exp/expdp 与 imp/impdp命令导入导出数据库详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了exp/expdp 与 imp/impdp命令导入导出数据库详解相关的知识,希望对你有一定的参考价值。
一、exp命令导出数据库
如何使exp的帮助以不同的字符集显示:set nls_lang=simplified chinese_china.zhs16gbk,通过设置环境变量,可以让exp的帮助以中文显示,如果set nls_lang=American_america.字符集,那么帮助就是英文的了。
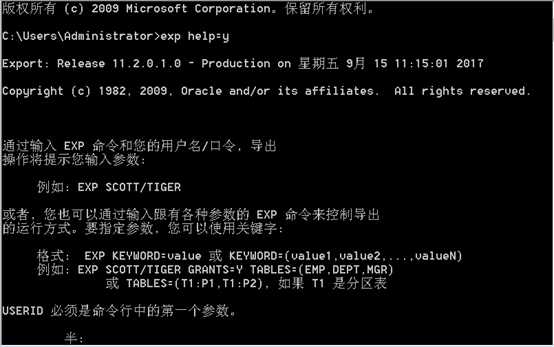
参数:
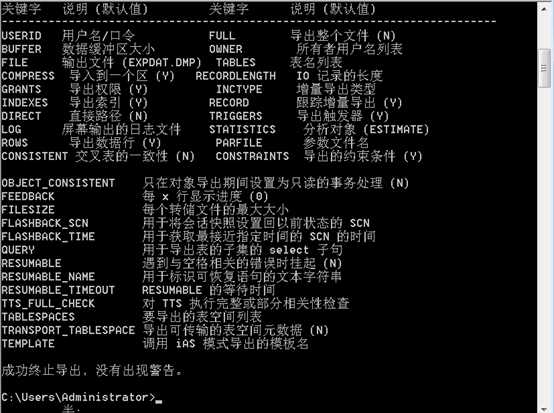
1.1 导出用户全部数据
exp 登录名称/用户密码@服务命名 FILE=文件存储的路径以及名称 log=日志存储的路径以及名称 FULL=Y(表示导出全部数据,如视图、索引关联关系等等全部的东西)
exp hlsoa/[email protected] file=E:\\test\\file log=E:\\test\\log full=y 这是导出本地数据库
如果要是导出远程数据库需要修改tnsnames.ora 在连接字符串中将HOST改为远程数据库地址也可以直接通过服务器地址加服务命名解决
exp hlsoa/[email protected]/orcl file=E:\\test\\file log=E:\\test\\log full=y
注意:在test文件夹下可以新建file.dmp、log.log文件也可以不建,系统会自动创建。上面命令中可以加文件后缀,也可以不加。但是test这个文件夹必须要存在。
1.2导出数据库结构而不导出数据
exp 登录名称/用户密码@服务命名 file=文件存储的路径以及名称 log=日志存储的路径以及名称 full=y rows=n(不导出行数据)
exp hlsoa/[email protected] file=E:\\test\\file log=E:\\test\\log full=y rows=n
1.3导出一个或者多个指定表
exp 登录名称/用户密码@服务命名 file=文件存储的路径以及名称 log=日志存储的路径以及名称 tables=表名字
exp 登录名称/用户密码@服务命名 file=文件存储的路径以及名称 log=日志存储的路径以及名称 tables=(表1,表2,表3,表N)
1.4 导出某个用户所拥有的数据库表
exp 用户名/密码@服务命名 file=存放位置\\存放文件名.dmp log=存放位置\\存放文件名.log owner=拥有者用户名
exp hlsoa/[email protected] file=E:\\test\\file log=E:\\test\\log owner=(hlsoa)
1.5 用多个文件分割一个导出文件
exp system/manager file=(paycheck_1,paycheck_2,paycheck_3,paycheck_4) log=paycheck, filesize=1G tables=hr.paycheck
1.6使用参数文件导出数据
exp system/[email protected]服务命名 parfile=bible_tables.par
bible_tables.par(参数示例文件):
#Export the sample tables used for the Oracle8i Database Administrator‘s Bible.
