视频教程|高质量数据库建模之数据模型规范化:一二三范式知多少!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频教程|高质量数据库建模之数据模型规范化:一二三范式知多少!相关的知识,希望对你有一定的参考价值。
正文开始:
时光荏苒,本课已经出了近半年,到今天(2016-6-26)为止,一共有1413名观众,非常感谢大家能有耐心听我的课。
课程地址:http://www.hellobi.com/course/54
此外,希望大家听完课以后去https://www.surveymonkey.com/r/CYQLCTD 填写一下调查问卷,我也好有的放矢,对于我教的不好的地方做调整和改善。
这节课我们来讲数据库的规范化(也就是Normalization).规范化呢,其实有很多人都讲过了,网上随处可见,天善也有这样的视频。 但实在不好意思,这个还是出于本人的私心,希望自己的课程内容能够完整,因为毕竟规范化是数据库设计中非常重要的一个组成部分。
那规范化是什么啊?它其实就是一个设计过程,在这个设计过程中呢,尽可能的让数据库的冗余最小。什么是冗余最小啊?就是说尽可能的同样含义的数据只存一份。这样有什么好处呢?当插入新数据的时候,就插一个表就行了,不用几个表都要处理,同样的,修改和删除也是如此,就改一个删一个就行了,不用所有的都处理,这样呢就能保证数据的一致性。还有就是把数据之间的关系,用表关联的方式体现出来,而不是用数据的内容来体现。这样就不会出现数据丢失的问题。这里举个例子,比如你只有一张员工表,然后表里有个部门的字段,但你没单独建部门表。这样如果某个部门只有一个员工,而你又把这条员工的记录删了,虽然部门没人了,但这个部门还存在啊,但因为你没有部门表,是不是这么弄一下这个部门的信息也就都没有了?
