Spark存储Parquet数据到Hive,对maparraystruct字段类型的处理
Posted bigdatalearnshare
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark存储Parquet数据到Hive,对maparraystruct字段类型的处理相关的知识,希望对你有一定的参考价值。
利用Spark往Hive中存储parquet数据,针对一些复杂数据类型如map、array、struct的处理遇到的问题?
为了更好的说明导致问题的原因、现象以及解决方案,首先看下述示例:
-- 创建存储格式为parquet的Hive非分区表 CREATE EXTERNAL TABLE `t1`( `id` STRING, `map_col` MAP<STRING, STRING>, `arr_col` ARRAY<STRING>, `struct_col` STRUCT<A:STRING,B:STRING>) STORED AS PARQUET LOCATION ‘/home/spark/test/tmp/t1‘; -- 创建存储格式为parquet的Hive分区表 CREATE EXTERNAL TABLE `t2`( `id` STRING, `map_col` MAP<STRING, STRING>, `arr_col` ARRAY<STRING>, `struct_col` STRUCT<A:STRING,B:STRING>) PARTITIONED BY (`dt` STRING) STORED AS PARQUET LOCATION ‘/home/spark/test/tmp/t2‘;
分别向t1、t2执行insert into(insert overwrite..select也会导致下列问题)语句,列map_col都存储为空map:
insert into table t1 values(1,map(),array(‘1,1,1‘),named_struct(‘A‘,‘1‘,‘B‘,‘1‘)); insert into table t2 partition(dt=‘20200101‘) values(1,map(),array(‘1,1,1‘),named_struct(‘A‘,‘1‘,‘B‘,‘1‘));
t1表正常执行,但对t2执行上述insert语句时,报如下异常:
Caused by: parquet.io.ParquetEncodingException: empty fields are illegal, the field should be ommited completely instead
at parquet.io.MessageColumnIO$MessageColumnIORecordConsumer.endField(MessageColumnIO.java:244)
at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.writeMap(DataWritableWriter.java:241)
at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.writeValue(DataWritableWriter.java:116)
at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.writeGroupFields(DataWritableWriter.java:89)
at org.apache.hadoop.hive.ql.io.parquet.write.DataWritableWriter.write(DataWritableWriter.java:60)
... 23 more
t1和t2从建表看唯一的区别就是t1不是分区表而t2是分区表,仅仅从报错信息是无法看出表分区产生这种问题的原因,看看源码是做了哪些不同的处理(这里为了方便,笔者这里直接给出分析这个问题的源码思路图):
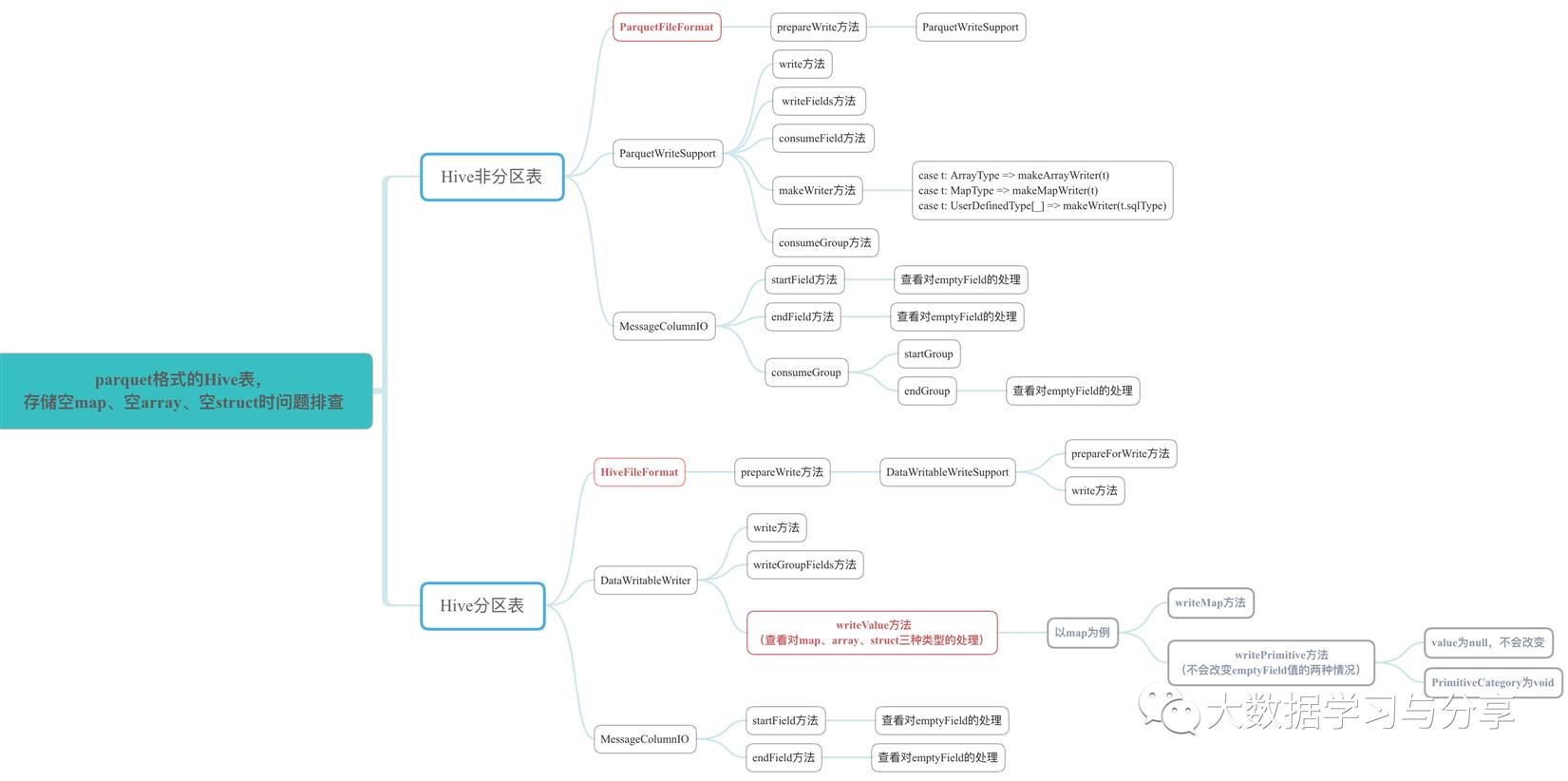
t1底层存储指定的是ParquetFilemat,t2底层存储指定的是HiveFileFormat。这里主要分析一下存储空map到t2时,为什么出问题,以及如何处理,看几个核心的代码(具体的可以参考上述源码图):
从抛出的异常信息empty fields are illegal,关键看empty fields在哪里抛出,做了哪些处理,这要看MessageColumnIO中startField和endField是做了哪些处理:
