R语言基础-数据分析及常见数据分析方法
Posted nnadd
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R语言基础-数据分析及常见数据分析方法相关的知识,希望对你有一定的参考价值。
R表达式中常用的符号

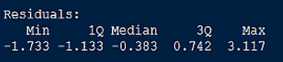
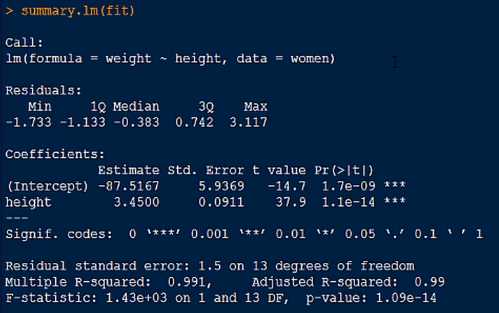
残差(Residuals)
残差是真实值与预测值之间的差,五个分位的值越小模型越精确
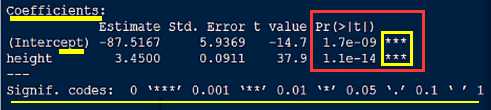
系数项与截距项(Coefficients & Intercept)和P值指标
残差标准误(Residual standard error)
残差的标准误差,越小越好
R方判定系数
模型拟合的质量判定指标,取值在0-1之间,值越大越好
Multiple R-squared: 0.991 表示该模型能解释99.1%的数据。
F统计量(F-statistic)
说明模型是否显著,值越小越好,说明模型越显著
判断模型是否适合的一般规则
先看F统计量是否小于0.05,如果小于0.05,再看R方判定系数。
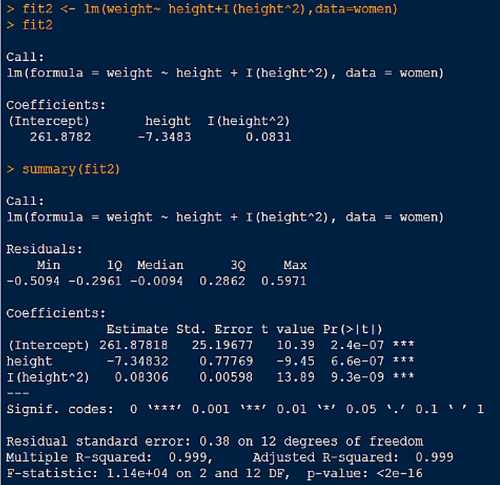
*线性回归(解决一元多次)
回归(regression),通常指那些用一个或多个预测变量,也称自变量或解释变量来预测响应变量,也称为因变量、校标变量或结果变量的方法。
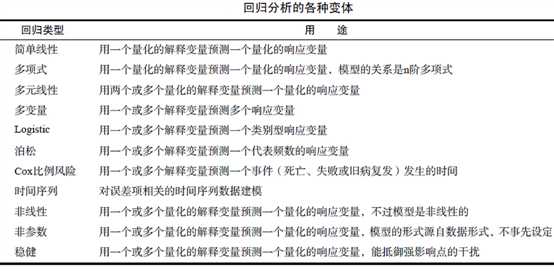
1.回归分析类型
2.普通最小二乘法
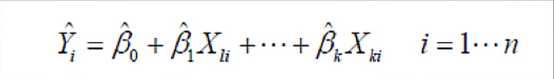

使用women内置数据集
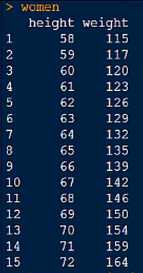
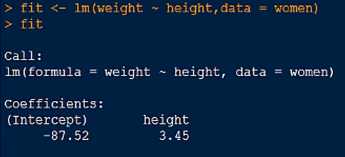
得出体重与身高之间的关系
使用plot(fit)绘制出四幅图(残差拟合图、正态QQ图、方差假设指标图、残差影响图)
使用 par(mfrow = c(2,2)) 可以将四幅图显示在一个窗口中
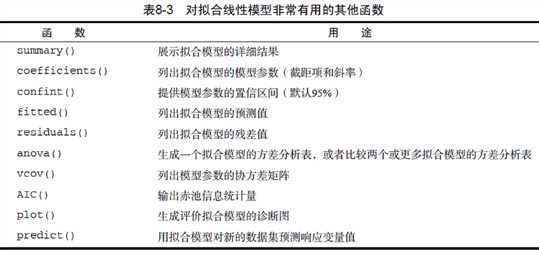
线性拟合常用函数
*多元线性回归
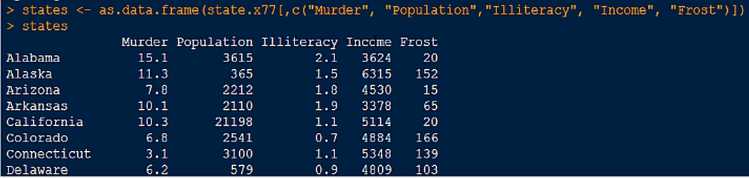
一、变量是相互独立的情况
将state.x77数据集转化为数据框
得出结果
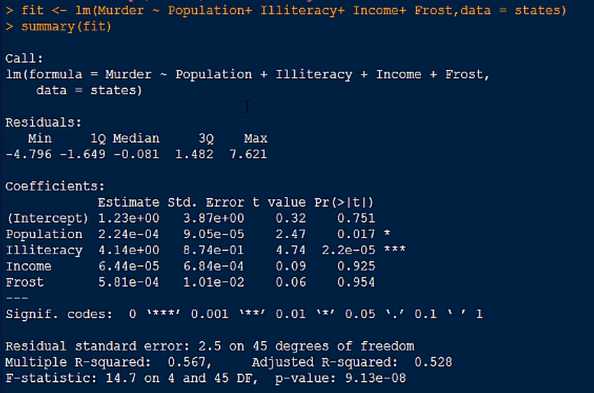

