后处理对比多工况的差异总结
Posted liusuanyatong
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了后处理对比多工况的差异总结相关的知识,希望对你有一定的参考价值。
有时候我们在计算完多个工况以后需要对比不同工况的差异,在CFD-Post当中可以使用case comparison来完成这个操作,但是CFD-Post主要是针对CFX和Fluent的后处理,对于其他软件的计算结果可使用Ensight或者ParaView来实现类似CFD-Post当中的case comparison功能。
ParaView的操作方法如下:
打开ParaView 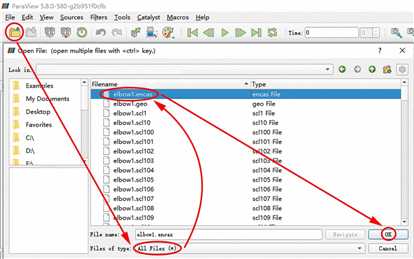
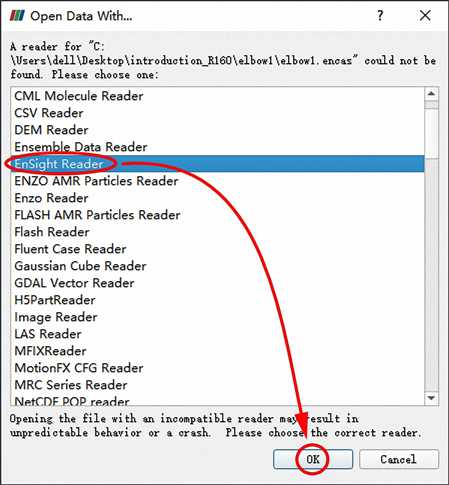
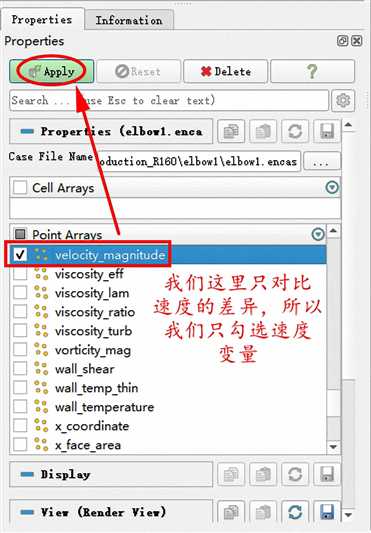
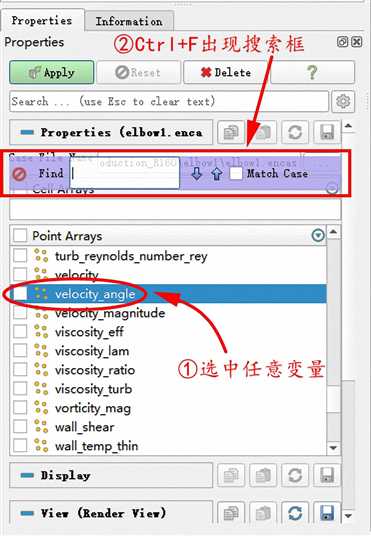
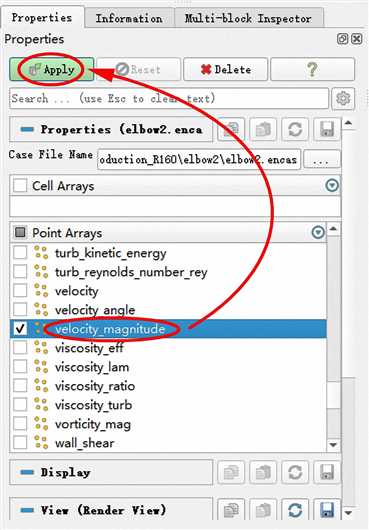
注:一点小技巧,如果导入计算结果文件以后,变量较多,我们想要查找某一个变量,直接滚动滑动条的方式查找起来很费劲,我们可以选中任意一个变量,然后在键盘上输入Ctrl+F,就会出现搜索框,如下图所示,就可以很方便的搜索我们想要的变量
重复上面的步骤,导入计算完成的第二个工况 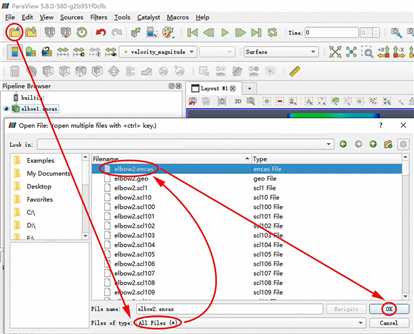
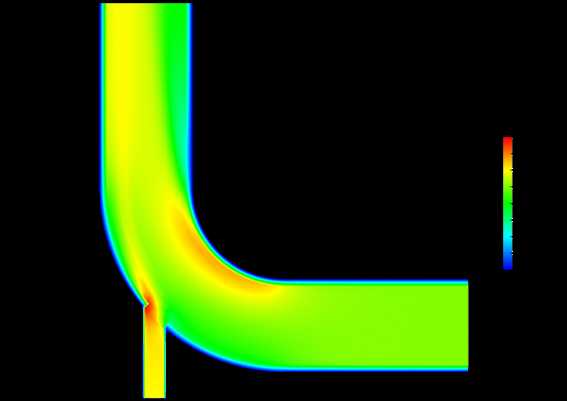
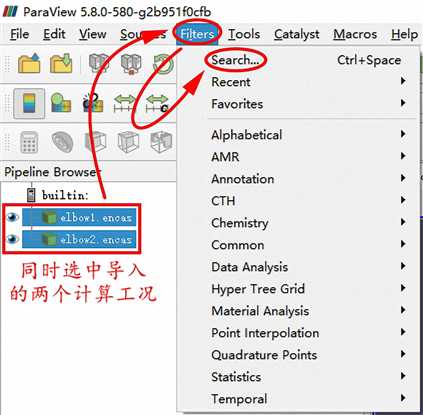
