实时流计算
Posted Icedzzz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了实时流计算相关的知识,希望对你有一定的参考价值。
总结自——吃透实时流计算
文章目录
1. 流计算通用架构
流计算系统通常包含五个部分:数据采集、数据传输、数据处理、数据存储和数据展现

数据采集模块
数据采集,就是从各种数据源收集数据的过程,比如浏览器、手机、工业传感器、日志代理等。怎样开发一个数据采集服务呢?最简单的方式,就是用 Spring Boot 开发一个 REST 服务,这样,我们就可以用 HTTP 请求的方式,从浏览器、手机等终端设备,将数据发送到数据采集服务器。
设计采集模块的五个难点:
- 第一点是吞吐量。我们一般用 TPS(Transactions Per Second),也就是每秒处理事务数,来描述系统的吞吐量。当吞吐量要求不高时,选择的余地往往更大些。你可以随意采用阻塞 IO ,或非阻塞 IO 的编程框架。但是当吞吐量要求很高时,通常就只能选择非阻塞 IO 的编程框架了。如果采用阻塞 IO 方式时,需要开启数千个线程,才能使吞吐量最大化,就可以考虑换成非阻塞 IO 的方案了。
- 第二点是时延。当吞吐量和时延同时有性能要求时,我一般是先保证能够满足时延要求,然后在此基础上,再尽可能提高吞吐量。如果一个服务实例的吞吐量,满足不了要求,就部署多个服务实例。
- 第三点是发送方式。数据可以逐条发送,也可以批次发送。相比逐条发送而言,批次发送每次的网络 IO 耗时更多,为了提升接收服务器的吞吐能力,我一般也会采用 Netty 这样的非阻塞 IO 框架。
- 第四点是连接方式。使用长连接还是短连接,一般由具体的场景决定。当有大量连接需要维持时,就需要使用非阻塞 IO 服务器框架,比如 Netty。而当连接数量较少时,采用长连接和连接池的方案,一般也会非常显著提升请求处理的性能。
- 第五点是连接数量。如果数据源相对固定,比如微服务之间的调用,那我们可以采用长连接配合连接池的方案,这样一般会非常显著地提升请求处理的性能。但当数据源很多或经常变化时,应该将连接保持时间(Keep Alive Timeout)设置为一个合理的值。
数据传输模块
数据传输,是指流数据在各个模块间流转的过程。
流计算系统中,一般是采用消息中间件进行数据传输的,比如 Apache Kafka、RabbitMQ 等。
在选择消息中间件时,你需要重点考虑五个方面的问题:吞吐量、时延、高可用、持久化和水平扩展。吞吐量和时延,通常是由产品和业务需求决定的。
而高可用和持久化,则是保证我们系统,能够正确稳定运行的重要因素。
- 高可用是指消息中间件的一个或多个节点,在发生故障时,仍然能够持续提供正常服务。
- 持久化则是指消息中间件里的消息,写入磁盘等存储介质后,重启时消息不会丢失。比如在消息中间件 Kafka 中,同一份数据在不同的物理节点上,保存多个副本,即使一个节点的数据,完全丢失,也能够通过其他节点上的数据副本,恢复出原来的数据。
- 水平扩展也是个非常重要的考量因素。当业务量逐渐增加时,原先的消息中间件处理能力逐渐跟不上,这时需要增加新的节点,以提升消息中间件的处理能力。比如 Kafka 可以通过增加 Kafka 节点和 topic 分区数的方式水平扩展处理能力。
数据处理模块
