Flink核心概念
Posted zz-ksw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Flink核心概念相关的知识,希望对你有一定的参考价值。
分布式缓存
分布式缓存的思想在hadoop和spark中都有体现,Flink 提供的分布式缓存类似 Hadoop,目的是为了在分布式环境中让每一个 TaskManager 节点保存一份相同的数据或者文件,当前计算节点的 task 就像读取本地文件一样拉取这些配置。
比如在进行表与表 Join 操作时,如果一个表很大,另一个表很小,那么我们就可以把较小的表进行缓存,在每个 TaskManager 都保存一份,然后进行 Join 操作。
那么我们应该怎样使用 Flink 的分布式缓存呢?举例如下:
public class DistributedCacheDemo { ? public static void main(String[] args) throws Exception { ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //1:注册缓存文件,可以读取hdfs上的文件,也可以本地文件 //nameAgeConfig.txt文件内容: //jack,22 //lily,20 //zhangsan,21 //lisi,25 //wanger,26 env.registerCachedFile("C:\\Users\\ksw\\Desktop\\nameAgeConfig.txt", "nameAgeConfig"); ? // 生成测试数据 DataSource<String> data = env.fromElements("jack", "zhangsan"); ? // 从分布式缓存中获取每个人对应的年龄 MapOperator<String, String> result = data.map(new RichMapFunction<String, String>() { private Map<String, String> nameAgeMap = new HashMap<>(); ? //重写open方法 @Override public void open(Configuration parameters) throws Exception { super.open(parameters); //2:可根据注册的名字使用该缓存文件 File cacheFile = getRuntimeContext().getDistributedCache().getFile("nameAgeConfig"); List<String> lines = FileUtils.readLines(cacheFile); for (String line : lines) { String[] split = line.split(","); this.nameAgeMap.put(split[0], split[1]); } } ? @Override public String map(String name) throws Exception { //处理逻辑 String age = nameAgeMap.get(name); return name + ":" + age; } }); ? result.printToErr(); } }
在使用分布式缓存时也需要注意一些问题,比如:
-
缓存的文件在任务运行期间最好是只读的
-
缓存的文件和数据不宜过大
并行度(parallelism)
官网:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/parallel.html#parallel-execution
一般情况下,我们可以通过四种级别来设置任务的并行度。
算子级别(Operator Level)
在代码中可以调用 setParallelism 方法来设置每一个算子的并行度。例如:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); ? DataStream<String> text = [...] DataStream<Tuple2<String, Integer>> wordCounts = text .flatMap(new LineSplitter()) .keyBy(0) .timeWindow(Time.seconds(5)) .sum(1).setParallelism(5); ? wordCounts.print(); ? env.execute("Word Count Example");
事实上,Flink 的每个算子都可以单独设置并行度。这也是我们最推荐的一种方式,可以针对每个算子进行任务的调优。
执行环境级别(Execution Environment Level)
调用 env.setParallelism() 方法,来设置当前执行环境的并行度,这个配置会对当前任务的所有算子、Source、Sink 生效。当然你还可以在算子级别设置并行度来覆盖这个设置。
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setParallelism(3); ? DataStream<String> text = [...] DataStream<Tuple2<String, Integer>> wordCounts = [...] wordCounts.print(); ? env.execute("Word Count Example");
提交任务级别(Client Level)
用户在提交任务时,可以显示的指定 -p 参数来设置任务的并行度,例如:
./bin/flink run -p 10 ../examples/*WordCount-java*.jar
系统配置级别(System Level)
flink-conf.yaml 文件中的一个配置:parallelism.default,该配置是在系统层面设置所有执行环境的并行度配置。
整体上讲,这四种级别的配置生效优先级如下:算子级别 > 执行环境级别 > 提交任务级别 > 系统配置级别。
在这里,要特别提一下 Flink 中的 Slot 概念。我们知道,Flink 中的 TaskManager 是执行任务的节点,那么在每一个 TaskManager 里,还会有“槽位”,也就是 Slot。Slot 个数代表的是每一个 TaskManager 的并发执行能力。
假如我们指定 taskmanager.numberOfTaskSlots:3,即每个 taskManager 有 3 个 Slot ,那么整个集群就有 3 * taskManager 的个数多的槽位。这些槽位就是我们整个集群所拥有的所有执行任务的资源。
设置最大并行度
使用 savepoints 时,应该考虑设置最大并行度。当作业从一个 savepoint 恢复时,你可以改变特定算子或着整个程序的并行度,并且此设置会限定整个程序的并行度的上限。由于在 Flink 内部将状态划分为了 key-groups,且性能所限不能无限制地增加 key-groups,因此设定最大并行度是有必要的。