意为在控制人口数量,收入,霜冻天数不变的情况下,文盲率上升1%,谋杀率就会上升4.14%
二、变量不相互独立的情况
使用mtcar内置数据框,选取每加仑汽油行驶的里程数与马力、车重的关系
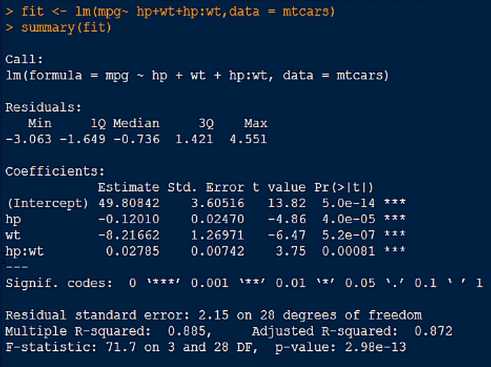
说明每加仑汽油行驶的里程数与汽车马力的关系依赖车重的不同而不同
三、为解决因子数量较多无法确定最佳模型是可使用逐步回归法或者全子集回归法
逐步回归法
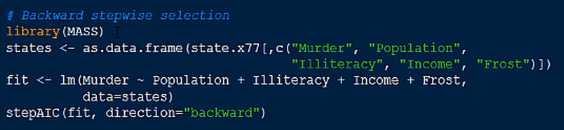
全子集回归法
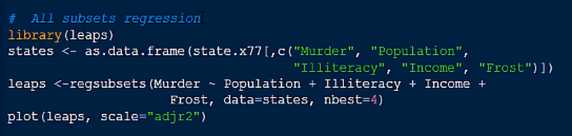
*回归诊断
一、满足OLS模型(最小二乘法)统计假设
1.正态性
对于固定的自变量值,因变量值成正态分布。
2.独立性
因变量之间相互独立
3.线性
因变量与自变量之间为线性相关
4.同方差性
因变量的方差不随自变量的水平不同而变化。也可称作不变方差。
二、抽样法验证模型契合度
1.数据集中有1000个样本,随机抽取500个数据进行回归分析;
2.模型建好之后,利用predict函数,对剩余500个样本进行预测,比较残差值
3.如果预测准确,说明模型可以,否则就需要调整模型
*方差分析
方差分析,称为Analysis of Variance,简称ANOVA ,也称为"变异数分析”, 用于两个及两个以上样本均数差别的显著性检验。从广义上来讲,方差分析也属于回归分析的一-种。只不过线性回归的因变量一-般是连续型变量。而当自变量是因子时,研究关注的重点通常会从预测转向不同组之间差异的比较。这就是方差分析。
一、R中因子的应用
计算频数
独立性检验
相关性检验
方差分析
主成分分析
因子分析
...
二、方差分析的种类
单因素方差分析ANOVA (组内,组间)
双因素方差分析ANOVA
协方差分析ANCOVA
多元方差分析MANOVA
多元方差分析MANCOVA
三、方差分析公式中特殊符号