数据处理模块是下游计算系统的核心模块:这些业务问题可以分为以下四类。
-
第一类是数据转化。数据转化包括对流数据的抽取、清洗、转换和加载。比如使用 filter 函数过滤出符合条件的流数据,使用 map 函数给流数据增加新的字段。再比如更复杂的 Flink SQL CDC,也属于数据转化的内容。
-
第二类是在流数据上,统计各种指标,比如计数、求和、均值、标准差、极值、聚合、关联、直方图等。
-
第三类是模式匹配。模式匹配是指在流数据上,寻找预先设定的事件序列模式。比如我们常说的 CEP,也就是复杂事件处理,就属于模式匹配。
-
第四类是模型学习和预测。基于流的模型学习算法,可以实时动态地训练或更新模型参数,继而根据模型做出预测,能更加准确地描述数据背后当时正在发生的事情。
数据存储模块
数据存储模块的难点,则主要表现在能否根据具体的使用场景,选择最合适的存储方案。而实时流计算中,会涉及多种不同类型的数据存储问题。
在实时风控场景下,我们经常需要计算诸如“过去一天同一设备上登录的不同用户数”这种类型的查询。在数据量较小时,使用传统关系型数据库和结构化查询语言是个不错的选择。
但当数据量变得很大后,这种基于关系型数据库的方案会变得越来越吃力,直到最后根本不可能在实时级别的时延内完成计算。这个时候,如果采用像 Redis 这样的 NoSQL 数据库并结合优化的算法设计,就能够做到实时查询,并获得更高的吞吐能力。所以相比传统 SQL 数据库,实时流计算中会更多地使用 NoSQL 数据库。
2. 流计算本质:NIO+异步
NIO
- BIO 连接器的问题
由于是面向互联网采集数据,所以我们要实现的数据采集服务器,就是一个常见的 Web 服务。说到 Web 服务开发,作为 Java 开发人员,十有八九会用到 Tomcat。毕竟 Tomcat 一直是 Spring 生态的默认 Web 服务器,使用面是非常广的。
但使用 Tomcat 需要注意一个问题。在 Tomcat 7 及之前的版本中, Tomcat 默认使用的是 BIO 连接器, BIO 连接器的工作原理如下图 所示。
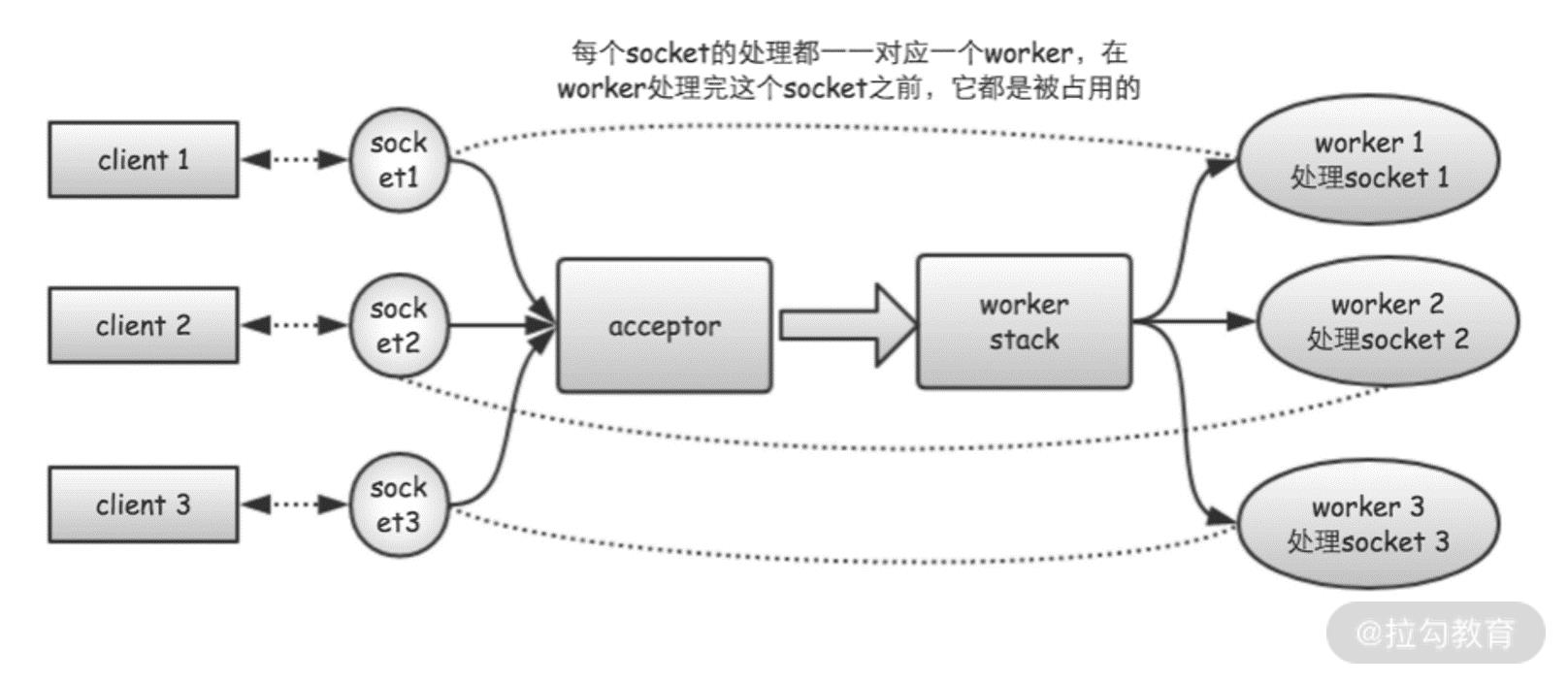 当使用 BIO 连接器时,Tomcat 会为每个客户端请求,分配一个独立的工作线程进行处理。这样,如果有 100 个客户端同时发送请求,就需要同时创建 100 个工作线程。如果有 1 万个客户端同时请求,就需要创建 1 万个工作线程。而如果是 100 万个客户端同时请求呢?是不是需要创建 100 万个工作线程?
当使用 BIO 连接器时,Tomcat 会为每个客户端请求,分配一个独立的工作线程进行处理。这样,如果有 100 个客户端同时发送请求,就需要同时创建 100 个工作线程。如果有 1 万个客户端同时请求,就需要创建 1 万个工作线程。而如果是 100 万个客户端同时请求呢?是不是需要创建 100 万个工作线程?
所以,**BIO 连接器的最大问题是它的工作线程和请求连接是一一对应耦合起来的。**当同时建立的请求连接数比较少时,使用 BIO 连接器是合适的,因为这个时候线程数是够用的。但考虑下,像 BATJ 等大厂的使用场景,哪家不是成万上亿的用户,哪家不是数十万、数百万的并发连接。在这些场景下,使用 BIO 连接器就根本行不通了。
- 使用 NIO 支持百万连接
