HashMap
Posted smartcat994
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HashMap相关的知识,希望对你有一定的参考价值。
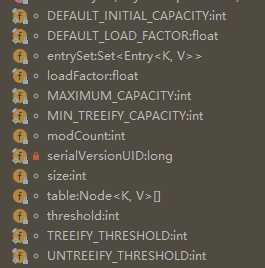
内部类Node<K, V>
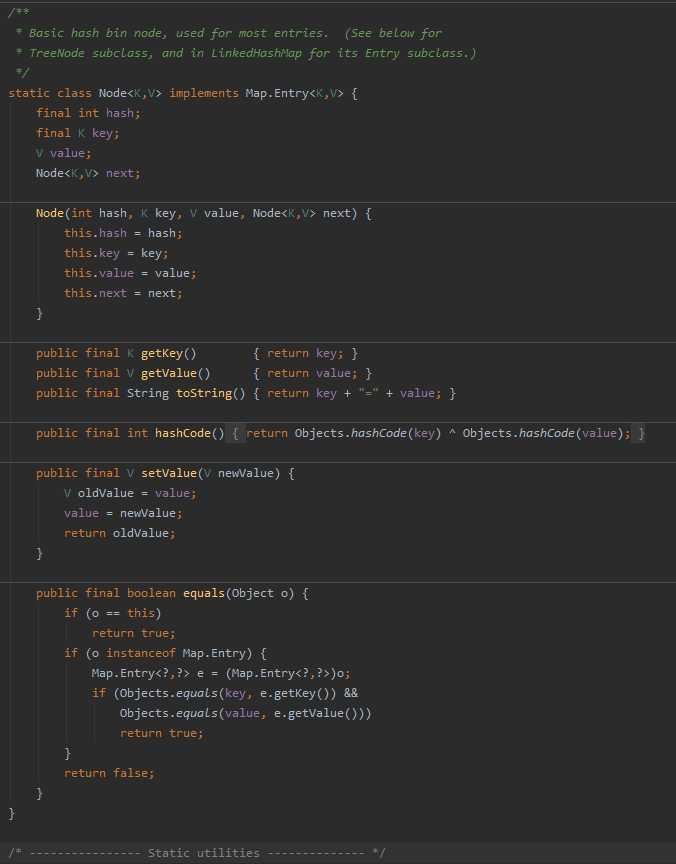
首先是这个内部类的声明部分,在声明中内部类Node实现了Map中的内部的接口Entry,因此我们很容易就可以发现,这个内部类是用来实现map内部的entry的,也就是是实际的键值对的储存的数据结构。
在这个内部类中,定义了几个成员变量,分别用来记录当前entry的哈希值、键与值,这里,哈希值与键是final的,即一旦生成了这个entry,则其哈希值与所对应的键是不可以改变的,但是其值是可以改变的,这与我们印象中map的使用方法是相符的。
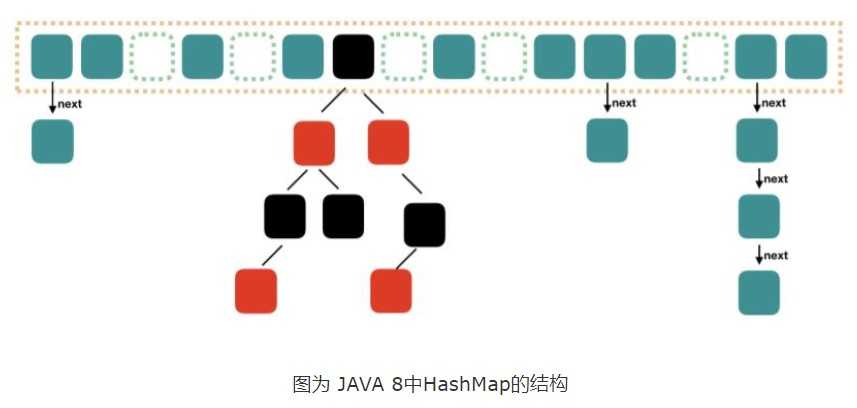
在这三个用来记录entry中实际数据的成员变量之后,是一个Node类型的成员变量,看到这个属性,熟悉数据结构的同学应该很快就会有所联想,特别是我们这个类的名字叫做Node,所以自然而然地会想到是不是与链表有关,答案是确实是一个链表,在Java中,HashMap中的每个键所对应的所有键值对是以链表的形式储存的,而其中的节点所用的数据结构就是现在所看的这个Node了。
