HashSet
Posted smartcat994
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashSet相关的知识,希望对你有一定的参考价值。
先上全家照!
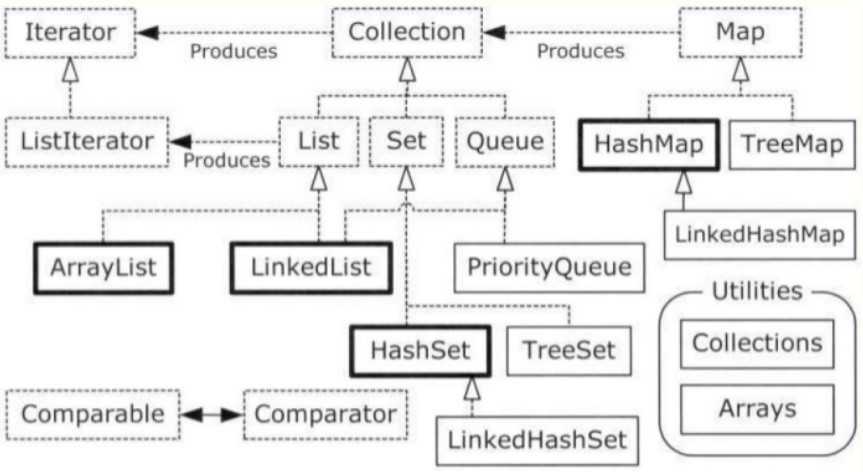
四个画着黑框的重点肯定要先看完。下面开始进入对HashSet的分析。
Javadoc:
此类实现Set 接口,并由哈希表(实际上是HashMap实例)支持。它不保证集合的迭代顺序。特别是,它不能保证阶随时间保持不变。此类允许null元素。
此类为基本操作提供了恒定的时间性能(添加,删除,包含和大小),假设哈希函数将元素正确分散在存储桶中。对此集合进行迭代需要的时间与 HashSet 实例的大小(元素的数量)加上后勤的 HashMap 实例的容量(数量)之和,成正比例。因此,如果迭代性能很重要,则不要将初始容量设置得过高(或负载因数过低),这一点非常重要。
请注意,此实现未同步。如果多个线程同时访问哈希集,并且线程中的至少一个修改了哈希集,则它必须在外部同步。 这通常是通过对某些自然封装了该对象的对象进行同步来完成的。
如果不存在此类对象,则应使用{{@link Collections#synchronizedSet Collections.synchronizedSet} 方法包装该集合。最好在创建时完成此操作,以防止意外异步访问集合:Set s = Collections.synchronizedSet(new HashSet(...));
此类的iterator 方法返回的迭代器为快速失败:如果在创建迭代器后的任何时间修改了集合,则除通过迭代器自己的remove方法,迭代器将引发{@link ConcurrentModificationException}。 因此,面对并发修改,迭代器将迅速干净地失败,而不是冒着将来不确定的时间冒任意,不确定的行为的风险。
请注意,不能保证迭代器的快速失败行为,因为通常来说,在存在不同步的并发修改的情况下,不可能做出任何严格的保证。快速失败的迭代器尽最大努力抛出ConcurrentModificationException 。 因此,编写依赖于此异常的程序是错误的:迭代器的快速失败行为仅应用于检测错误。
HashSet的继承图:
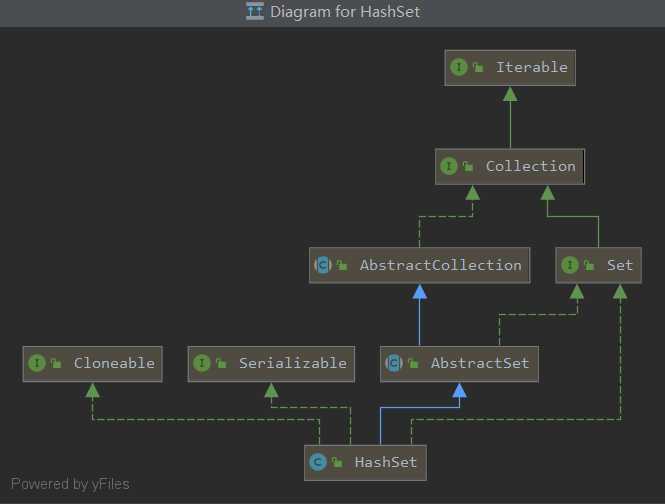
属性的接口,AbstractSet:是set类型的接口,实现了不重复。
源码分析
public class HashSet<E>
extends AbstractSet<E>
implements Set<E>, Cloneable, java.io.Serializable
{
//序列化和反序列化的标识
static final long serialVersionUID = -5024744406713321676L;
//对应了上面说的,HashSet其实是基于HashMap的实例(成员变量不参与序列化过程)
private transient HashMap<E,Object> map;
//定义一个虚拟的Object对象作为HashMap的value,将此对象定义为static final
private static final Object PRESENT = new Object();
//空参构造,出来的其实是个HashMap
public HashSet() {
map = new HashMap<>();
}
//带参数构造
public HashSet(Collection<? extends E> c) {
//实际底层会初始化一个空的HashMap,并使用默认初始容量为16和加载因子0.75
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
addAll(c);
}
//以指定的initialCapacity和loadFactor构造一个空的HashSet,其实还是HashMap
public HashSet(int initialCapacity, float loadFactor) {
map = new HashMap<>(initialCapacity, loadFactor);
}
//只有初始容量大小的构造方法
public HashSet(int initialCapacity) {
map = new HashMap<>(initialCapacity);
}
//以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。 此构造函数为包访问权限,不对外公开,实际只是是对LinkedHashSet的支持
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
map = new LinkedHashMap<>(initialCapacity, loadFactor);
}
//返回对此set中元素进行迭代的迭代器。返回元素的顺序并不是特定的。底层实际调用底层HashMap的keySet来返回所有的key
//可见HashSet中的元素,只是存放在了底层HashMap的key上
public Iterator<E> iterator() {
return map.keySet().iterator();
}