毫无意外的是,从 Tomcat 8 开始,Tomcat 已经将 NIO 设置成了它的默认连接器。所以,如果你此时还在使用 Tomcat 7 或之前的版本的话,需要检查下你的服务器,究竟使用的是哪种连接
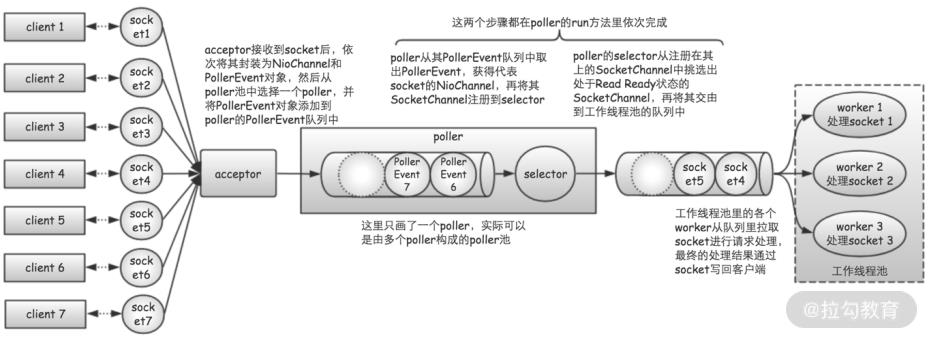 NIO 连接器相比 BIO 连接器,主要做出了两大改进。
NIO 连接器相比 BIO 连接器,主要做出了两大改进。
-
一是,使用“队列”将请求接收器和工作线程隔开;
-
二是,引入选择器来更加精细地管理连接套接字。
NIO 连接器的这两点改进,带来了两个非常大的好处。 -
一方面,将请求接收器和工作线程隔离开,可以让接收器和工作线程,各自尽其所能地工作,从而更加充分地使用 IO 和 CPU 资源。
-
另一方面,NIO 连接器能够保持的并发连接数,不再受限于工作线程数量,这样无须分配大量线程,数据接收服务器就能支持大量并发连接了。
如何优化IO和CPU都密集的任务
考虑实际的应用场景,当数据采集服务器在接收到数据后,往往还需要做三件事情:
-
一是,对数据进行解码;
-
二是,对数据进行规整化,包括字段提取、类型统一、过滤无效数据等;
-
三是,将规整化的数据发送到下游,比如消息中间件 Kafka。
在这三个步骤中,1 和 2 主要是纯粹的 CPU 计算,占用的是 CPU 资源,而 3 则是 IO 输出,占用的是 IO 资源。每接收到一条数据,我们都会执行以上三个步骤,所以也就构成了类似于图 4 所示的这种循环。
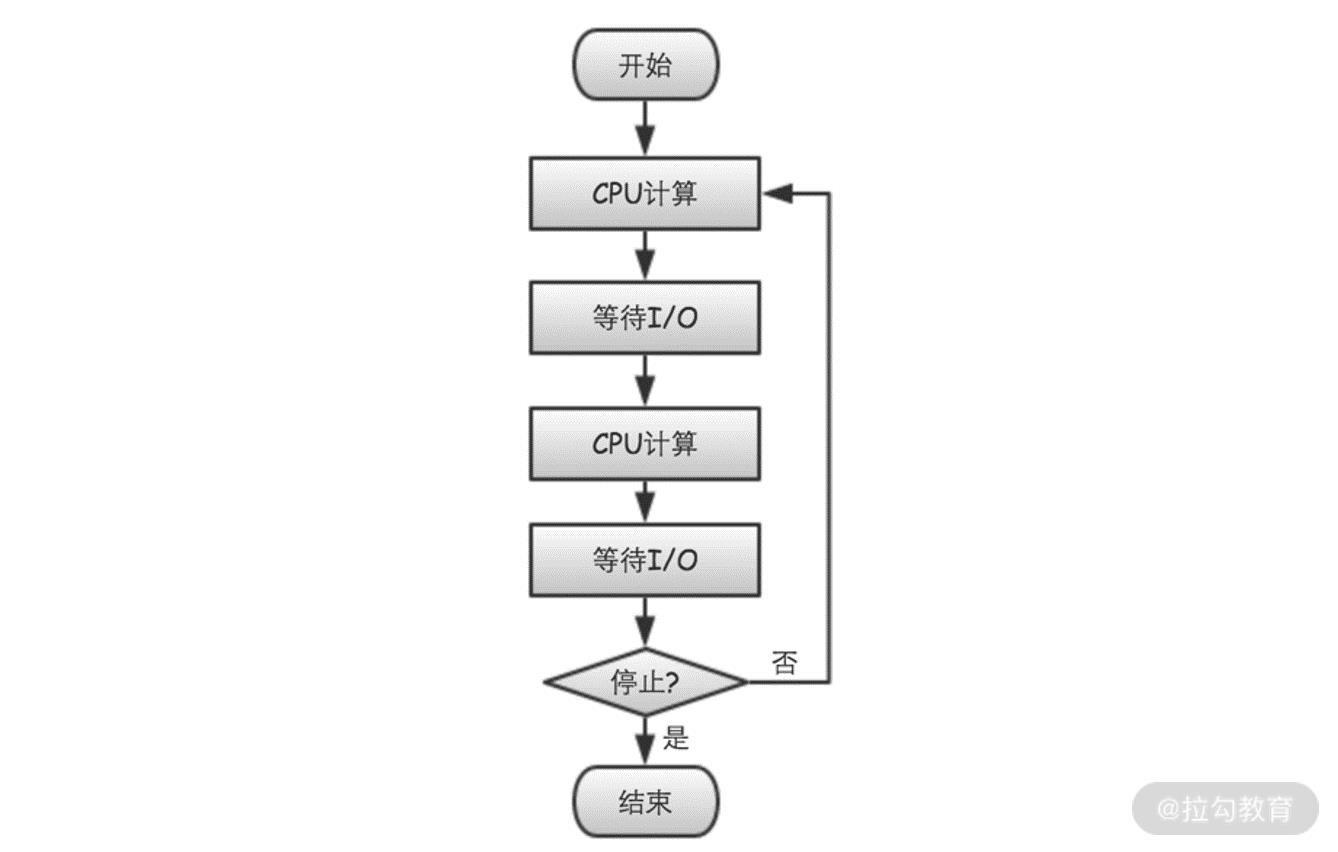 数据采集服务器是一个对 CPU 和 IO 资源的使用都比较密集的场景。为什么我们会强调这种CPU 和 IO 的使用都比较密集的情况呢?因为这是破解“NIO 和异步”为什么比“BIO 和同步”程序,性能更优的关键所在!下面我们就来详细分析下。
数据采集服务器是一个对 CPU 和 IO 资源的使用都比较密集的场景。为什么我们会强调这种CPU 和 IO 的使用都比较密集的情况呢?因为这是破解“NIO 和异步”为什么比“BIO 和同步”程序,性能更优的关键所在!下面我们就来详细分析下。
如果想提高 IO 利用率,一种简单且行之有效的方式,是使用更多的线程。这是因为当线程执行到涉及 IO 操作或 sleep 之类的函数时,会触发系统调用。**线程执行系统调用,会从用户态进入内核态,之后在其准备从内核态返回用户态时,操作系统将触发一次线程调度的机会。**对于正在执行 IO 操作的线程,操作系统很有可能将其调度出去。**这是因为触发 IO 请求的线程,通常需要等待 IO 操作完成,操作系统就会暂时让其在一旁等着,先调度其他线程执行。**当 IO 请求的数据准备好之后,线程才再次获得被调度的机会,然后继续之前的执行流程。
但是,是不是能够一直将线程的数量增加下去呢?不是的!如果线程过多,操作系统就会频繁地进行线程调度和上下文切换,这样 CPU 会浪费很多的时间在线程调度和上下文切换上,使得用于有效计算的时间变少,从而造成另一种形式的 CPU 资源浪费。
所以,针对 IO 和 CPU 都密集的任务,其优化思路是,尽可能让 CPU 不把时间浪费在等待 IO 完成上,同时尽可能降低操作系统消耗在线程调度上的时间。
异步编程
“异步”是相通的。其中,“异步”是“流”的本质,而“流”是“异步”的一种表现形式!