public void startField(String field, int index) {
try {
if (MessageColumnIO.DEBUG) {
this.log("startField(" + field + ", " + index + ")");
}
this.currentColumnIO = ((GroupColumnIO)this.currentColumnIO).getChild(index);
//MessageColumnIO中,startField方法中首先会将emptyField设置为true
this.emptyField = true;
if (MessageColumnIO.DEBUG) {
this.printState();
}
} catch (RuntimeException var4) {
throw new ParquetEncodingException("error starting field " + field + " at " + index, var4);
}
}
//endField方法中会针对emptyField是否为true来决定是否抛出异常
public void endField(String field, int index) {
if (MessageColumnIO.DEBUG) {
this.log("endField(" + field + ", " + index + ")");
}
this.currentColumnIO = this.currentColumnIO.getParent();
//如果到这里仍为true,则抛异常
if (this.emptyField) {
throw new ParquetEncodingException("empty fields are illegal, the field should be ommited completely instead");
} else {
this.fieldsWritten[this.currentLevel].markWritten(index);
this.r[this.currentLevel] = this.currentLevel == 0 ? 0 : this.r[this.currentLevel - 1];
if (MessageColumnIO.DEBUG) {
this.printState();
}
}
}
针对map做处理的一些源码:
private void writeMap(final Object value, final MapObjectInspector inspector, final GroupType type) {
// Get the internal map structure (MAP_KEY_VALUE)
GroupType repeatedType = type.getType(0).asGroupType();
recordConsumer.startGroup();
recordConsumer.startField(repeatedType.getName(), 0);
Map<?, ?> mapValues = inspector.getMap(value);
Type keyType = repeatedType.getType(0);
String keyName = keyType.getName();
ObjectInspector keyInspector = inspector.getMapKeyObjectInspector();
Type valuetype = repeatedType.getType(1);
String valueName = valuetype.getName();
ObjectInspector valueInspector = inspector.getMapValueObjectInspector();
for (Map.Entry<?, ?> keyValue : mapValues.entrySet()) {
recordConsumer.startGroup();
if (keyValue != null) {
// write key element
Object keyElement = keyValue.getKey();
//recordConsumer此处对应的是MessageColumnIO中的MessageColumnIORecordConsumer