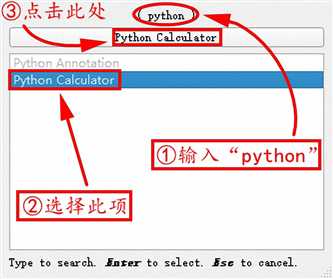
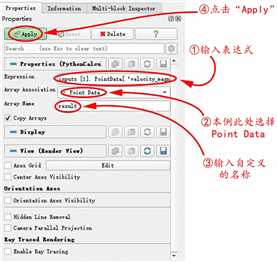
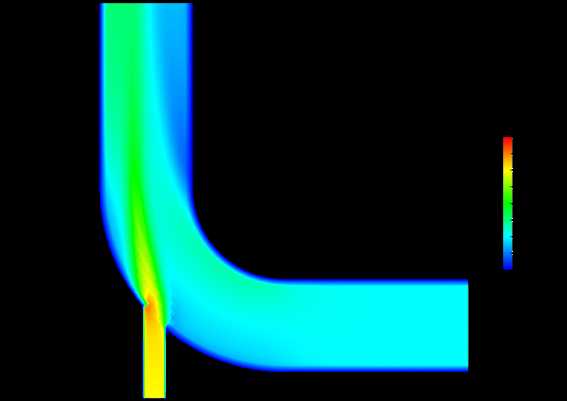
表达式为inputs[1].PointData[‘velocity_magnitude’]-inputs[0].PointData[‘velocity_magnitude’]
注:Array Association提供了一下选择
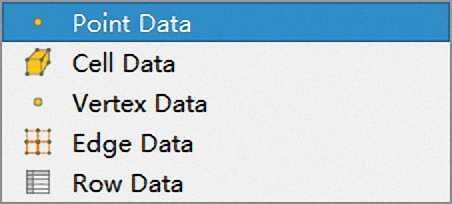
如果数据存储在网格节点上,则应该选择Point Data
如果数据存储在网格中心上,则应该选择Cell Data
如果数据存储在网格节点上,则表达式就应该是PointData,如果数据存储在网格单元中心,则表达式为CellData,如果数据存储在网格节点上而想使用CellData,ParaView提供了Point Data to Cell Data过滤器来将网格节点的数据转换为单元中心的数据,反之亦然,ParaView也提供了Cell Data to Point Data将网格中心数据转换为网格节点数据。表达式中的索引值为数据导入时选定的变量名。
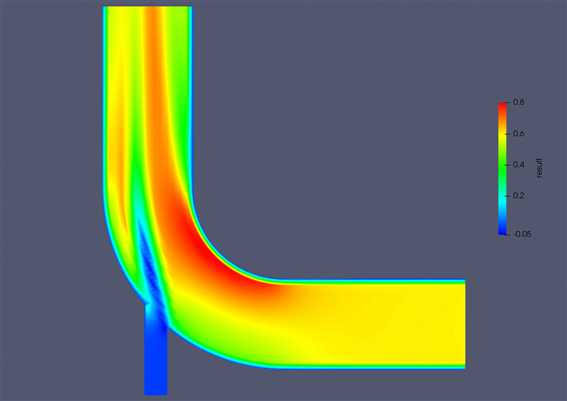
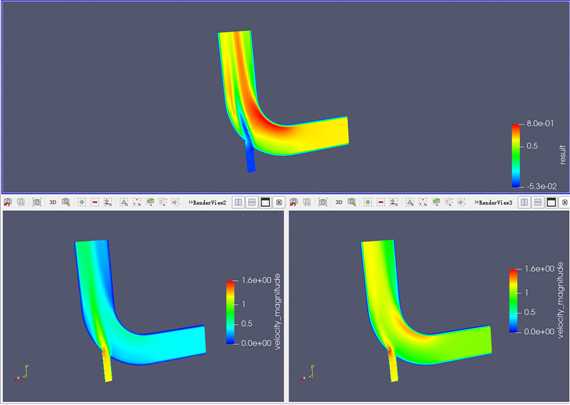
我们可以将显示窗口分为三部分,分别显示两个工况和两个工况差异的视图

相关文件下载链接:
https://pan.baidu.com/s/1F_gUqjIIKHiO5OKjNegtRA
提取码: uiy3
以上是关于后处理对比多工况的差异总结的主要内容,如果未能解决你的问题,请参考以下文章