在 Java 8 之前,我们写异步代码的时候,主要还是依靠 ExecutorService 类和 Future 类。**Future 类提供了 get 方法,用于在任务完成时获取任务结果。但是,Future 类的 get 方法有个缺点,它是阻塞的,需要同步等待结果返回。**这就在事实上让原本异步执行的过程,重新退化成了同步的过程,失去了异步的作用。
**CompletableFuture 类采用回调的方式实现异步执行,并提供了大量有关构建异步调用链的API。**这些 API 使得 Java 异步编程变得无比灵活和方便,极大程度地解放了 Java 异步编程的生产力。可以说,CompletableFuture 类仅凭一己之力,将 Java 异步编程提升到了一个全新的境界。
参考:https://aobing.blog.csdn.net/article/details/115609360
CompletableFuture的使用:
- supplyAsync 是开启 CompletableFuture 异步调用链的方法之一。使用这个方法,会将supplier 封装为一个任务提交给 executor 执行,然后返回一个记录任务执行状态和结果的 CompletableFuture 对象。之后可以在这个 CompletableFuture 对象上挂接各种回调动作。所以说,supplyAsync 可以作为“流”的起点。
- thenApplyAsync 用于在 CompletableFuture 对象上挂接一个转化函数。当 CompletableFuture 对象完成时,将它的结果作为输入参数调用转化函数。转化函数在执行各种逻辑后,返回另一种类型的数据作为输出。这么一看,thenApplyAsync 的作用就是对“流”上的数据进行处理。
- thenAcceptAsync 用于在 CompletableFuture 对象上挂接一个接收函数。当CompletableFuture 对象完成时,将它的结果作为输入参数调用接收函数。与 thenApplyAsync 类似,接收函数可以执行各种逻辑,但不同的是,接收函数不会返回任何类型数据,或者说返回类型是 void。所以,thenAcceptAsync可以作为“流”的终点。
- thenComposeAsync 理解起来会复杂些,但它真的是一个非常重要的方法,请你务必理解它。
thenComposeAsync 在 API 形式上与 thenApplyAsync 类似,但是它的转化函数返回的不是一般类型的对象,而是一个 CompletionStage 对象,或者说得更具体点,实际中通常就是一个 CompletableFuture 对象。这意味着,我们可以在原来的 CompletableFuture 调用链上,插入另外一个调用链,从而形成一个新的调用链。这正是compose(组成、构成)的含义所在。所以,thenComposeAsync 的作用,就像是在“流”的某个地方,插入了另外一条“流”。 - 流水线上工人在加工产品时,总会时不时地发生些意外情况,那发生意外情况后该怎么办呢?这就是由 exceptionally 方法来处理的。
- CompletableFuture.allOf 的作用是将多个 CompletableFuture 合并成一个CompletableFuture。这又是一个非常有用的方法,我们可以用它实现类似于 Map/Reduce 或 Fork/Join 的功能。
CompletableFuture工作原理:
通过一段代码分析CompletableFuture的原理:
CompletableFuture<String> cf1 = CompletableFuture.supplyAsync(Tests::source, executor1);
CompletableFuture<String> cf2 = cf1.thenApplyAsync(Tests::echo, executor2);
CompletableFuture<String> cf3_1 = cf2.thenApplyAsync(Tests::echo1, executor3);
CompletableFuture<String> cf3_2 = cf2.thenApplyAsync(Tests::echo2, executor3);
CompletableFuture<String> cf3_3 = cf2.thenApplyAsync(Tests::echo3, executor3);
CompletableFuture<Void> cf3 = CompletableFuture.allOf(cf3_1, cf3_2, cf3_3);
CompletableFuture<Void> cf4 = cf3.thenAcceptAsync(x -> print("world"), executor4);
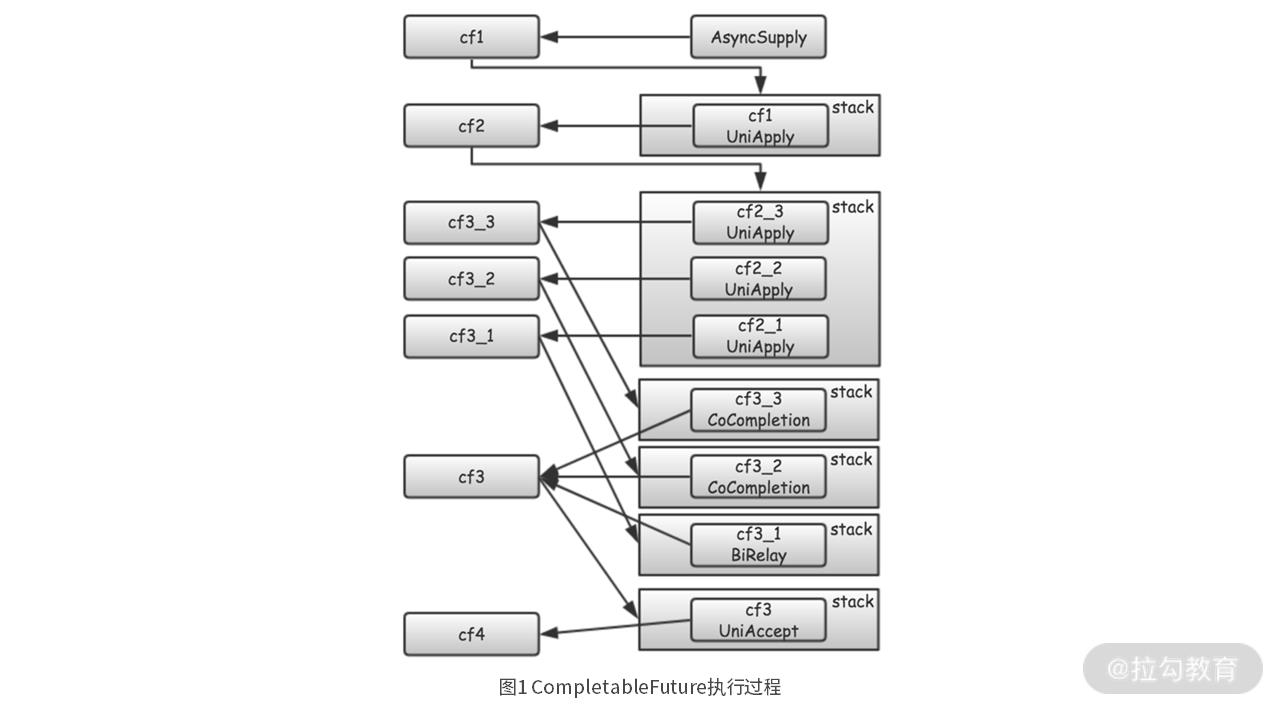 首先,通过 CompletableFuture.supplyAsync 创建了一个任务 Tests::source,并交给executor1 异步执行。用 cf1 来记录该任务在执行过程中的状态和结果。
首先,通过 CompletableFuture.supplyAsync 创建了一个任务 Tests::source,并交给executor1 异步执行。用 cf1 来记录该任务在执行过程中的状态和结果。
然后,通过 cf1.thenApplyAsync,指定当 cf1(Tests::source) 完成时,需要回调的任务Tests::echo。cf1 使用 stack 来管理这个后续要回调的任务Tests::echo。用 cf2 来记录回调任务 Tests::echo 的执行状态和结果。
再然后,通过连续三次调用 cf2.thenApplyAsync,指定当 cf2(Tests::echo) 完成时,需要回调的后续三个任务:Tests::echo1、Tests::echo2 和 Tests::echo3。cf2 也是用 stack 来管理这三个后续需要执行的任务。
接着,通过 CompletableFuture.allOf,创建一个合并 cf3_1、cf3_2、cf3_3 的 cf3。这也意味着 cf3 只有在 cf3_1、cf3_2、cf3_3 都完成时才能完成。在 cf3 内部,是用一个树(Tree)结构来记录它和 cf3_1、cf3_2、cf3_3 的依赖关系。