file=bible_tables(文件存储的路径以及名称)
log=bible_tables(日志存储的路径以及名称)
tables=(
amy.artist
amy.books
seapark.checkup
seapark.items
)
1.7 增量导出数据
--“完全”增量导出(complete),即备份整个数据库
exp system/[email protected]服务命名 inctype=complete file=990702.dmp
--“增量型”增量导出(incremental),即备份上一次备份后改变的数据
exp system/[email protected]服务命名 inctype=incremental file=990702.dmp
--“累计型”增量导出(cumulative),即备份上一次“完全”导出之后改变的数据
exp system/[email protected]服务命名 inctype=cumulative file=990702.dmp
导出某个用户所拥有的数据库表:
exp 用户名/密码@服务命名 file=存放位置\\存放文件名.dmp log=存放位置\\存放文件名.log owner=拥有者用户名
1.8估计导出文件的大小
--整个数据库全部表总字节数:
SELECT sum(bytes)/1024/1024/1024 "占用空间:单位GB"
FROM dba_segments
WHERE segment_type = ‘TABLE‘;
--指定用户所属表的总字节数:
SELECT sum(bytes)
FROM dba_segments
WHERE owner = ‘SEAPARK‘
AND segment_type = ‘TABLE‘;
seapark用户下的aquatic_animal表的字节数:
SELECT sum(bytes)
FROM dba_segments
WHERE owner = ‘SEAPARK‘
AND segment_type = ‘TABLE‘
AND segment_name = ‘AQUATIC_ANIMAL‘
二、imp 命令导入数据库
参数:
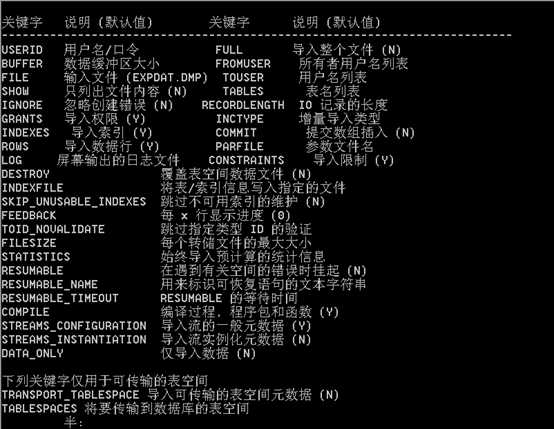
2.1 导入一个完整数据库
imp 登录名称/用户密码@服务命名 FILE=数据文件存储的路径以及名称 log=日志存储的路径以及名称 FULL=Y IGNORE=y(因为有的表已经存在,然后它就报错,对该表就不进行导入,然后忽略该报错)
imp system/manager file=bible_db log=dible_db full=y ignore=y
2.2导入一个或一组指定用户所属的全部表、索引和其他对象
imp system/manager file=seapark log=seapark fromuser=seapark
imp system/manager file=seapark log=seapark fromuser=(seapark,amy,amyc,harold)
2.3 将一个用户所属的数据导入另一个用户
imp system/manager file=tank log=tank fromuser=seapark touser=seapark_copy
imp system/manager file=tank log=tank fromuser=(seapark,amy) touser=(seapark1, amy1)
2.4 导入一个或者多个表
imp system/manager file=tank log=tank fromuser=seapark TABLES=(a,b)
2.5 从多个文件导入
imp system/manager file=(paycheck_1,paycheck_2,paycheck_3,paycheck_4) log=paycheck, filesize=1G full=y
2.6 使用参数文件
imp system/manager parfile=bible_tables.par
bible_tables.par参数文件:
#Import the sample tables used for the Oracle8i Database Administrator‘s
Bible. fromuser=seapark touser=seapark_copy file=seapark log=seapark_import
2.7 增量导入
imp system./manager inctype= RECTORE FULL=Y FILE=A
三、expdp命令导出数据库
3.1 参数介绍
|
序号 |
关键字 |
说明 (默认) |
|
01 |
ATTACH |
连接到现有作业, 例如 ATTACH [=作业名]。 |
|
02 |
COMPRESSION |
减小有效的转储文件内容的大小关键字值为: (METADATA_ONLY) 和 NONE。 |
|
03 |
CONTENT |
指定要卸载的数据, 其中有效关键字为:(ALL),DATA_ONLY 和 METADATA_ONLY。 |
|
04 |
DIRECTORY |
供转储文件和日志文件使用的目录对象。 |
|
05 |
DUMPFILE |