最大并行度可以在所有设置并行度的地方进行设定(Client Level和System Level除外)。与调用 setParallelism() 方法修改并行度相似,你可以通过调用 setMaxParallelism() 方法来设定最大并行度。
默认的最大并行度等于将 operatorParallelism + (operatorParallelism / 2) 值四舍五入到大于等于该值的一个整型值,并且这个整型值是 2 的幂次方,注意默认最大并行度下限为 128,上限为 32768。
注意 为最大并行度设置一个非常大的值将会降低性能,因为一些 state backends 需要维持内部的数据结构,而这些数据结构将会随着 key-groups 的数目而扩张(key-group 是状态重新分配的最小单元)。
Flink中的时间概念
Event Time / Processing Time / Ingestion Time
-
事件时间(Event Time),即事件实际发生的时间;
-
摄入时间(Ingestion Time),事件进入流处理框架的时间;
-
处理时间(Processing Time),事件被处理的时间。
下面的图详细说明了这三种时间的区别和联系:
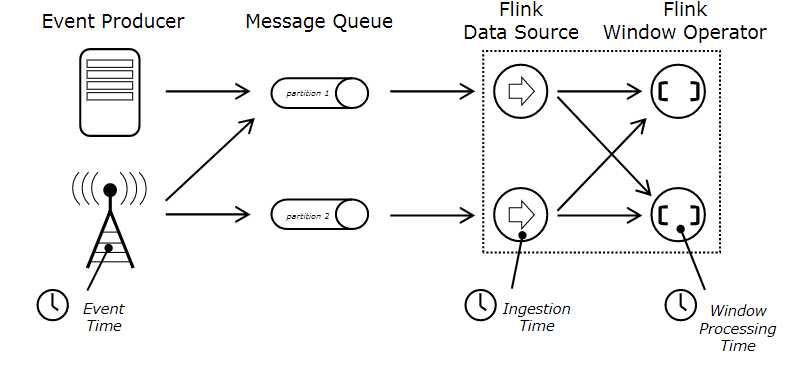
事件时间(Event Time) 事件时间(Event Time)指的是数据产生的时间,这个时间一般由数据生产方自身携带,比如 Kafka 消息,每个生成的消息中自带一个时间戳代表每条数据的产生时间。Event Time 从消息的产生就诞生了,不会改变,也是我们使用最频繁的时间。
利用 Event Time 需要指定如何生成事件时间的“水印”(watermarks),并且一般和窗口配合使用,具体会在下面的“水印”内容中详细讲解。
处理时间(Processing Time)
处理时间(Processing Time)指的是数据被 Flink 框架处理时机器的系统时间,Processing Time 是 Flink 的时间系统中最简单的概念,但是这个时间存在一定的不确定性,比如消息到达处理节点延迟等影响。
摄入时间(Ingestion Time) 摄入时间(Ingestion Time)是事件进入 Flink 系统的时间,在 Flink 的 Source 中,每个事件会把当前时间作为时间戳,后续做窗口处理都会基于这个时间。理论上 Ingestion Time 处于 Event Time 和 Processing Time之间。
与事件时间相比,摄入时间无法处理延时和无序的情况,但是不需要明确执行如何生成 watermark。在系统内部,摄入时间采用更类似于事件时间的处理方式进行处理,但是有自动生成的时间戳和自动的 watermark。
可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。如果需要处理此类问题,建议使用 EventTime。
指定使用时间类型
在代码中指定 Flink 使用的时间类型为 EventTime:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); ? env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); ? // 另外也可以设置时间类型为IngestionTime或EventTime: // env.setStreamTimeCharacteristic(TimeCharacteristic.IngestionTime); // env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); ? DataStream<MyEvent> stream = env.addSource(new FlinkKafkaConsumer09<MyEvent>(topic, schema, props)); ? stream .keyBy( (event) -> event.getUser() ) .timeWindow(Time.hours(1)) .reduce( (a, b) -> a.add(b) ) .addSink(...);
Flink中的水印(WaterMark)
WaterMark的本质是什么
WaterMark在 Flink中为“水位线”,它在本质上是一个时间戳。
WaterMark的出现是为了解决实时计算中的数据乱序问题,它的本质是 DataStream 中一个带有时间戳的元素。如果 Flink 系统中出现了一个 WaterMark T,那么就意味着 EventTime < T 的数据都已经到达,窗口的结束时间和 T 相同的那个窗口被触发进行计算了。
也就是说:WaterMark是 Flink 判断迟到数据的标准,同时也是窗口触发的标记。
在上面的时间类型中我们知道,Flink 中的时间:
-
EventTime 每条数据都携带时间戳;
-
ProcessingTime 数据不携带任何时间戳的信息;
-
IngestionTime 和 EventTime 类似,不同的是 Flink 会使用系统时间作为时间戳绑定到每条数据,可以防止 Flink 内部处理数据是发生乱序的情况,但无法解决数据到达 Flink 之前发生的乱序问题。
所以,我们在处理消息乱序的情况时,会用 EventTime 和 WaterMark 进行配合使用。
WaterMark是如何生成的
Flink 提供了 assignTimestampsAndWatermarks() 方法来实现水印的提取和指定,该方法接受的入参有 AssignerWithPeriodicWatermarks 和 AssignerWithPunctuatedWatermarks 两种。
生成WaterMark代码模型:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment(); env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); ? DataStream<MyEvent> stream = env.readFile( myFormat, myFilePath, FileProcessingMode.PROCESS_CONTINUOUSLY, 100, FilePathFilter.createDefaultFilter(), typeInfo); ? // 在这里调用了assignTimestampsAndWatermarks()方法,并且传入我们自己定义的new MyTimestampsAndWatermarks() DataStream<MyEvent> withTimestampsAndWatermarks = stream .filter( event -> event.severity() == WARNING ) .assignTimestampsAndWatermarks(new MyTimestampsAndWatermarks()); ? withTimestampsAndWatermarks .keyBy( (event) -> event.getGroup() ) .timeWindow(Time.seconds(10)) .reduce( (a, b) -> a.add(b) ) .addSink(...);
