Map家族前来踢馆
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Map家族前来踢馆相关的知识,希望对你有一定的参考价值。
老List讲完了家族的荣耀,再看看各有所长的子孙们,不由得满脸幸福。不过老Map的一个小问题就让它的幸福变成了假笑。
“现在有个需求,让你把一个学生的10门考试成绩传给别人,怎么实现”?老Map认真地问道。这也太简单了,老List心理想着,于是回答道:“让ArrayList装上这10门成绩送过去不就行了”。
“但是接收者如何把这10个成绩和10个科目对应起来呢,他怎么会知道谁是谁呢”?老Map提出了质疑。老List心理暗暗想到,来着不善呢。不过还是赶紧解释道:“这个肯定要提前规定好,每个位置(序号)是什么成绩,要么写一个文档,要么注释在代码里”。
看到老List的回答勉强自圆其说,老Map还是决定再补一刀,于是道:“如果碰到粗心的开发者,搞错了顺序,几乎很难发现,因为成绩都是数字,并没有什么区别”。老List叹道:“确实是这样子,容易出问题的概率会大些,且不易发觉。敢问阁下有什么高见呢”?
“你的这种情况,可以认为是语义不够丰富”,老Map说到,“你应该在传成绩的时候,把科目名称和它放到一起,一并传过去,这样就大大降低了用户的出错概率”。
老List听着觉得很有道理,但由于没见过,思维受限,一时无法想象出来。于是说到:“老夫孤陋寡闻了,还请阁下明示”。老Map撸了撸袖子,伸出两只手,“啪啪”拍了两下,HashMap闪亮登场了。
HashMap熟悉地展示着自己的武艺,先添加元素,再访问元素,最后遍历元素,除此之外,还可以获取key的集合和value的集合。一套常规的组合拳打下来,把老List看的是双眼发光,连连称赞。不过老List毕竟是外行,只能看个热闹,看不出门道。所以有很多不解,如你底层是怎么存储的啊,访问某个元素的时候是根据key一个个比对吗?等等。
HashMap面对机关枪式的追问,咬咬牙咽了咽口水,心想这老头儿是从火星来的吧,怎么啥都不知道到啊。于是耐心地解说,我内部首先要有一个“节点”这样的东西,它同时存储key和value,这样就把它们关联成一对了。然后再把这些节点放到一个数组里面。
“数组是基于索引的,但是这些节点啊,key和value啊,跟索引没有半毛钱关系,怎么放啊”?老List又问道。不可否认这老头思维敏捷,总是能捕捉到问题的关键部分,给出一击。HashMap答道:“你瞅瞅我的名字,哈希Map,这个哈希就是关键,你听说过哈希吗”?老List说到:“哈希到没听过,不过听说过康熙”。
HashMap继续它的解说,哈希就是把一个字符串或对象转变成一个整数的过程,不过它有一个要求,就是相同的字符串或对象每次哈希后的整数必须一样,不同的字符串或对象哈希后的整数尽量都不一样。它还有一个特点,就是反过来计算几乎很难实现,如给你一个数字,让你算出它是哪个字符串哈希后的值。
老List捋捋胡子,听的很过瘾。问道:“哈希值既然是整数,但是整数的范围很大啊,怎么和你底层数组的索引对应起来呢,莫非采用求模(求余)”?HashMap感慨啊,姜还是老的辣呀。继续道,确实是拿哈希值对数组长度求余,余数即为索引,然后把节点放进去。
老List自言自语道:“取元素时,先根据key求出哈希值,再对数组长度求余得到索引,再由数组进行基于索引的访问,由于现在CPU执行指令的速度飞快,所以这其实就是常量时间访问”。HashMap的心哇凉哇凉的,这老头都会抢答了。
老List的眼珠转了转问道:“你刚才说,不同的字符串或对象哈希后的整数尽量不一样,那要是一样了,咋办呢,或者整数不一样,但是对数组长度求余后的余数一样”?哎呀,这真是老奸巨猾啊。HashMap抓了抓头皮,答道:“你说的这样情况是存在的,还有个专门的术语,叫哈希碰撞,其实有好几种处理方法,我这里选择比较简单的一种。就是求余后的索引位置已经被某个节点占了,那新节点就挂到它下面,形成一个节点链表,这样这个链表上的所有节点共用数组的这个索引”。
“节点链表,那不是和我的子孙LinkedList一样吗”?老List说到。HashMap赶紧解开扣子,低头瞄了瞄,确实很像。继续解说道,访问元素时,从key到索引这个过程还是一样的,然后根据索引取出节点,如果这个节点只有自己,那就返回它存储的value。如果节点其实是一个链表,那就依次遍历链表,比较key是否相等,然后返回和该key相等的那个链表节点存储的value。
老List心想,Map这种东西可真够复杂的,不过它还不打算收手。于是又问道:“那这样处理的话,访问速度肯定会随着链表的长度(碰撞次数)增加而下降,有没有什么优化方案”?这问题真是针针见血,HashMap在心里为自己捏把汗,要是没有两把刷子,还真搞不定了。
HashMap慢慢说到,首先肯定和哈希函数有关,但它的优化比较困难,一般人真搞不定。其次也和底层数组长度有关,如果长度很长,是不是有种地广人稀的感觉,半天都碰不到一个人,如果长度很短的话,是不是很容易挤到一起,极端情况,长度为1时,是不是所有元素都撞到一起了。所以在碰撞达到一定程度时,我会扩容底层数组,使其长度增加,这样所有的节点再对新长度求一遍余数,重新找到自己的位置,元素再次变得松散起来。这个过程在教科书上称为rehash(重哈希)。
“假如底层数组不让扩容,或扩容后效果不佳,还有其它优化方案吗”?老List斤斤计较道。HashMap使出吃奶的劲儿,解说到,还可以在到达某种情况下,把节点链表进行树化,根据哈希值的大小,转变成一个红黑树(red-black tree),这样查找的平均次数由链表的长度变为了树的高度,专业(装B)一点的说法是由O(n)变为O(log(n))。
看到老List又要发问,HashMap大呼,大爷啊,您别问了,臣妾做不到了啊。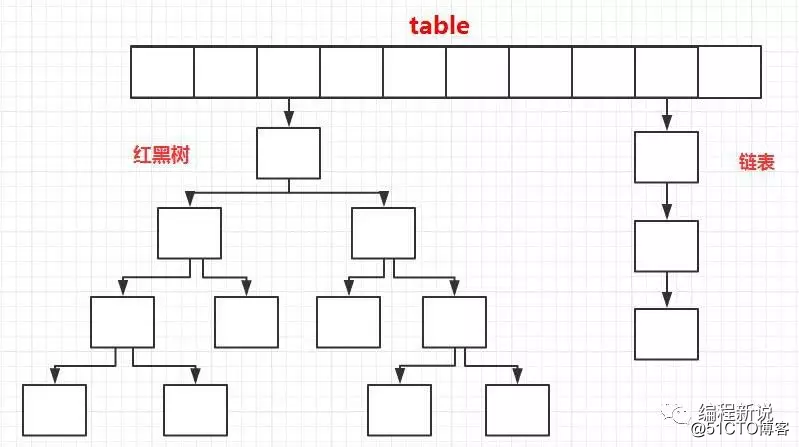
(注:图片来自网络)
作者心声:感觉写着写着,怎么变成List踢Map啦,哎,算了,文章没有彩排,都是临时现攒。
(完)
以上是关于Map家族前来踢馆的主要内容,如果未能解决你的问题,请参考以下文章