目标转储文件 (expdat.dmp) 的列表,例如 DUMPFILE=scott1.dmp, scott2.dmp, dmpdir:scott3.dmp。 |
|
06 |
ENCRYPTION_PASSWORD |
用于创建加密列数据的口令关键字。 |
|
07 |
ESTIMATE |
计算作业估计值, 其中有效关键字为: (BLOCKS) 和 STATISTICS。 |
|
08 |
ESTIMATE_ONLY |
在不执行导出的情况下计算作业估计值。 |
|
09 |
EXCLUDE |
排除特定的对象类型, 例如 EXCLUDE=TABLE:EMP。 |
|
10 |
FILESIZE |
以字节为单位指定每个转储文件的大小。 |
|
11 |
FLASHBACK_SCN |
用于将会话快照设置回以前状态的 SCN。 |
|
12 |
FLASHBACK_TIME |
用于获取最接近指定时间的 SCN 的时间。 |
|
13 |
FULL |
导出整个数据库 (N)。 |
|
14 |
HELP |
显示帮助消息 (N)。 |
|
15 |
INCLUDE |
包括特定的对象类型, 例如 INCLUDE=TABLE_DATA。 |
|
16 |
JOB_NAME |
要创建的导出作业的名称。 |
|
17 |
LOGFILE |
日志文件名 (export.log)。 |
|
18 |
NETWORK_LINK |
链接到源系统的远程数据库的名称。 |
|
19 |
NOLOGFILE |
不写入日志文件 (N)。 |
|
20 |
PARALLEL |
更改当前作业的活动 worker 的数目。 |
|
21 |
PARFILE |
指定参数文件。 |
|
22 |
QUERY |
用于导出表的子集的谓词子句。 |
|
23 |
SAMPLE |
要导出的数据的百分比; |
|
24 |
SCHEMAS |
要导出的方案的列表 (登录方案)。 |
|
25 |
STATUS |
在默认值 (0) 将显示可用时的新状态的情况下, 要监视的频率 (以秒计) 作业状态。 |
|
27 |
TABLES |
标识要导出的表的列表 - 只有一个方案。 |
|
28 |
TABLESPACES |
标识要导出的表空间的列表。 |
|
29 |
TRANSPORT_FULL_CHECK |
验证所有表的存储段 (N)。 |
|
30 |
TRANSPORT_TABLESPACES |
要从中卸载元数据的表空间的列表。 |
|
31 |
VERSION |
要导出的对象的版本, 其中有效关键字为: (COMPATIBLE), LATEST 或任何有效的数据库版本。 |
|
32 |
ADD_FILE |
向转储文件集中添加转储文件。 |
|
33 |
CONTINUE_CLIENT |
返回到记录模式。如果处于空闲状态, 将重新启动作业。 |
|
35 |
EXIT_CLIENT |
退出客户机会话并使作业处于运行状态。 |
|
36 |
FILESIZE |
后续 ADD_FILE 命令的默认文件大小 (字节)。 |
|
37 |
HELP |
总结交互命令。 |
|
38 |
KILL_JOB |
分离和删除作业。 |
|
39 |
PARALLEL |
更改当前作业的活动 worker 的数目。 PARALLEL=<worker 的数目>。 |
|
40 |
START_JOB |
启动/恢复当前作业。 |
|
41 |
STATUS |
在默认值 (0) 将显示可用时的新状态的情况下, 要监视的频率 (以秒计) 作业状态。 STATUS[=interval] |
|
42 |
STOP_JOB |
顺序关闭执行的作业并退出客户机。 STOP_JOB=IMMEDIATE 将立即关闭 数据泵作业。 |
3.1.1参数:schemas
导出orcldev这个schema的所用对象[schemas or full]
eg:expdp orcldev/[email protected] directory=backup_path dumpfile=orcldev_schema.dmp logfile=orcldev_schema_2017.log schemas=orcldev
3.1.2参数:tables
导出orcldev这个用户下的某些表[tables]
eg:C:\\>expdp orcldev/oracle directory=dackup_path dumpfile=orcldev_table.dmp logfile=orcldev_table_2017.log tables=(‘TAB_TEST‘,‘TAB_A‘)
3.1.3参数:content
只导出orcldev这个用户的元数据[content]
eg:C:\\>expdp orcldev/oracle directory=dackup_pathdumpfile=orcldev_meta.dmp logfile=orcldev_meta_2017.log SCHEMAS=orcldev CONTENT=METADATA_ONLY
3.1.4参数:sample
只导出orcldev这个用户50%的抽样数据[sample]
eg:C:\\>expdp orcldev/oracle directory=dackup_pathdumpfile=orcldev_samp.dmp logfile=orcldev_samp_2017.log schemas=orcldevsample=50