四、各种方差分析公式写法

五、书写顺序

*功效分析
功效分析, power analysis,可以帮助在给定置信度的情况下,判断检测到给定效应值时所需的样本量。反过来,它也可以在给定置信度水平情况下,计算在某样本量内能检测到给定效应值的概率。
一、功效分析函数
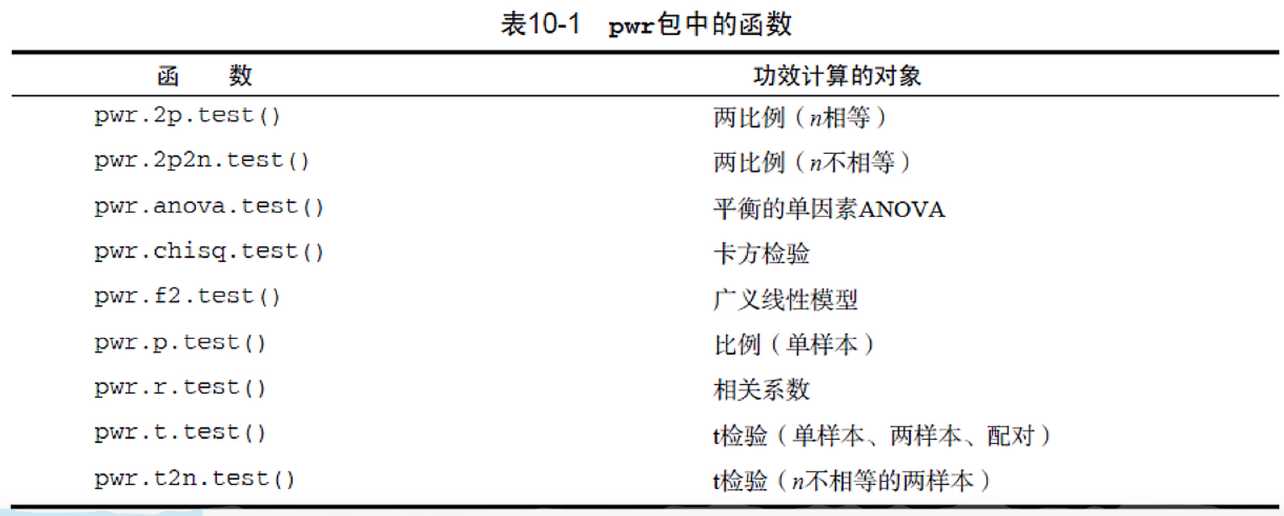
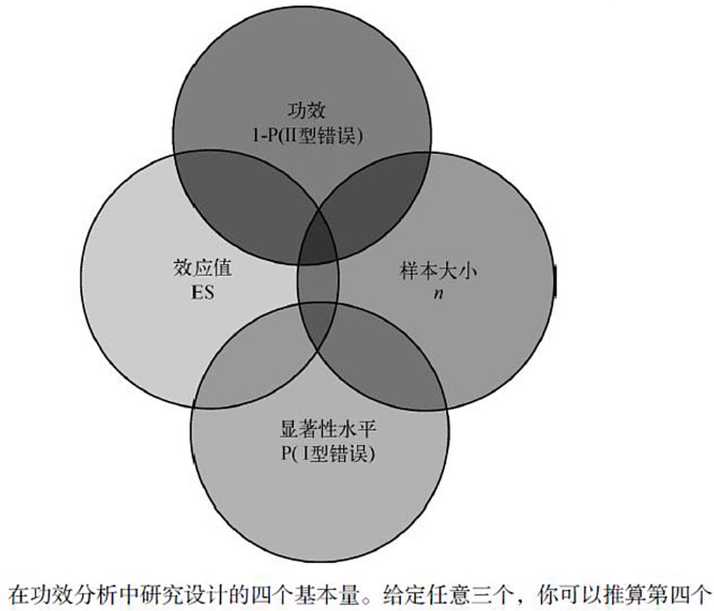
二、功效分析理论基础