关系型数据库理论里面有一堆范式,第一范式,第二范式,第三范式,BC范式(也称为3.5范式),第四范式,第五范式,好像还有第六范式,但这个第六范式我还真不知道。这些范式呢,都是一级一级来的,第二范式必须以第一范式为基础,第三范式必须以第二范式为基础,以此类推。一般情况下呢,我们设计就是第三范式为止,可能为了性能考虑还要做很多逆规范化。我前面的课程也曾经讲过,要先规范化,再逆规范化,不能一步到位。当时还举了一个例子,就是德国奔驰车的一个操作规范,拧螺丝要先顺时针拧四圈(这个就是规范化),再逆时针拧半圈(这个就是逆规范化),不能直接拧三圈半,一样的道理。
这个关系型数据库之父,艾德拉考特,曾经说过这么一段话,“Each non-primary key value MUST be dependent on the key, the wholekey, and nothing but the key”。
我简单翻译了一下,说”每一个非键值属性必须依赖于键,依赖于整个键而不是键的一部分,并且,不依赖于其他非键值属性“,这段话虽然不是非常完整,但也基本上把第一范式第二范式第三范式的内容表述出来了。
首先,每一个非键值属性必须依赖于键,这个就是第一范式的基本内容,当然不是很全,我待会再讲细节。然后,依赖于整个键,而不是键的一部分,这个就是第二范式的基本内容。接下来,不依赖于其他非键值属性,这个就是第三范式的基本内容。
我们读书的时候讲规范化都是讲关系代数,什么集合,什么闭包,什么码、超码之类的。说实话,这玩意我做数据库建模都有10多年了,你跟我讲范式我都能懂,关系代数是真不懂,我也编不下去。所以,这里呢,我们就是从实战出发,用例子去讲这些各个范式的含义和内容。