3.1.5参数:exclude
导出orcldev这个方案对象,但不包含索引[exclude]
eg: --可以剔除的对象有:VIEW,PACKAGE,FUNCTION,index,constraints,table,schema,user等等
C:\\>expdp orcldev/oracle directory=dackup_path dumpfile=orcldev_exclude.dmp logfile=orcldev_exclude.log SCHEMAS=orcldev EXCLUDE=index
C:\\>expdp orcldev/oracle directory=dackup_path dumpfile=orcldev_exclude.dmp logfile=orcldev_exclude.log SCHEMAS=orcldev EXCLUDE=INDEX:"LIKE ‘TEST%‘" --导出这个orcldev方案,剔除以TEST开头的索引
C:\\>expdp orcldev/oracle directory=dackup_path dumpfile=orcldev_exclude.dmp logfile=orcldev_exclude.log EXCLUDE=SCHEMA:"=‘SCOTT‘"
C:\\>expdp orcldev/oracle directory=dackup_path dumpfile=orcldev_exclude.dmp logfile=orcldev_exclude.log EXCLUDE=USER:"=‘SCOTT‘"
--备份整库但剔除SCOTT这个用户的对象。
注意:include与exclude不能同时使用。
3.1.6参数:PARFILE
expdp命令可以调用parfile文件,在parfile里可以写备份脚本,可以使用query选项。
如expdp.txt内容如下:
USERID=orcldev/oracle directory=dackup_path dumpfile=orcldev_parfile.dmp logfile=orcldev_parfile.log TABLES=‘TAB_TEST‘ QUERY="WHERE TRAN_DATE=TO_DATE(‘2017-09-15‘,‘YYYY-MM-DD‘)"
执行方法:expdp parfile=expdp.txt 即可执行备份
使用parfile好处是使用query选项是不用使用转义字符,如果将query参数放到外边的话,需要将""进行转义。
eg:
UNIX写法:
expdp orcldev/oracle directory=backup_path dumpfile=2017.dmp logfile=2017.log schemas=orcldev INCLUDE=TABLE:\\"IN\\‘TESTA\\‘,\\‘TESTB\\‘\\" --在Unix系统执行是需要将单引号进行转义操作,否则会报错。
WINDOWS写法:
expdp orcldev/oracle directory=backup_path dumpfile=2017.dmp logfile=2017.log schemas=orcldev INCLUDE=TABLE:"IN \\(‘TEST_A‘,‘TEST_B‘)"
3.1.7参数:TABLESPACE
TABLESPACE导出表空间
eg:expdp orcldev/oracle directory=backup_path dumpfile=2017.dmplogfile =2017.log tablespaces=user,orcldev
3.1.8参数:Version
VERSION选项默认值是COMPATIBLE,即兼容模式。在我们备份的时候,可以指定版本号。
eg:expdp orcldev/oracle directory=backup_path dumpfile=2017.dmplogfile =2017.log full=Y VERSION=10.2.0.4
3.1.9参数:FLASHBACK_TIME
指定导出特定时间点的表数据,可以联系一下FLASHBACK功能。
eg:C:\\>expdp orcldev/oracle directory=dackup_path dumpfile=orcldev_flash.dmp logfile=orcldev_flash.log SCHEMAS=orcldev FLASHBACK_TIME="TO_TIMESTAMP(‘2017-09-15 14:30:00‘,‘DD-MM-YYYYHH24:MI:SS‘)"
3.2 准备工作
3.2.1 连接目标数据库,查看服务器端字符集
|
SQL> select userenv(‘language‘) from dual; USERENV(‘LANGUAGE‘) ---------------------------------------------------- SIMPLIFIED CHINESE_CHINA.ZHS16GBK SQL> |
3.2.2退出当前会话,设置客户端字符集使之与服务端字符集一致
|
