你的问题,请参考以下文章