我前面的课里也讲过,经过调查,数据建模工程师最重要的特质是什么啊?是对业务的了解。好像规范化这种技能连前三都没排上,好像是第四。但这里我要说的是,对业务的了解为什么重要?是让数据库建模工程师能够快速准确的把握需求,这样设计出来的表不会出现逻辑上的错误。而实际上,规范化这种技能,是能够帮助建模工程师去理解数据,去理解需求的。
整个规范化的过程是什么啊?甚至整个数据库设计的基本过程是什么啊?其实就是做好分门别类,什么东西该放哪去放哪去。牛吃草,猫吃鱼,奥特曼打小怪物。你把牛的属性放牛身上,猫的属性放猫身上,奥特曼的属性放奥特曼身上,其实所谓规范化就是这么回事。
关系型数据库建模中,规范化设计实际上是个求精的过程,也就是说呢,在规范化之前,有很多工作要做,实际设计中已经把数据库表的骨骼框架搭出来了,规范化就是往框架中填加血肉的过程。那么规范化设计之前都要做哪些工作呢?基本上都是概念模型阶段做的事情,按业务流程模块区分主题,然后在每个主题中按我前面课程介绍的,把名词列出来,看看哪些是实体哪些是属性,然后列出实体,再根据动词勾勒出实体之间的关系,同时呢,比概念模型更进一部,需要尽可能的消除多对多的关系,再列出所有属性,看看这些属性都放哪些实体里面,这些个工作都做差不多了,再开始规范化设计。
那么终于进入正题了,我们先来看看第一范式。第一范式强调的是数据的原子性,也就是说每一列数据没有重复也不可再分,并且没有重复行。这个是关系型数据库最基础的范式。
第一范式要做五件事:
- 要把数据规整成二维表格,也就是用EXCEL能放进去的。