//底层实际调用HashMap的size()方法返回Entry的数量,就得到该Set中元素的个数。
public int size() {
return map.size();
}
public boolean isEmpty() {
return map.isEmpty();
}
//底层实际调用HashMap的containsKey判断是否包含指定key。
public boolean contains(Object o) {
return map.containsKey(o);
}
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
/**
* 如果此set中尚未包含指定元素,则添加指定元素。
* 更确切地讲,如果此 set 没有包含满足(e==null ? e2==null : e.equals(e2))
* 的元素e2,则向此set 添加指定的元素e。
* 如果此set已包含该元素,则该调用不更改set并返回false。
* 底层实际将将该元素作为key放入HashMap。
* 由于HashMap的put()方法添加key-value对时,当新放入HashMap的Entry中key
* 与集合中原有Entry的key相同(hashCode()返回值相等,通过equals比较也返回true),
* 新添加的Entry的value会将覆盖原来Entry的value,但key不会有任何改变,
* 因此如果向HashSet中添加一个已经存在的元素时,新添加的集合元素将不会被放入HashMap中,
* 原来的元素也不会有任何改变,这也就满足了Set中元素不重复的特性。
* @param e 将添加到此set中的元素。
* @return 如果此set尚未包含指定元素,则返回true。
*/
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}
public void clear() {
map.clear();
}
//去除警告,克隆
@SuppressWarnings("unchecked")
public Object clone() {
try {
HashSet<E> newSet = (HashSet<E>) super.clone();
newSet.map = (HashMap<E, Object>) map.clone();
return newSet;
} catch (CloneNotSupportedException e) {
throw new InternalError(e);
}
}
private void writeObject(java.io.ObjectOutputStream s)
throws java.io.IOException {
s.defaultWriteObject();
s.writeInt(map.capacity());
s.writeFloat(map.loadFactor());
s.writeInt(map.size());
for (E e : map.keySet())
s.writeObject(e);
}
private void readObject(java.io.ObjectInputStream s)
throws java.io.IOException, ClassNotFoundException {
s.defaultReadObject();
int capacity = s.readInt();
if (capacity < 0) {
throw new InvalidObjectException("Illegal capacity: " +
capacity);
}
float loadFactor = s.readFloat();
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
throw new InvalidObjectException("Illegal load factor: " +
loadFactor);
}
int size = s.readInt();
if (size < 0) {
throw new InvalidObjectException("Illegal size: " +
size);
}
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
HashMap.MAXIMUM_CAPACITY);
SharedSecrets.getJavaOISAccess()
.checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity));
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
new LinkedHashMap<E,Object>(capacity, loadFactor) :
new HashMap<E,Object>(capacity, loadFactor));
for (int i=0; i<size; i++) {
@SuppressWarnings("unchecked")
E e = (E) s.readObject();
map.put(e, PRESENT);
}
}
public Spliterator<E> spliterator() {