最后,通过 cf3.thenAcceptAsync,指定了当 cf3 完成时,需要回调的任务,即 print。用 cf4来记录 print 任务的状态和结果。
所以总的来说,就是 CompletableFuture 用 stack 来管理它在完成时后续需要回调的任务。当任务完成时,再通过依赖关系,找到后续需要处理的 CompletableFuture,并继续调用执行。这样,就构成了一个调用链,所有任务将按照该调用链依次执行。
3. 反压机制
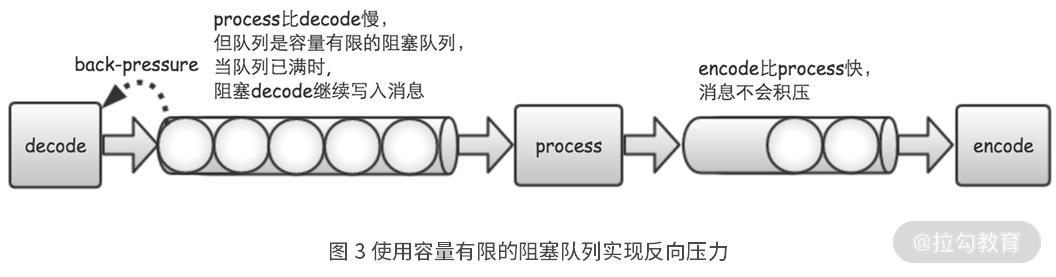
在流处理系统中,一旦有某个步骤处理的速度比较慢,比如在图 中,process 的速度比不上 decode 的速度,那么,消息就会在 process 的输入队列中积压。而由于执行器的任务队列,默认是非阻塞且不限容量的。这样,任务队列里积压的任务,就会越来越多。终有一刻,JVM 的内存会被耗尽,然后抛出 OOM 异常,程序就退出了。
 所以,为了避免 OOM 的问题,我们必须对上游输出给下游的速度做流量控制。
所以,为了避免 OOM 的问题,我们必须对上游输出给下游的速度做流量控制。
一种方式,是严格控制上游的发送速度。比如,控制上游每秒钟只能发送 1000 条消息。这种方法是可行的,但是非常低效。如果实际下游每秒钟能够处理 2000 条消息,那么,上游每秒钟发送 1000 条消息,就会使得下游一半的性能没有发挥出来。如果下游因为某种原因,性能降级为每秒钟只能处理 500 条消息,那么在一段时间后,同样会发生 OOM 问题。
这里有一种更优雅的方法,也就是反向压力。
反向压力原理:
在反向压力的方案中,上游能够根据下游的处理能力,动态地调整输出速度。当下游处理不过来时,上游就减慢发送速度,当下游处理能力提高时,上游就加快发送速度。
反向压力的思想,已经成为流计算领域的共识,并且形成了反向压力相关的标准,也就是Reactive Streams。
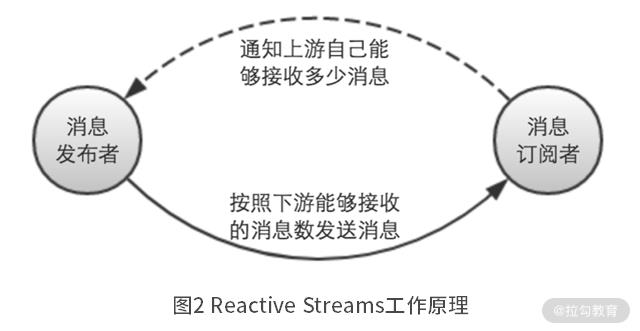
当下游的消息订阅者,从上游的消息发布者接收消息前,会先通知消息发布者自己能够接收多少消息。然后消息发布者就按照这个数量,向下游的消息订阅者发送消息。这样,整个消息传递的过程都是量力而行的,就不存在上下游之间因为处理速度不匹配,而造成的 OOM 问题了。
如何实现反向压力:
要实现反向压力的功能,只需要从两个方面来进行控制。
- 其一是,执行器的任务队列,它的容量必须是有限的。
- 其二是,当执行器的任务队列已经满了时,就阻止上游继续提交新的任务,直到任务队列,重新有新的空间可用为止。
 实现:
实现:
private final List<ExecutorService> executors;
private final Partitioner partitioner;
private Long rejectSleepMills = 1L;
public BackPressureExecutor(String name, int executorNumber, int coreSize, int maxSize, int capacity, long rejectSleepMills)
this.rejectSleepMills = rejectSleepMills;
this.executors = new ArrayList<>(executorNumber);
for (int i = 0; i < executorNumber; i++)
ArrayBlockingQueue<Runnable> queue = new ArrayBlockingQueue<>(capacity);
this.executors.add(new ThreadPoolExecutor(
coreSize, maxSize, 0L, TimeUnit.MILLISECONDS,
queue,
new ThreadFactoryBuilder().setNameFormat(name + "-" + i + "-%d").build(),
new ThreadPoolExecutor.AbortPolicy()));
this.partitioner = new RoundRobinPartitionSelector(executorNumber);
@Override
public void execute(Runnable command)
boolean rejected;
do
try
rejected = false;
executors.get(partitioner.getPartition()).execute(command);
catch (RejectedExecutionException e)
rejected = true;
try
TimeUnit.MILLISECONDS.sleep(rejectSleepMills);
catch (InterruptedException e1)
logger.warn("Reject sleep has been interrupted.", e1);
while (rejected);
在上面的代码中,BackPressureExecutor 类在初始化时,新建一个或多个 ThreadPoolExecutor 对象,作为执行任务的线程池。这里面的关键点有两个。
-
第一个是,在创建 ThreadPoolExecutor 对象时,采用 ArrayBlockingQueue。这是一个容量有限的阻塞队列。因此,当任务队列已经满了时,就会停止继续往队列里添加新的任务,从而避免内存无限大,造成 OOM 问题。
-
第二个是,将 ThreadPoolExecutor 拒绝任务时,采用的策略设置为 AbortPolicy。这就意味着,在任务队列已经满了的时候,如果再向任务队列提交任务,就会抛出 RejectedExecutionException 异常。之后,我们再通过一个 while 循环,在循环体内,捕获 RejectedExecutionException 异常,并不断尝试,重新提交任务,直到成功为止。
4. 死锁:为什么流计算应用突然卡住,不处理数据了?