- 第二件事是, 确保每个字段所表述的内容是一致的.
- 第三件事是, 去掉重复组,重复组需要单列出来,创建新的表
- 第四件事是, 保证每列的原子性, 一个字段就装一个数据
- 第五件事是, 保证每行的原子性, 也就是为表增加主键, 确保非主键属性都依赖于主键
下面,让我们逐条的看,这五件事都怎么做。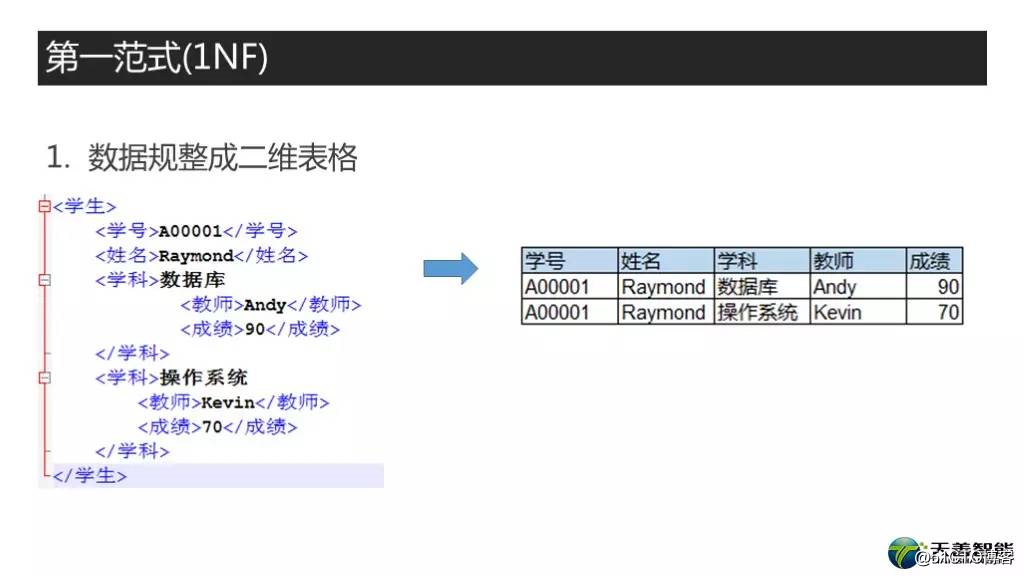
让我们来看第一件事,数据必须是二维的。
我这里说一下,我这个课还是指传统的关系型数据库设计,有些数据库已经能够支持更复杂的数据结构,这种的不在我的课程范围之内。
我们先来看第一件事,就是规整文件格式成二维的。也就是说类似EXCEL那种的行列形式。
在关系型数据库里面,表里的各个列都是平行的,处于同一个层级,和XML,JSON这种类型的格式不同,它是不支持父子结构的。像一些NOSQL数据库,比如MongoDB, 还有一些支持网状结构的数据库比如NEO4J,这些模式的数据结构关系型数据库不是很方便实现的。如果你非得要装到关系型数据库里,就要想其他特别的办法,这个暂时我们先不讲。但无论怎样,都是要先转换成二维的平面格式的。比如我这里举的例子,XML模式下的父子结构需要做调整,变换成二维平面模式。 这个在搜集需求的时候, 很多时候我们是拿不到平面文件的, 都是需要重新整理格式的. 这个其实属于规范化前的准备工作, 我姑且放到第一范式的内容里. 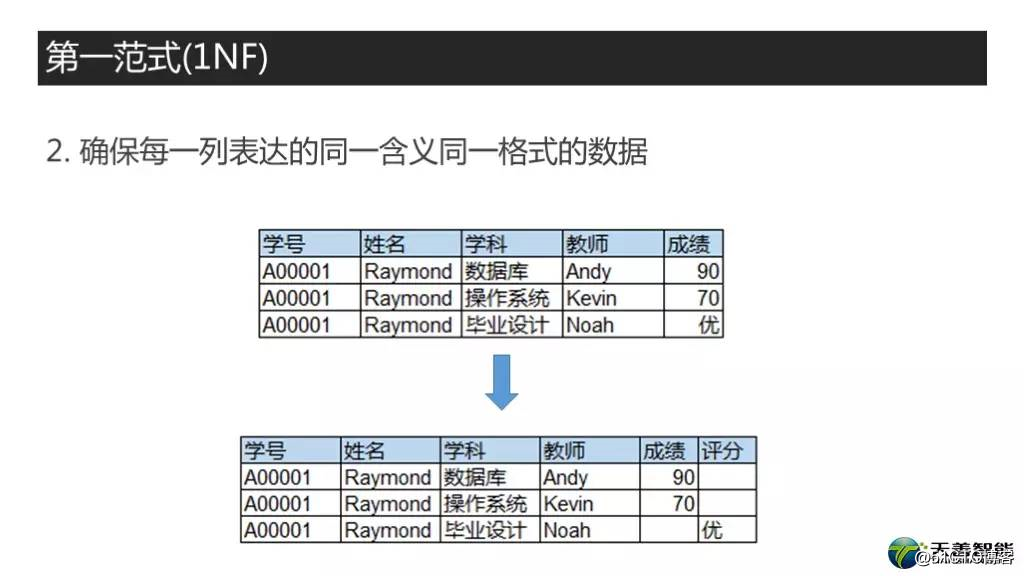