SQL> exit 从 Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - 64bit Production With the Partitioning, OLAP, Data Mining and Real Application Testing options 断开 C:\\>SET NLS_LANG= SIMPLIFIED CHINESE_CHINA.ZHS16GBK
|
3.2.3 创建逻辑目录,并赋予Oracle对其的读写权限
使用EXPDP工具时,其转存储文件只能被存放在directory对象对应的OS目录中,而不能直接指定转存储文件所在的OS目录。在此,先在操作系统创建目录C:\\dump
以system等管理员身份登录sqlplus,授予用户test对目录对象dmp_dir的读写权限。
create directory dmp_dir as ‘C:\\dump‘
grant read, write on directory dmp_dir to hlsbi;
创建路径需要sys权限,需要有create any directory权限才可以创建路径。
选项:DIRECTORY=directory_object
Directory_object用于指定目录对象名称。需要注意,目录对象是使用CREATE DIRECTORY语句建立的对象,而不是OS目录。
3.3 导出方式
与exp命令不同,expdp如果需要导出远程数据库就要用dblink
是本地客户端直接修改tnsnams.ora文件在其中添加链接服务端字符串
EXPTEST =
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.88)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = ORCL)
)
)
然后直接在客户端数据库创建dblink进行链接
create public database link db10_rc connect to username identified by password using ‘connect_string‘;
注意:username和password是服务端的,并且特别注意该处的connect_string 就为tnsnames.ora中的服务名.或者直接使用‘=’号后面的字符串
create public database link db10_rc connect to username identified by password using ‘
(DESCRIPTION =
(ADDRESS_LIST =
(ADDRESS = (PROTOCOL = TCP)(HOST = 192.168.1.88)(PORT = 1521))
)
(CONNECT_DATA =
(SERVICE_NAME = ORCL)
)
) ’
在客户端创建文件夹,并给导出的用户授权。
create or replace directory dir as ‘directory‘;
grant read,write on directory dir to username;
这里的username是客户端的当前用户名,用于导出数据用的。
使用expdp导出远程的数据到本地。
expdp user/pass network_link=db10_rc directory=trans_dir dumpfile=test1.dmp schemas=hlsoa
//这里的username用创建dblink的那个用户,directory也是客户端数据库创建的。
也可以直接将远程的用户导入本地用户,跳过生成DUMPFILE(省了导出)这一步
SQL> impdp system/manager network_link=db10_rc directory=trans_dir tables=hlsoa.test remap_schema=hlsoa:hlsbi
3.3.1全库导出模式
expdp system/[email protected] directory=dmp_dir dumpfile=fulldb.dmp full=y version=10.2.0.1.0
expdp test/[email protected] directory=dmp_dir dumpfile=fulldb.dmp full=y (高版本数据库向低版本数据库)
3.3.2推荐 用户导出模式
Windows
|
expdp system/[email protected] ^ directory=dmp_dir ^ dumpfile=HLSHIS%DATE:~0,4%%DATE:~5,2%%DATE:~8,2%_%time:~0,2%%time:~3,2%.DMP ^ logfile=HLSHIS%DATE:~0,4%%DATE:~5,2%%DATE:~8,2%_%time:~0,2%%time:~3,2%.LOG ^ schemas=hisrun ^ parallel=4 |
linux
|
expdp system/[email protected] \\ directory=dmp_dir \\ dumpfile=HLSHIS$(date -d "today" +"%Y%m%d_%H%M%S").DMP \\ logfile=HLSHIS$(date -d "today" +"%Y%m%d_%H%M%S").LOG \\ schemas=hisrun \\ parallel=4 |