流处理框架使用DAG来代表数据的流向,其实之所以要强调“无环”,是因为在流计算系统中,**当“有环”和“反向压力”一起出现时,流计算系统将会出现“死锁”问题。**而程序一旦出现“死锁”,那除非人为干预,否则程序将一直停止执行,也就是我们常说的“卡死”。这在生产环境是绝对不能容忍的。
- 为什么流计算不能有环?
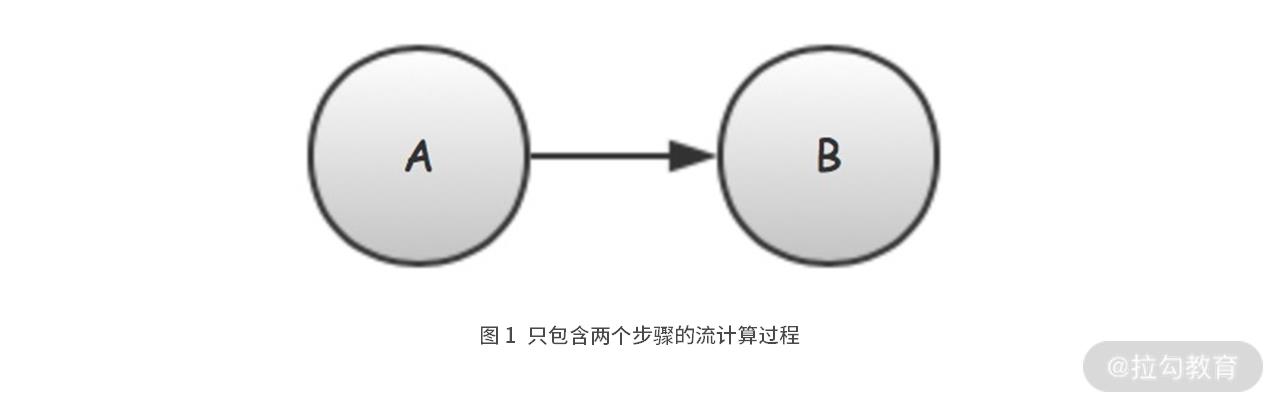
我们从一个简单的流计算过程开始,这个流计算过程的 DAG 如下图 1 所示。
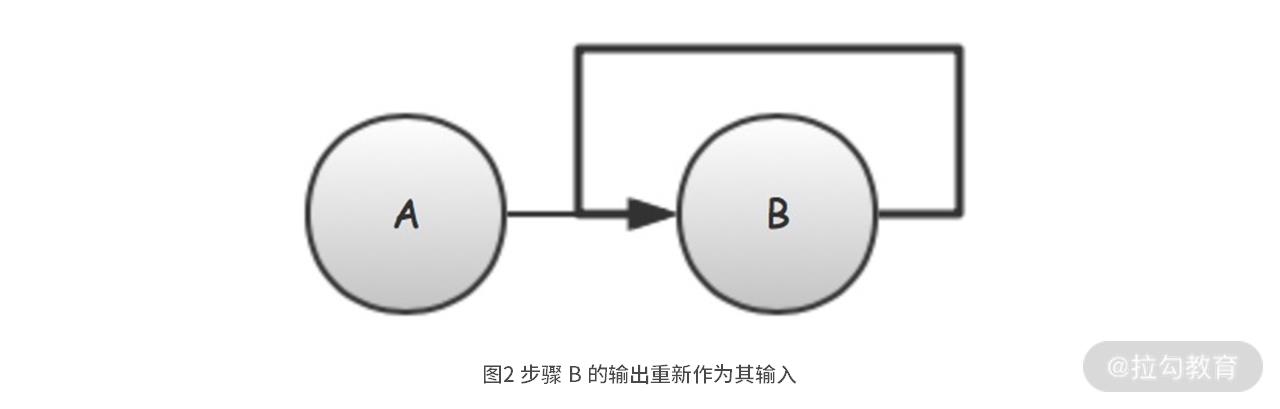
现在,我们需要对图 1 的 DAG 稍微做点变化,让 B 在处理完后,将其结果重新输入给自己再处理一次。这种处理逻辑,在实际开发中也会经常遇到,比如 B 在处理失败时,就将处理失败的任务,重新添加到自己的输入队列,从而实现失败重试的功能。
用代码来实现:
void demo1()
while (!Thread.currentThread().isInterrupted())
CompletableFuture
.supplyAsync(this::stepA, this.AExecutor)
.thenApplyAsync(this::stepB, this.BExecutor)
.thenApplyAsync(this::stepB, this.BExecutor);
上面的代码中,我们增加了一次 thenApplyAsync 调用,用于将 stepB 的输出重新作为其输入。需要注意的是,由于第二次 stepB 调用后没有再设置后续步骤,所以,虽然 DAG 上“有环”,但 stepB 并不会形成死循环。
上面这段代码,初看起来并没什么问题,毕竟就是简单地新增了一个“重试”的效果嘛。但是,如果你实际运行上面这段代码就会发现,只需要运行不到 1 秒钟,上面这段程序就会“卡”住,之后控制台会一动不动,没有一条日志打印出来。
- 流计算过程死锁分析
说到“死锁”,你一定会想到“锁”的使用。一般情况下之所以会出现“死锁”,主要是因为我们使用锁的方式不对,比如使用了不可重入锁,或者使用多个锁时出现了交叉申请锁的情况。这种情况下出现的“死锁”问题,我们确确实实看到了“锁”的存在。
但当我们在使用流计算编程时,你会发现,“流”的编程方式已经非常自然地避免了“锁”的使用,也就是说我们并不会在“流”处理的过程中用到“锁”。这是因为,当使用“流”时,被处理的对象依次从上游流到下游。当对象在流到某个步骤时,它是被这个步骤的线程唯一持有,因此不存在对象竞争的问题。