●样本大小指的是实验设计中每种条件/组中观测的数目。
●显著性水平 (也称为alpha )由型错误的概率来定义。也可以把它看做是发现效应不发生的概率。
●功效通过I减去I型错误的概率来定义。我们可以把它看做是真实效应发生的概率。
●效应值指的是在备择或研究假设 下效应的量。效应值的表达式依赖于假设检验中使用的统计方法。
*广义线性模型
线性回归和方差分析都是基于正态分布的假设,广义线性模型扩展了线性模型的框架,它包含了非正态因变量的分析。
泊松回归
泊松回归是用来为计数资料和列联表建模的一种回归分析。泊松回归假设因变量是泊松分布,并假设它的平均值的对数可被未知参数的线性组合建模。
*Logisti回归
当通过一系列连续型或类别型预测变量来预测二值型结果变量时,Logistic回归效果会很好
Logistic回归案例
根据危险因素预测某疾病发生的概率。例如,想探讨胃癌发生的危险因素,可以选择两组人群,一组是胃癌组,一组是非胃癌组,两组人群肯定有不同的体征和生活方式等。这里的因变量就是是否胃癌,即是”或“否”,为两分类变量,自变量就可以包括很多了,例如年龄、性别、饮食习惯、幽门]螺杆菌感染等。自变量既可以是连续的, 也可以是分类的。通过logistic回归分析 ,就可以大致了解到底哪些因素是胃癌的危险因素。
*主成份分析
主成分分析,Principal Component Analysis,也简称为PCA,是一种数据降维技巧,它能将大量相关变量转化为一组很少的不相关变量,这些无关的变量称为主成分。主成分其实是对原始变量重新进行线性组合将原先众多具有一定相关性的指标,重新组合为一组的新的相互独立的综合指标。
一、主成份分析模型图
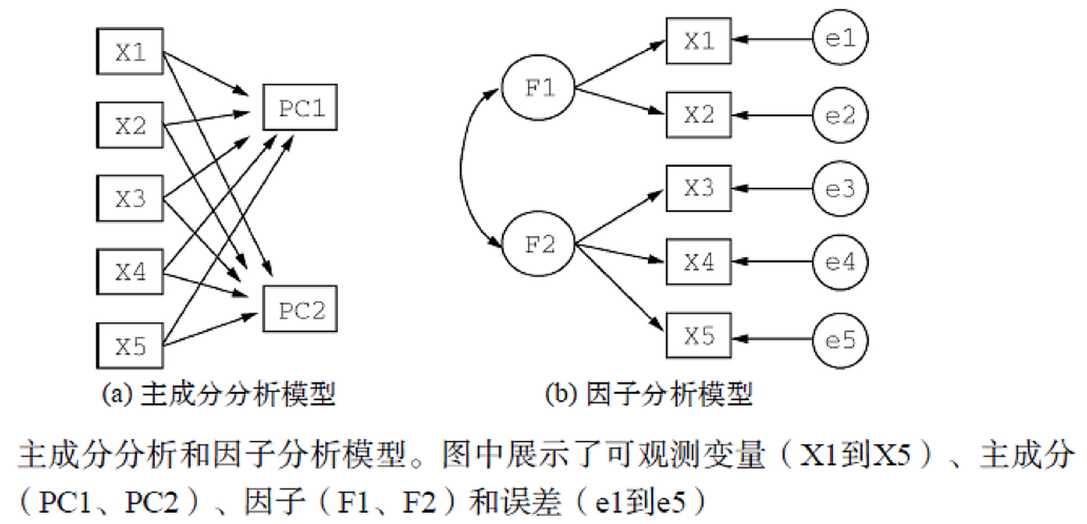
二、主成份分析公式
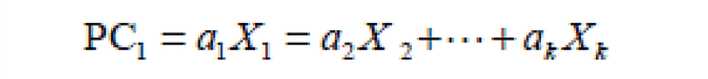
三、主成份分析与因子分析步骤
●数据预处理;
●选择分析模型;
●判断要选择的主成分/因子数目;
●选择主成分/因子;
●旋转主成分/因子;
●解释结果;
●计算主成分或因子得分。这步也是可选的。
*因子分析
探索性因子分析法Exploratory Factor Analysis,简称为EFA,是一系列用来发现一组变量的潜在结构的方法。它通过寻找一组更小的、 潜在的或隐藏的结构来解释已观测到的、显式的变量间的关系。
因子分析公式
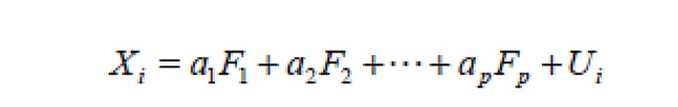
*购物篮分析
1.安装arules包,加载Grocerises内置购物篮数据集
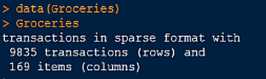
inspect(Grocerises)查看数据集
2.使用apriori()函数进行建模
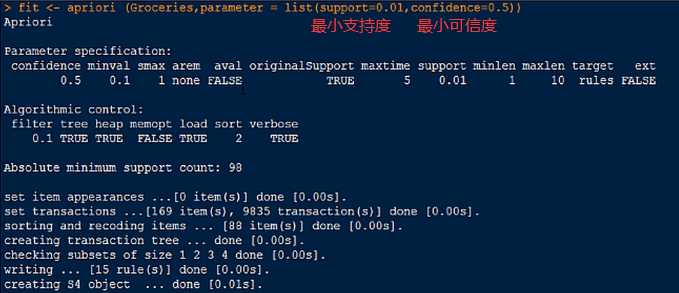
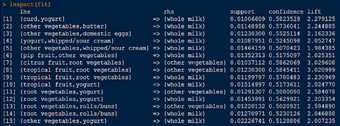
3.inspect()函数查看具体结果
以上是关于R语言基础-数据分析及常见数据分析方法的主要内容,如果未能解决你的问题,请参考以下文章