第二件事呢,就是你得保证每个列的含义是一致的并且数据格式还得一致。同一列必须相同的含义, 这个就很容易理解了, 我就不举例子了.同一列还得是相同的数据类型, 比如我这个例子,最后一列,前两行是考试的成绩, 都是数字类型的, 最后一行是优, 是字符类型的,这个显然是不规则的,需要根据实际的情况进行调整。我这个例子很简单了,就是又创建了一列,评分, 然后把这种字符型的数据放到这个列中。因此这里大家需要了解到,表的同一列要表达相同的含义,并且数据类型也得一致。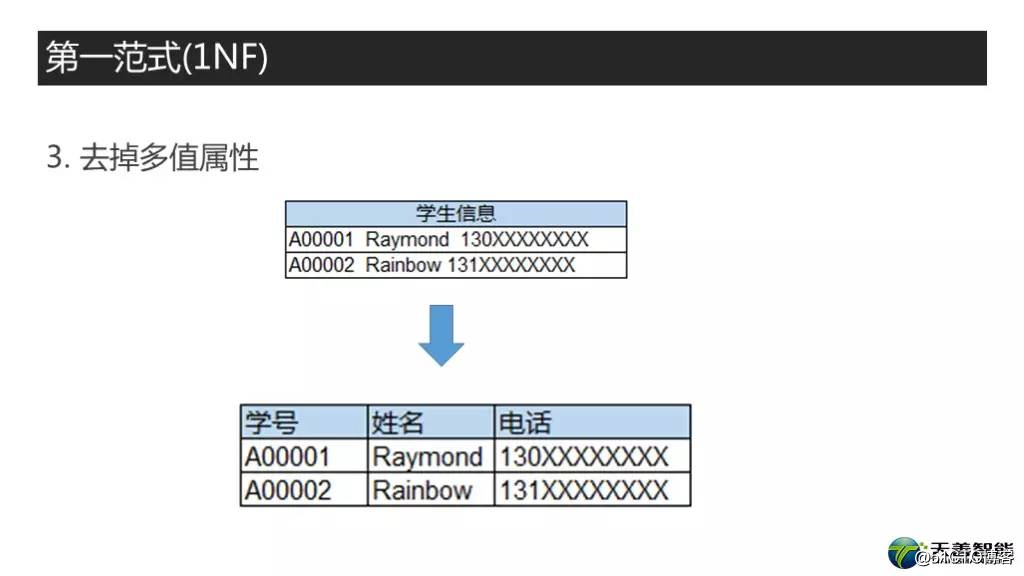
其实前面两件事都是最基础的准备工作了,大部分建模书里面默认建模一开始就具备规则的二维平面文件,所以前面这两件事提及的很少。
做完了前两件事,我们来看第三件事。第三件事是消除多值的列。还是一样,给几个例子:
先看第一个例子,一列,学号,姓名,地址,弄一列去了。这个显然了,得拆开,要不然你怎么检索数据?很简单,拆成三列表达不同的含义,学号,姓名,地址。
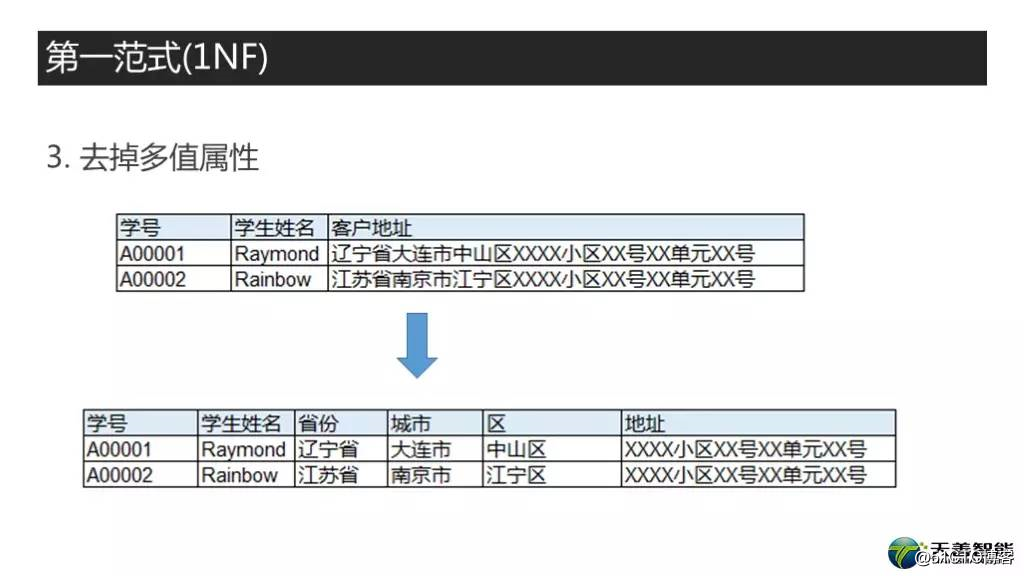
第二个例子,三列,学号,姓名,地址。这个乍一看没啥问题,但是其实我们还是能进一步优化它的,因为这地址名太长,是包括省份,城市,区这种标准化的地域信息的,如果都混在一起,检索起来很困难,而且容易出数据质量问题。比如辽宁省大连市,我要写成辽宁大连,从含义上来讲其实也没错是吧,但如果你按“辽宁省”来做检索,就搜不到了。因此,这种标准化的内容还是应该拆分开,变成下面的模式,增加了省份,城市,区这些信息,后面加上地址。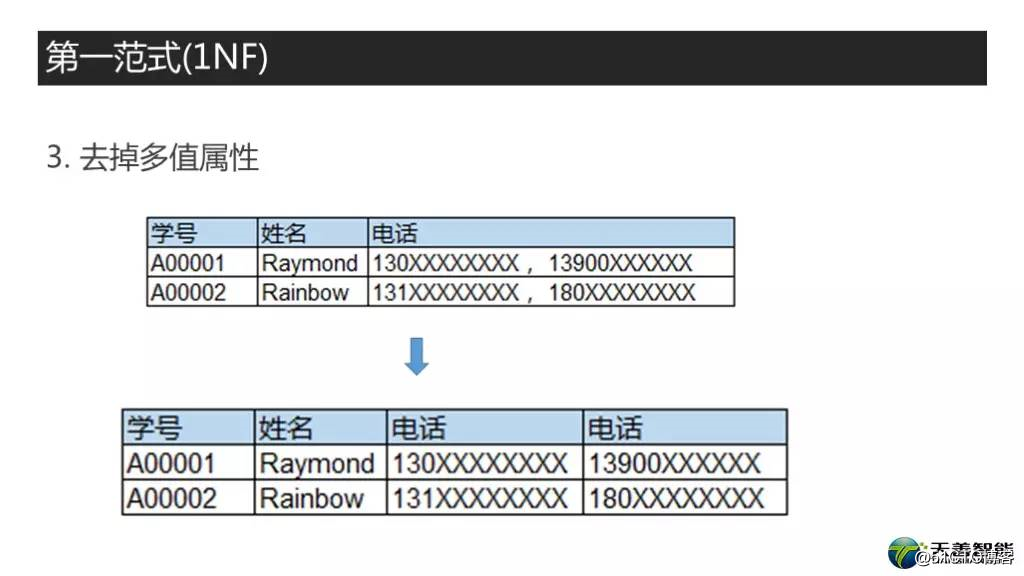