expdp test/[email protected] directory=dmp_dir dumpfile=userdum.dmp schemas=hgmmo
expdp system/[email protected] directory=dmp_dir dumpfile=emr.dmp schemas=wsemr
——导出单个用户数据(dumpfile指定dump文件名;schemas指定要被导出数据的用户)
expdp test/[email protected] directory=dmp_dir dumpfile=userdum.dmp schemas=hgmmo,hgmqo
——导出多个用户数据(用户之间用逗号隔开)
3.3.3表导出模式
expdp system/[email protected] directory=dmp_dir dumpfile=tabledum.dmp tables=test.emp, test.dept
——导出test用户的emp和dept两个表
expdp system/[email protected] directory=dmp_dir dumpfile=tabledum.dmp tables=test.emp query=‘WHERE deptno=20‘
——导出表中符合指定条件的数据,使用query条件的语句较长时采用parfile方式
3.3.4表空间导出模式
expdp system/[email protected] directory=dmp_dir dumpfile=dumptbs.dmp tablespaces=tbs1,tbs2
3.3.5可移动表空间导出模式(只导出表空间的元数据,不真正导出数据)
expdp system/[email protected] directory=dmp_dir dumpfile=dumptbs.dmp transport_tablespaces=tbs1
3.3.6采用并行方式备份整库[parallel]
parallel参数只有在oracle10g之后的版本(包含10g)有效。
oracle_online:you can use the DUMPFILE parameter during export operations tospecify multiple dump files, by using a substitution variable (%U) in thefilename. This is called a dump file template. The new dump files are createdas they are needed, beginning with 01 for %U, then using 02,03,and so on.
eg:C:\\>expdporcldev/oracle directory=dackup_path dumpfile=orcldev_parallel_%U.dmplogfile=orcldev_parallel_2013.log parallel=4
"%U"表示自动生成递增的序列号。
四、impdp命令导入数据库
4.1全库模式导入
impdp test/[email protected] directory=dmp_dir dumpfile=fulldb.dmp full=y
4.2用户模式导入
impdp test/[email protected] directory=dmp_dir dumpfile=userdum.dmp schemas=hgmmo
impdp test/[email protected] directory=dmp_dir dumpfile=userdum.dmp remap_schema=user1:user2
——remap_schema参数相当于imp工具中的fromuser和touser参数,可以实现将一个用户的数据导入到另一个用户中
4.3 表空间模式导入
impdp system/[email protected] directory=dmp_dir dumpfile=dumptbs.dmp tablespaces=tbs1
4.4 追加数据
impdp system/manager DIRECTORY=dpdata1 DUMPFILE=expdp.dmp SCHEMAS=system TABLE_EXISTS_ACTION=append
4.5 将高版本数据库数据导入到低版本数据库中
1.查询oracle版本信息
SQL>show parameter compatible
2.使用version参数导入导出数据
expdp test/[email protected] directory=dmp_dir dumpfile=userdum.dmp schemas=hgmmo version =11.2.0.0.0
impdp test/[email protected] directory=dmp_dir dumpfile=userdum.dmp schemas=hgmmo version =11.2.0.0.0
以上是关于exp/expdp 与 imp/impdp命令导入导出数据库详解的主要内容,如果未能解决你的问题,请参考以下文章