[爬虫框架scrapy]爬虫文件的创建
Posted liangritian
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[爬虫框架scrapy]爬虫文件的创建相关的知识,希望对你有一定的参考价值。
新建爬虫项目非常有必要,虽然可以自己手动创建但还是最好用官方推荐的方法来新建爬虫
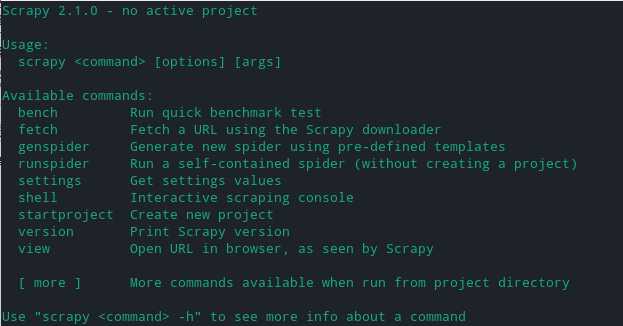
- 终端输入scrapy -h查看scrapy 命令的用法
- 输入scrapy startproject Youspider 新建一个爬虫
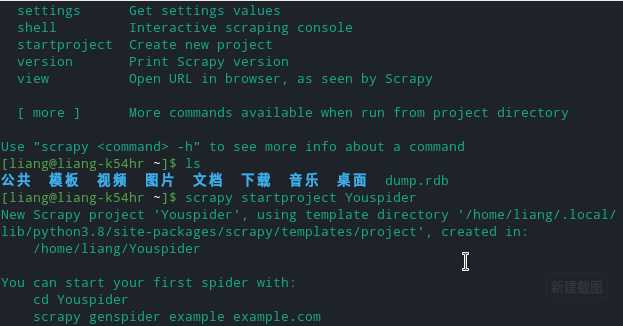
- 可以看到下一步该干嘛scrapy 都帮你提示好了
- 终端输入cd Youspider
- 在这目录下创建爬虫文件,注意爬虫名不可与爬虫项目同名且该名字是唯一的
- 终端输入scrapy genspider youspider www.baidu.com
- 创建成功,youspider为爬虫名字,www.baidu.com为要爬取网站的域名
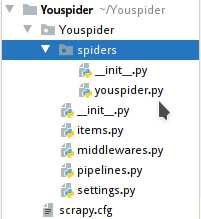
用pycharm可以看到爬虫文件如上
- youspider为爬虫文件,我们大部分时间都会编辑这个文件
- items为定义结构化数据,我们定义要爬取的字段
- middlewares为中间件,我们一般会在这里修改请求头,代理ip,cookie等
- pipelines为管道文件,爬虫会返回要爬取的数据,交给管道处理要爬取的数据
- setting为配置文件,控制爬虫线程数,爬取速度,定义全局请求头,开启中间件,开启管道,开启扩展等
- scrapy.cfg这个在部署爬虫时会用到
以上是关于[爬虫框架scrapy]爬虫文件的创建的主要内容,如果未能解决你的问题,请参考以下文章