再看第三个例子,三列,学号,姓名,电话。这里的电话,它弄了好几个值,然后用逗号分割开了,也就是存在我们说的,要解决的一列多值的问题。首先第一步,拆解,变成下面这个结构的,变成多个电话了,那么就有人问了,你这俩电话作为列名,不是重了吗?这就引出我们要解决的下一个问题,去掉重复组。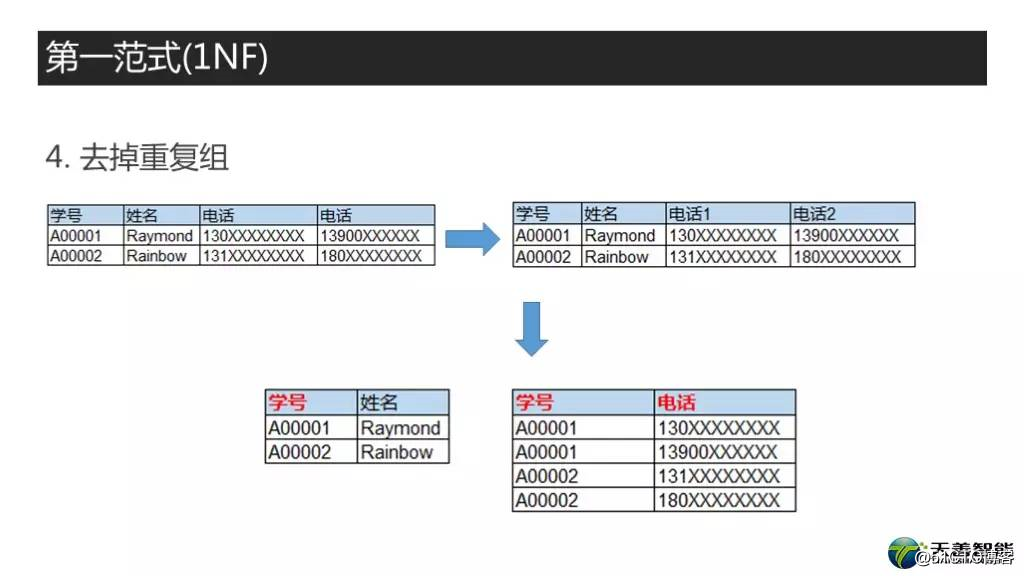
第四件事,去掉重复组,这个是所有数据库设计书籍里面,第一范式设计的重点。这个什么意思呢,就是不能出现相同含义的两列或者多列。
继续看前面的例子,一共有四列,学号,姓名,客户电话,电话,问题来了,俩电话。这个就相当于数据库表里建两个一样的列,这个显然是不行哈。然后改一下,把两个列名为电话的,改成电话1,电话2。这个呢,原则上是可以建到数据库里的,但电话1,电话2,这两列从含义上其实是没有什么分别的,所以有的时候名字改成主要联系电话,和备用联系电话,这种的更好一些。那么还有一个问题万一学生有三个电话号码,而我又都想记录下来,怎么办呢?因此这个设计我们认为是不好的设计,也要把它改掉。那么做怎样的变化呢?这个很简单了,就是把学号和姓名放一张表,这里学号是主键。然后把学号,电话移出去创建另外一张表,学号和电话作为联合主键。这个就是第一范式中消除重复组的办法。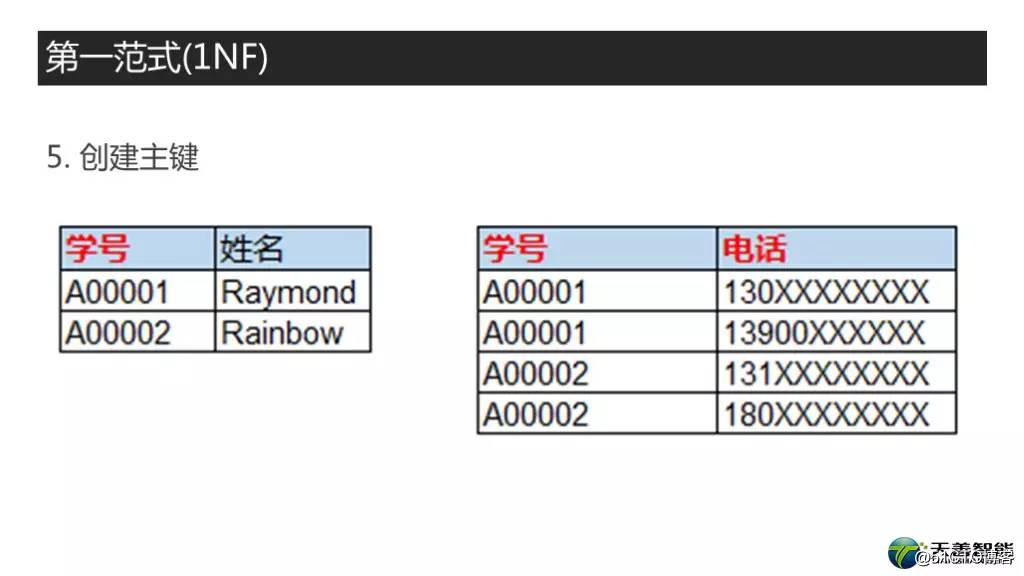
第五件事,创建主键。也就是说,要给每个实体找一个能够唯一标识它任意一行的一列,或者几列的组合。这个我们前面讲主键的时候讲过相关的概念,我这里就不多说了,这例子也很简单,两张表,我标红的列就是主键。
那么这五件事都做完了,就完成了第一范式。

第二范式很简单, 首先第二范式是基于第一范式的, 也就是要满足第二范式必须先满足第一范式. 然后, 第二范式的要求是, 每一个非主键属性必须依赖于整个主键, 而不是主键的一部分.