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
}
}
x
99
100
1
public class HashSet<E>
2
extends AbstractSet<E>
3
implements Set<E>, Cloneable, java.io.Serializable
4
{
5
//序列化和反序列化的标识
6
static final long serialVersionUID = -5024744406713321676L;
7
//对应了上面说的,HashSet其实是基于HashMap的实例(成员变量不参与序列化过程)
8
private transient HashMap<E,Object> map;
9
//定义一个虚拟的Object对象作为HashMap的value,将此对象定义为static final
10
private static final Object PRESENT = new Object();
11
//空参构造,出来的其实是个HashMap
12
public HashSet() {
13
map = new HashMap<>();
14
}
15
//带参数构造
16
public HashSet(Collection<? extends E> c) {
17
//实际底层会初始化一个空的HashMap,并使用默认初始容量为16和加载因子0.75
18
map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16));
19
addAll(c);
20
}
21
//以指定的initialCapacity和loadFactor构造一个空的HashSet,其实还是HashMap
22
public HashSet(int initialCapacity, float loadFactor) {
23
map = new HashMap<>(initialCapacity, loadFactor);
24
}
25
//只有初始容量大小的构造方法
26
public HashSet(int initialCapacity) {
27
map = new HashMap<>(initialCapacity);
28
}
29
//以指定的initialCapacity和loadFactor构造一个新的空链接哈希集合。 此构造函数为包访问权限,不对外公开,实际只是是对LinkedHashSet的支持
30
HashSet(int initialCapacity, float loadFactor, boolean dummy) {
31
map = new LinkedHashMap<>(initialCapacity, loadFactor);
32
}
33
//返回对此set中元素进行迭代的迭代器。返回元素的顺序并不是特定的。底层实际调用底层HashMap的keySet来返回所有的key
34
//可见HashSet中的元素,只是存放在了底层HashMap的key上
35
public Iterator<E> iterator() {
36
return map.keySet().iterator();
37
}
38
//底层实际调用HashMap的size()方法返回Entry的数量,就得到该Set中元素的个数。
39
public int size() {
40
return map.size();
41
}
42
public boolean isEmpty() {
43
return map.isEmpty();
44
}
45
//底层实际调用HashMap的containsKey判断是否包含指定key。
46
public boolean contains(Object o) {
47
return map.containsKey(o);
48
}
49
public boolean add(E e) {
50
return map.put(e, PRESENT)==null;
51
}
52
/**
53
* 如果此set中尚未包含指定元素,则添加指定元素。
54
* 更确切地讲,如果此 set 没有包含满足(e==null ? e2==null : e.equals(e2))
55
* 的元素e2,则向此set 添加指定的元素e。
56
* 如果此set已包含该元素,则该调用不更改set并返回false。
57
* 底层实际将将该元素作为key放入HashMap。
58
* 由于HashMap的put()方法添加key-value对时,当新放入HashMap的Entry中key
59
* 与集合中原有Entry的key相同(hashCode()返回值相等,通过equals比较也返回true),
60
* 新添加的Entry的value会将覆盖原来Entry的value,但key不会有任何改变,
61
* 因此如果向HashSet中添加一个已经存在的元素时,新添加的集合元素将不会被放入HashMap中,
62
* 原来的元素也不会有任何改变,这也就满足了Set中元素不重复的特性。
63
* @param e 将添加到此set中的元素。
64
* @return 如果此set尚未包含指定元素,则返回true。
65
*/
66
public boolean remove(Object o) {
67
return map.remove(o)==PRESENT;