//查看其中的startField和endField的处理
recordConsumer.startField(keyName, 0);
//查看writeValue中对原始数据类型的处理,如int、boolean、varchar
writeValue(keyElement, keyInspector, keyType);
recordConsumer.endField(keyName, 0);
// write value element
Object valueElement = keyValue.getValue();
if (valueElement != null) {
//同上
recordConsumer.startField(valueName, 1);
writeValue(valueElement, valueInspector, valuetype);
recordConsumer.endField(valueName, 1);
}
}
recordConsumer.endGroup();
}
recordConsumer.endField(repeatedType.getName(), 0);
recordConsumer.endGroup();
}
private void writePrimitive(final Object value, final PrimitiveObjectInspector inspector) {
//value为null,则return
if (value == null) {
return;
}
switch (inspector.getPrimitiveCategory()) {
//PrimitiveCategory为VOID,则return
case VOID:
return;
case DOUBLE:
recordConsumer.addDouble(((DoubleObjectInspector) inspector).get(value));
break;
//下面是对double、boolean、float、byte、int等数据类型做的处理,这里不在贴出
....
可以看到在startFiled中首先对emptyField设置为true,只有在结束时比如endField方法中将emptyField设置为false,才不会抛出上述异常。而存储字段类型为map时,有几种情况会导致这种异常的发生,比如map为空或者map的key为null。
这里只是以map为例,对于array、struct都有类似问题,看源码HiveFileFormat -> DataWritableWriter对这三者处理方式类似。类似的问题,在Hive的issue中https://issues.apache.org/jira/browse/HIVE-11625也有讨论。
分析出问题解决就比较简单了,以存储map类型字段为例:
1. 如果无法改变建表schema,或者存储时底层用的就是HiveFileFormat
如果无法确定存储的map字段是否为空,存储之前判断一下map是否为空,可以写个udf或者用size判断一下,同时要保证key不能为null
2. 建表时使用Spark的DataSource表
-- 这种方式本质上还是用ParquetFileFormat,并且是内部表,生产中不建议直接使用这种方式 CREATE TABLE `test`( `id` STRING, `map_col` MAP<STRING, STRING>, `arr_col` ARRAY<STRING>, `struct_col` STRUCT<A:STRING,B:STRING>) USING parquet OPTIONS(`serialization.format` ‘1‘);
3. 存储时指定ParquetFileFormat
比如,ds.write.format("parquet").save("/tmp/test")其实像这类问题,相信很多人都遇到过并且解决了。这里是为了给出当遇到问题时,解决的一种思路。不仅要知道如何解决,更要知道发生问题是什么原因导致的、如何避免这种问题、解决了问题是怎么解决的(为什么这种方式能解决,有没有更优的方法)等。
近期文章:
Spark SQL解析查询parquet格式Hive表获取分区字段和查询条件
关注微信公众号:大数据学习与分享,获取更对技术干货
以上是关于Spark存储Parquet数据到Hive,对maparraystruct字段类型的处理的主要内容,如果未能解决你的问题,请参考以下文章