但这是不是就说流计算过程中不会出现“死锁”问题呢?不是的。最直接的例子就是前面的代码,我们根本就没有用到“锁”,但它还是出现了“死锁”的问题。
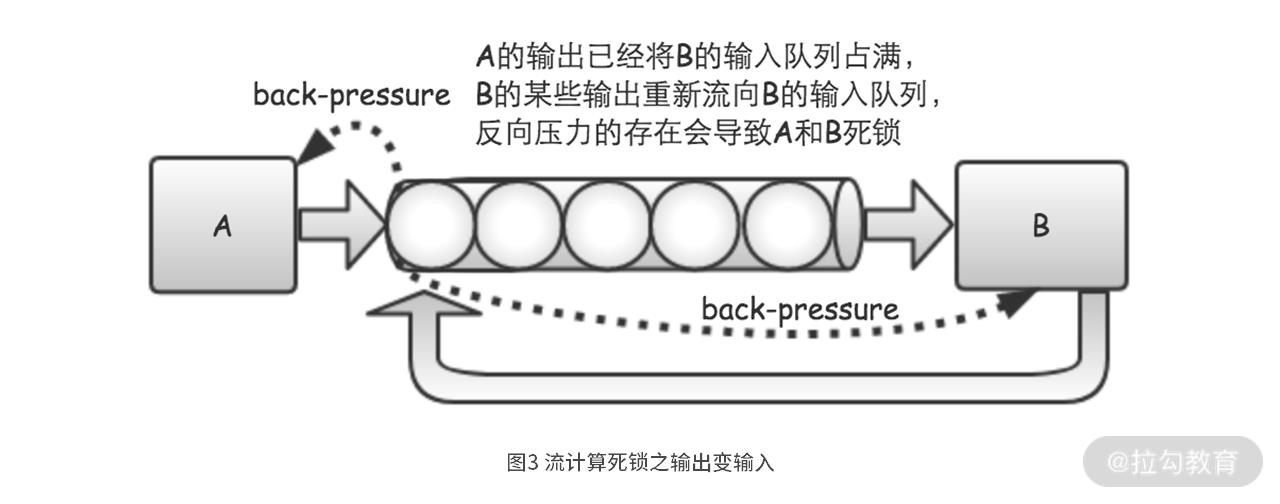
整个流计算过程有 A 和 B 这两个步骤,并且具备“反向压力”能力。这时候,如果 A 的输出已经将 B 的输入队列占满,而 B 的输出又需要重新流向 B 的输入队列,那么由于“反向压力”的存在,B 会一直等到其输入队列有空间可用。而 B 的输入队列又因为 B 在等待,永远也不会有空间被释放,所以 B 会一直等待下去。同时,A 也会因为 B 的输入队列已满,由于反向压力的存在,它也只能不停地等待下去。
如此一来,整个流计算过程就形成了一个死锁,A 和 B 两个步骤都会永远等待下去,这样就出现了我们前边看到的程序“卡”住现象。
- 形成“环”的原因
在图 2 所示的 DAG 中,我们是因为需要让 stepB 失败重试,所以“随手”就让 stepB 将其输出重新作为输入重新执行一次。这姑且算是一种比较特殊的需求吧。
但在实际开发过程中,我们的业务逻辑明显是可以分为多个依次执行的步骤,用 DAG 画出来时,也是“无环”的。但在写代码时,有时候一不小心,也会无意识地将一个本来无环的 DAG,实现成了有环的过程。
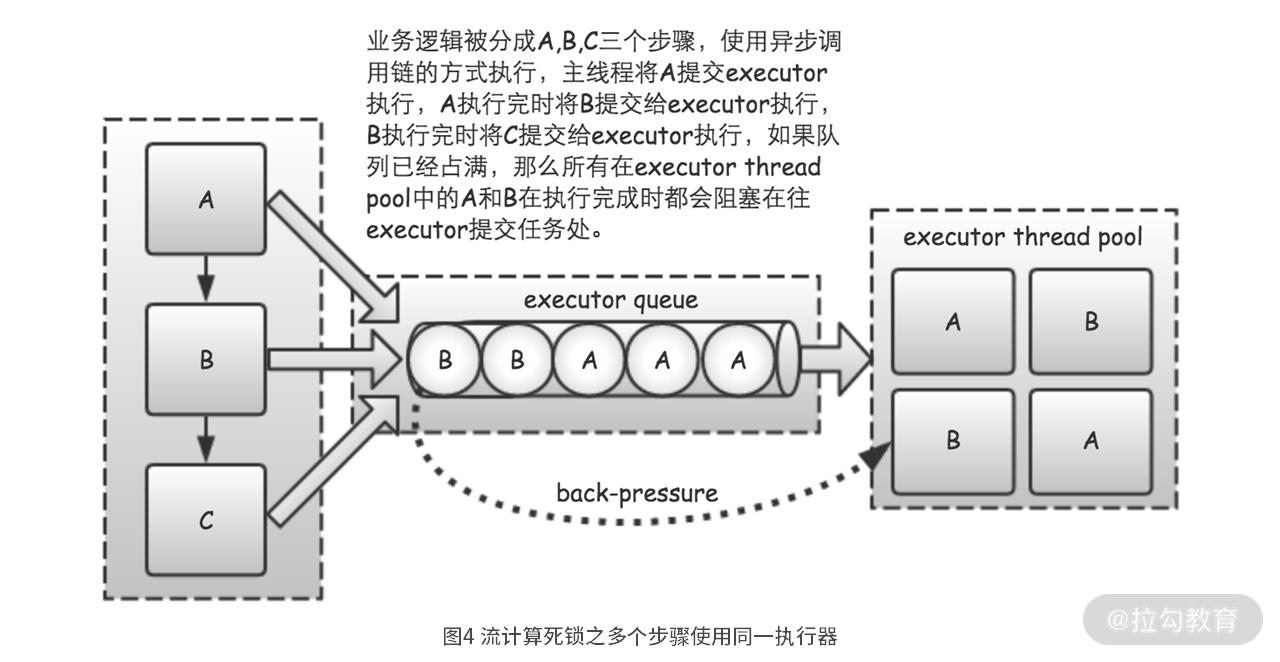 业务逻辑本来是 A 到 B 到 C 这样的“无环”图,结果由于我们给这三个不同的步骤,分配了同一个执行器 executor,实际实现的流计算过程就成了一个“有环”的过程。
业务逻辑本来是 A 到 B 到 C 这样的“无环”图,结果由于我们给这三个不同的步骤,分配了同一个执行器 executor,实际实现的流计算过程就成了一个“有环”的过程。
在这个“有环”的实现中,只要任意一个步骤的处理速度比其他步骤慢,就会造成执行器的输入队列占满。一旦输入队列占满,由于反向压力的存在,各个步骤的输出就不能再输入到队列中。最终,所有执行步骤将会阻塞,也就形成了死锁,整个系统也被“卡”死。
- 如何避免死锁
所以,我们在流计算过程中,应该怎样避免死锁呢?其实很简单,有三种方法。
**一是不使用反向压力功能。**只需要我们不使用反向压力功能,即使业务形成“环”了,也不会死锁,因为每个步骤只需要将其输出放到输入队列中,不会发生阻塞等待,所以就不会死锁了。但很显然,这种方法禁止使用。毕竟,没有反向压力功能,就又回到 OOM 问题了,这是万万不可的!