68
}
69
public void clear() {
70
map.clear();
71
}
72
//去除警告,克隆
73
("unchecked")
74
public Object clone() {
75
try {
76
HashSet<E> newSet = (HashSet<E>) super.clone();
77
newSet.map = (HashMap<E, Object>) map.clone();
78
return newSet;
79
} catch (CloneNotSupportedException e) {
80
throw new InternalError(e);
81
}
82
}
83
private void writeObject(java.io.ObjectOutputStream s)
84
throws java.io.IOException {
85
s.defaultWriteObject();
86
s.writeInt(map.capacity());
87
s.writeFloat(map.loadFactor());
88
s.writeInt(map.size());
89
for (E e : map.keySet())
90
s.writeObject(e);
91
}
92
private void readObject(java.io.ObjectInputStream s)
93
throws java.io.IOException, ClassNotFoundException {
94
s.defaultReadObject();
95
int capacity = s.readInt();
96
if (capacity < 0) {
97
throw new InvalidObjectException("Illegal capacity: " +
98
capacity);
99
}
100
float loadFactor = s.readFloat();
101
if (loadFactor <= 0 || Float.isNaN(loadFactor)) {
102
throw new InvalidObjectException("Illegal load factor: " +
103
loadFactor);
104
}
105
int size = s.readInt();
106
if (size < 0) {
107
throw new InvalidObjectException("Illegal size: " +
108
size);
109
}
110
capacity = (int) Math.min(size * Math.min(1 / loadFactor, 4.0f),
111
HashMap.MAXIMUM_CAPACITY);
112
SharedSecrets.getJavaOISAccess()
113
.checkArray(s, Map.Entry[].class, HashMap.tableSizeFor(capacity));
114
map = (((HashSet<?>)this) instanceof LinkedHashSet ?
115
new LinkedHashMap<E,Object>(capacity, loadFactor) :
116
new HashMap<E,Object>(capacity, loadFactor));
117
for (int i=0; i<size; i++) {
118
("unchecked")
119
E e = (E) s.readObject();
120
map.put(e, PRESENT);
121
}
122
}
123
public Spliterator<E> spliterator() {
124
return new HashMap.KeySpliterator<E,Object>(map, 0, -1, 0, 0);
125
}
126
}
127
Set需要注意的还是根据自己的需求选取正确的存储结构即可,而因为并没有get()方法给你使用,所以还是要用迭代器来获取想要的元素
对于HashSet而言,它是基于HashMap实现的,HashSet底层使用HashMap来保存所有元素,因此HashSet的实现比较简单,相关HashSet的操作,基本上都是直接调用底层HashMap的相关方法来完成。HashSet中的元素都存放在HashMap的key上面,而value中的值都是统一的一个private static final Object PRESENT = new Object();
说白了,HashSet就是限制了功能的HashMap,所以了解HashMap的实现原理,这个HashSet自然就通对于HashSet中保存的对象,主要要正确重写equals方法和hashCode方法,以保证放入Set对象的唯一性虽说是Set是对于重复的元素不放入,倒不如直接说是底层的Map直接把原值替代了(这个Set的put方法的返回值真有意思)。
<wiz_tmp_tag id="wiz-table-range-border" contenteditable="false" style="display: none;">
以上是关于HashSet的主要内容,如果未能解决你的问题,请参考以下文章