正则注意事项
Posted jiaoyaxiong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了正则注意事项相关的知识,希望对你有一定的参考价值。
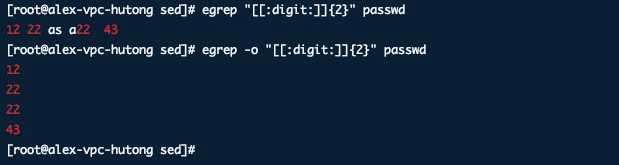
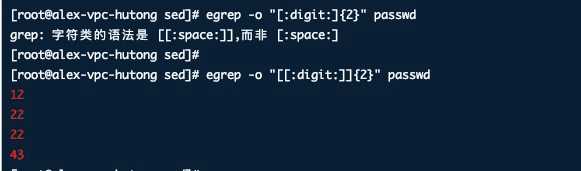
1, -o 仅显示匹配的内容 ,
默认情况下grep显示对应的整行,如果要做统计的话,需要sed去除不要的部分, 但grep提供了仅显示需要的部分, 使sed脚本更简单.
2,元字符
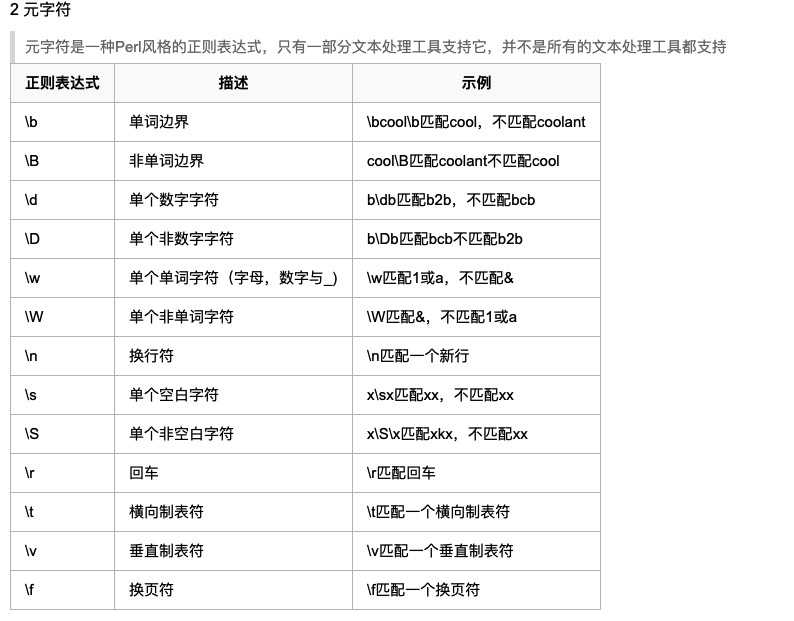
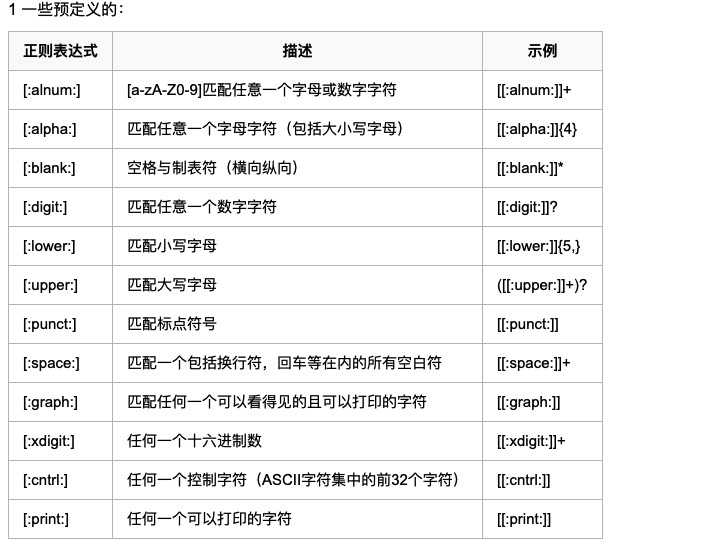
s 单个空白字符
w 单个单词字符 (字母数字下划线)
3,满足多个关键字之一
grep -E "字符串1|字符串2|字符串3|" 文件名 或者
egrep "字符串1|字符串2|字符串3|" 文件名
4,基础语法
Grep 是 Global Regular Expression Print 的缩写,它搜索指定文件的内容,匹配指定的模式,默认情况下输出匹配内容所在的行。注意,grep 只支持匹配而不能替换匹配到的内容。
基本语法
语法格式:
grep [OPTIONS] PATTERN [FILE...]
grep [OPTIONS] [-e PATTERN | -f FILE] [FILE...]
grep 支持不同的匹配模式,比如默认的 BRE 模式,增强型的 ERE 模式,还有更强悍的 PRE 模式。普通情况下使用默认的 BRE(basic regular expression) 模式就可以了,这种方式的特点是支持的正则表达式语法有限。如果需要更进一步的正则表达式语法支持,可以使用 ERE(extended regular expression) 模式。如果要使用复杂的正则表达式语法,可以使用 PRE 模式,它支持 Perl 语言的正则表达式语法。
常用选项:
--help
-V, --version
-G, --basic-regexp BRE 模式,也是默认的模式
-E, --extended-regexp ERE 模式
-P, --perl-regexp PRE 模式
-F, --fixed-strings 指定的模式被解释为字符串
-i 忽略大小写
-o 只输出匹配到的部分(而不是整个行)
-v 反向选择,即输出没有没有匹配的行
-c 计算找到的符号行的次数
-n 顺便输出行号
5, grep -w 表示匹配全词

例如我想匹配 “like”, 不加 -w 就会匹配到 “liker”, 加 -w 就不会匹配到
6,grep -l
如果我们只想查看匹配到的内容所在文件的名称,可以同时使用 r 和 -l, --files-with-matches 选项:
以上是关于正则注意事项的主要内容,如果未能解决你的问题,请参考以下文章