**二是避免业务流程形成“环”。**这个方法最主要的作用,是指导我们在设计业务流程时,不要将业务流程设计成“有环”的了。否则如果系统有反向压力功能的话,容易出现类似于图 3 的死锁问题。
**三是千万不要让多个步骤使用相同的队列或执行器。**这个是最容易忽略的问题,特别是一些对异步编程和流计算理解不深的开发人员,最容易给不同的业务步骤分配相同的队列或执行器,在不知不觉中就埋下了死锁的隐患。
5. 流处理架构
1. Lambda架构
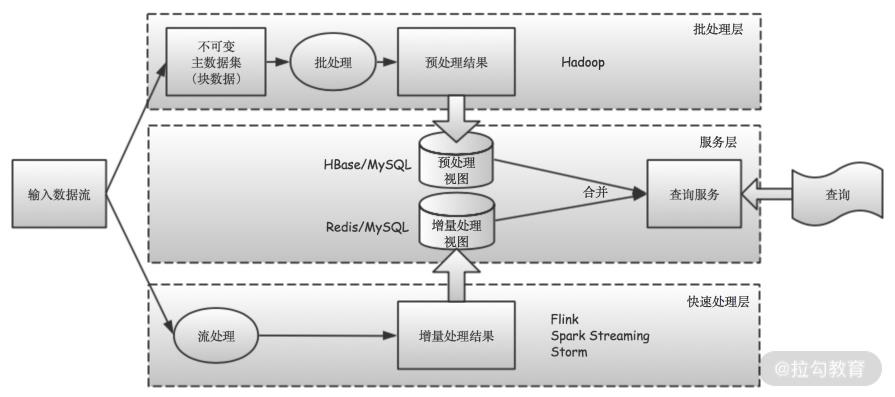
从上面的图 可以看出,Lambda 架构总体上分为三层:批处理层(batch layer)、快速处理层(speed layer)和服务层(serving layer),其中:
-
批处理层负责处理主数据集(也就是历史全量数据);
-
快速处理层负责处理增量数据(也就是新进入系统的数据);
-
服务层用于将批处理层和快速处理层的结果合并起来,给用户或应用程序提供查询服务。
Lambda 架构是一种架构设计思路,针对每一层的技术组件选型并没有严格限定。我们可以根据自己公司和项目的实际情况,选择相应的技术方案。
对于批处理层,数据存储可以选择 HDFS、S3 等大数据存储系统,而计算工具则可以选择 MapReduce、Hive、Spark 等大数据处理框架。批处理层的计算结果(比如数据库表或者视图),由于需要被服务层或快速处理层快速访问,所以可以存放在诸如 mysql、HBase 等能够快速响应查询请求的数据库中。
对于快速处理层,这就是各种流计算框架的用武之地了,比如 Flink、Spark Streaming 和 Storm 等。快速处理层由于对性能要求更加严苛,它们的计算结果可以存入像 Redis 这样具有超高性能表现的内存数据库中。不过有时候为了查询方便,也可以将计算结果存放在 MySQL 等传统数据库中,毕竟这些数据库配合缓存一起使用的话,性能也是非常棒的。
对于服务层,当其接收到查询请求时,就可以分别从存储批处理层和快速处理层计算结果的数据库中,取出相应的计算结果并做合并,就能得到最终的查询结果了。
不过,虽然 Lambda 架构实现了间接的实时计算,但它也存在一些问题。**其中最主要的就是,对于同一个查询目标,需要分别为批处理层和快速处理层开发不同的算法实现。也就是说,对于相同的逻辑,需要开发两种不同的代码,并使用两种不同的计算框架(比如同时使用 Storm 和 Spark),这对开发、测试和运维,都带来一定的复杂性和额外工作。**所以,Lambda 架构的改进版本,也就是 Kappa 架构应运而生。
2. kappa架构
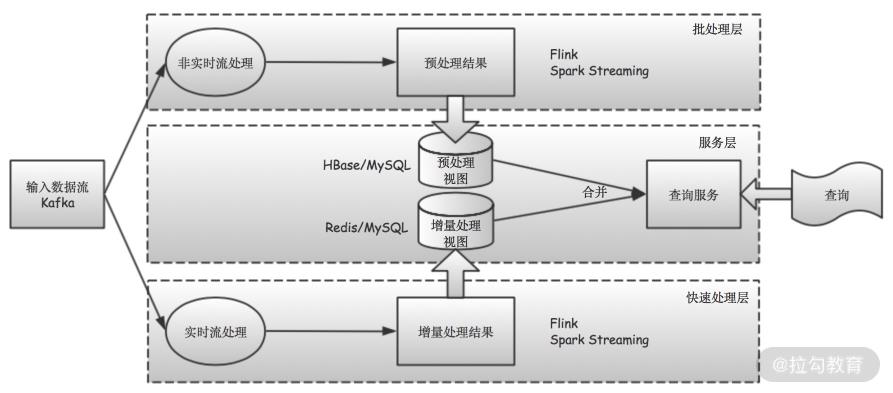
从上面的图 可以看出,Kappa 架构相比 Lambda 架构的最大改进,就是将批处理层也用快速处理层的流计算技术所取代。这样一来,批处理层和快速处理层使用相同的流计算逻辑,并有更统一的计算框架,从而降低了开发、测试和运维的成本。
另外,由于 Kappa 架构完全使用“流计算”来处理数据,这就让我们在“存储”方面也可以作出调整。我们不必再像在 Lambda 架构中,将离线数据转储到 HDFS、S3 这样的“块数据”存储系统。**而只需要将数据按照“流”的方式,存储在 Kafka 这样的“流数据”存储系统里即可。**这既减少了数据存储的空间,也避免了不必要的数据转储,同时还降低了系统的复杂程度。
所以说,在 Flink 和 Spark Streaming 等新一代流批一体计算框架,以及诸如 Kafka 和 Pulsar 等新一代流式大数据存储系统的双重加持下,使用 Kappa 架构处理大数据,已经成为一种非常自然的选择。
以上是关于实时流计算的主要内容,如果未能解决你的问题,请参考以下文章