与kafka集成时候怎么生成WaterMark可参考:https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/connectors/kafka.html
周期性水印
我们在使用 AssignerWithPeriodicWatermarks 周期生成水印时,周期默认的时间是 200ms,这个时间的指定位置为:
@PublicEvolving public void setStreamTimeCharacteristic(TimeCharacteristic characteristic) { this.timeCharacteristic = Preconditions.checkNotNull(characteristic); if (characteristic == TimeCharacteristic.ProcessingTime) { getConfig().setAutoWatermarkInterval(0); } else { getConfig().setAutoWatermarkInterval(200); } }
我们通过 env.setStreamTimeCharacteristic() 方法指定 Flink 系统的时间类型,然后这个 setStreamTimeCharacteristic() 方法中会做判断,如果用户传入的是 TimeCharacteristic.eventTime 类型,那么 AutoWatermarkInterval 的值则为 200ms ,如上述代码所示。当然,我们也可以使用 ExecutionConfig.setAutoWatermarkInterval() 方法来指定自动生成的时间间隔。
周期性水印Demo:
public static void main(String[] args) throws Exception { ? StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironment(); ? //设置为eventtime事件类型 env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime); //设置水印生成时间间隔100ms env.getConfig().setAutoWatermarkInterval(100); ? DataStream<String> dataStream = env .socketTextStream("127.0.0.1", 9000) .assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<String>() { private Long currentTimeStamp = 0L; //maxOutOfOrderness参数指的是允许数据乱序的时间范围。简单说,允许数据迟到maxOutOfOrderness 这么长的时间 private Long maxOutOfOrderness = 5000L; ? @Override public Watermark getCurrentWatermark() { ? return new Watermark(currentTimeStamp - maxOutOfOrderness); } ? @Override public long extractTimestamp(String s, long l) { String[] arr = s.split(","); long timeStamp = Long.parseLong(arr[1]); currentTimeStamp = Math.max(timeStamp, currentTimeStamp); System.err.println(s + ",EventTime:" + timeStamp + ",watermark:" + (currentTimeStamp - maxOutOfOrderness)); return timeStamp; } }); ? dataStream.map(new MapFunction<String, Tuple2<String, Long>>() { @Override public Tuple2<String, Long> map(String s) throws Exception { ? String[] split = s.split(","); return new Tuple2<String, Long>(split[0], Long.parseLong(split[1])); } }) .keyBy(0) .window(TumblingEventTimeWindows.of(Time.seconds(5))) .minBy(1) .print(); ? env.execute("WaterMark Test Demo"); ? }
PunctuatedWatermark 水印
这种水印的生成方式 Flink 没有提供内置实现,它适用于根据接收到的消息判断是否需要产生水印的情况,用这种水印生成的方式并不多见。
举个简单的例子,假如我们发现接收到的数据 MyData 中以字符串 watermark 开头则产生一个水印:
data.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks<UserActionRecord>() { ? @Override public Watermark checkAndGetNextWatermark(MyData data, long l) { return data.getRecord.startsWith("watermark") ? new Watermark(l) : null; } ? @Override public long extractTimestamp(MyData data, long l) { return data.getTimestamp(); } }); class MyData{ private String record; private Long timestamp; public String getRecord() { return record; } public void setRecord(String record) { this.record = record; } public Timestamp getTimestamp() { return timestamp; } public void setTimestamp(Timestamp timestamp) { this.timestamp = timestamp; } }
....
以上是关于Flink核心概念的主要内容,如果未能解决你的问题,请参考以下文章