Node的哈希方法,是将键与值的哈希取一次异或,作为自身的哈希值。Node类的equals()方法,首先判断参数中的对象o和自身地址是否相同,之后,再判断o是否是Map.Entry接口的实现类,若是的话,判断键与值是否分别相等,若想等,则返回true。Node来储存键值对。内部类TreeNode
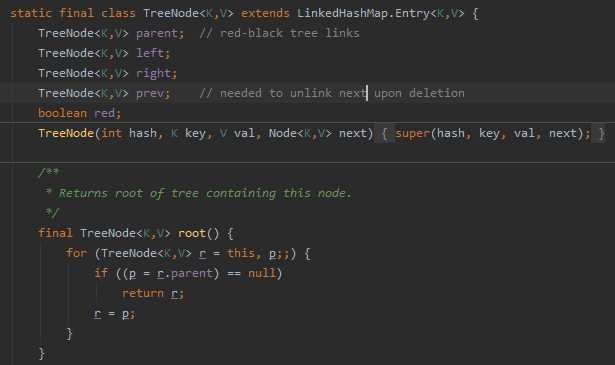
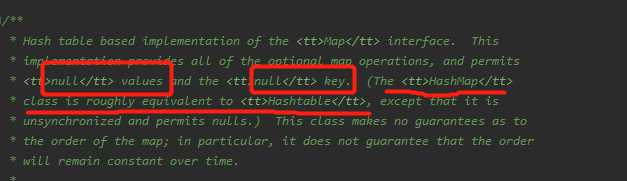
- 无序,允许为null,非同步
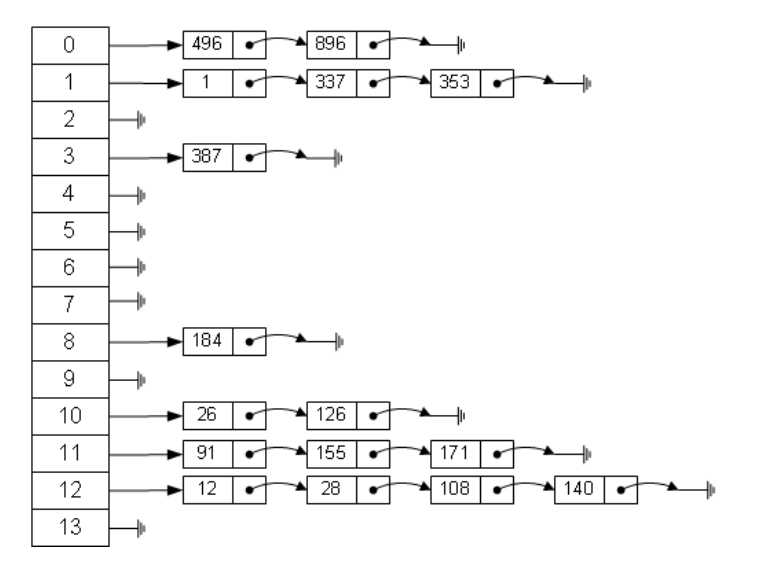
- 底层由散列表(哈希表)实现
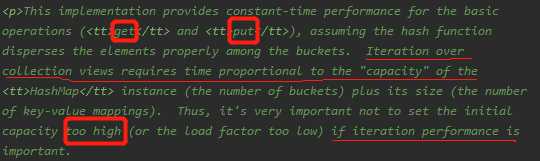
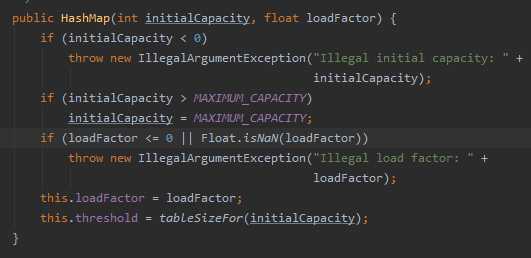
- 初始容量和装载因子对HashMap影响挺大的,设置小了不好,设置大了也不好


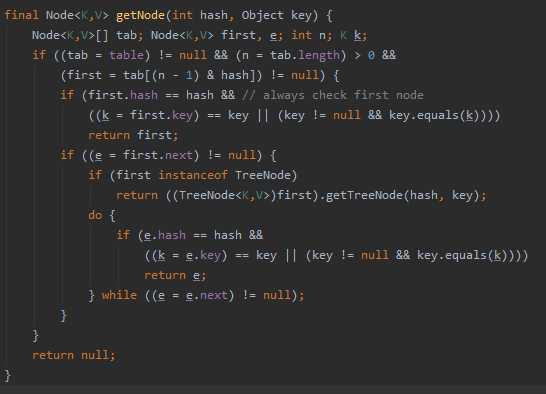
tab[i = (n - 1) & hash]。可以发现的是:在做&运算的时候,仅仅是后4位有效~那如果我们key的哈希值高位变化很大,低位变化很小。直接拿过去做&运算,这就会导致计算出来的Hash值相同的很多。
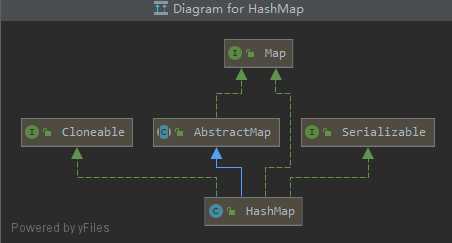
在JDK8中HashMap的底层是:数组+链表(散列表)+红黑树
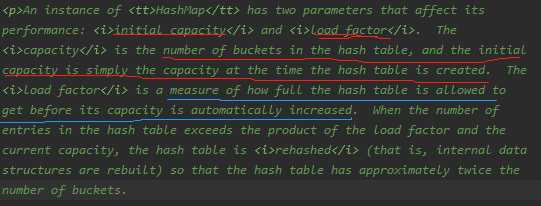
在散列表中有装载因子这么一个属性,当装载因子*初始容量小于散列表元素时,该散列表会再散列,扩容2倍!
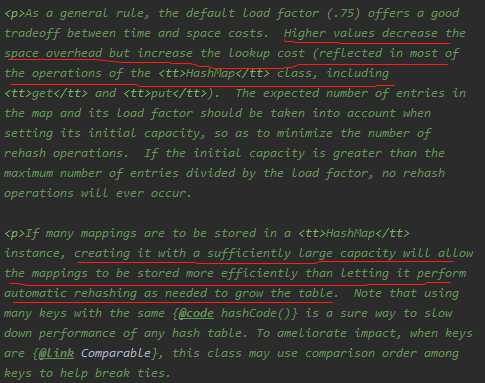
装载因子的默认值是0.75,无论是初始大了还是初始小了对我们HashMap的性能都不好
- 装载因子初始值大了,可以减少散列表再散列(扩容的次数),但同时会导致散列冲突的可能性变大(散列冲突也是耗性能的一个操作,要得操作链表(红黑树)!
- 装载因子初始值小了,可以减小散列冲突的可能性,但同时扩容的次数可能就会变多!
初始容量的默认值是16,它也一样,无论初始大了还是小了,对我们的HashMap都是有影响的:
- 初始容量过大,那么遍历时我们的速度就会受影响~
- 初始容量过小,散列表再散列(扩容的次数)可能就变得多,扩容也是一件非常耗费性能的一件事~
从源码上我们可以发现:HashMap并不是直接拿key的哈希值来用的,它会将key的哈希值的高16位进行异或操作,使得我们将元素放入哈希表的时候增加了一定的随机性。
还要值得注意的是:并不是桶子上有8位元素的时候它就能变成红黑树,它得同时满足我们的散列表容量大于64才行的~
这边记录下,刚刚好到今天学习Java时间2个月。目前看不懂HashMap,先枪毙,后面再补充!
参考:
https://www.cnblogs.com/liulaolaiu/p/11744380.html
https://www.jianshu.com/p/8a01b011e238
面试题:https://www.cnblogs.com/zengcongcong/p/11295349.html
以上是关于HashMap的主要内容,如果未能解决你的问题,请参考以下文章