我们来看一个例子,我这有一张表,一共4列,学号,课程,学生姓名,以及成绩。其中学号和课程作为联合主键。显然学生姓名以及成绩是可以由学号和课程来确定的,但我们发现一个问题,成绩是依赖于整个键,也就是学号+课程。而学生姓名就不是依赖于学号+课程,而只是依赖于这个键的一部分,只要知道学号就可以知道学生姓名了。因此这个和第二范式相悖,因此要做规范化,这里要做的操作是把学生姓名拿出来,单独建一张表,由学号和学生姓名构成。
为什么这么做呢?还是为了减少冗余以及插入删除异常。大家看我这个例子,第一范式下,画绿圈圈的地方,Raymond这个名词是不是存了两份啊,这个就是数据冗余了,而下面的第二范式Raymond就保留一份。我这里只列了三条数据,真实数据库系统中成千上万的数据里面就会多出很多这种冗余,会多占空间更重要的是会带来数据不一致的风险。
此外就是,如果都存上面一张表里,为了删除Raymond的成绩,是不是就把Raymond这个人的学号以及姓名的信息也删了?
这里提醒一下大家,需要考虑第二范式变换的,只存在于联合主键的情况下,如果只有一个主键的情况下不需要考虑第二范式的变化,也就是说它默认就是复合第二范式的,但需要考虑第三范式的变化。
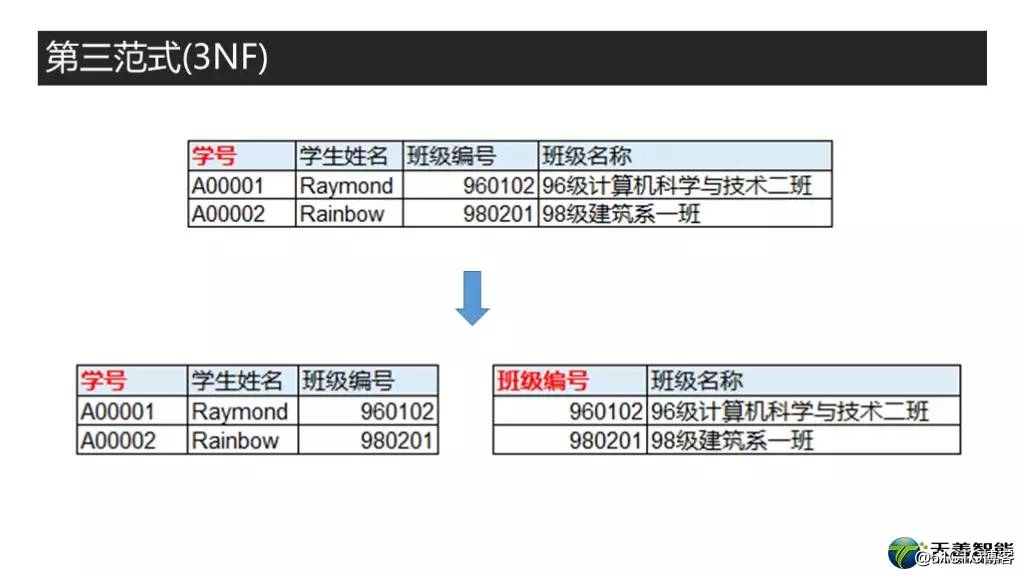
第三范式的要求是什么呢?就是在一张表里,非主属性只能依赖于主键,不能依赖于其他非主属性。和第二范式一样了,首先它也是基于前一个范式的,满足第三范式的前提条件是,必须满足第一和第二范式,然后就是如果存在某非主属性依赖于其他非主属性,就要把这些属性挪出去建表。
这里我给出一个例子,四列,学号,学生姓名,班级编号,班级名称。其中学号是主键。首先显然这个是满足第一范式的,因为是单主键所以不存在考虑第二范式的情况。然后我们可以看到,虽然根据学生的学号是可以确定班级名称的,但班级名称实际上还可以由班级编号来决定,因此这里的班级名称是可以由班级编号这个非主属性决定的,不符合第三范式。要做的处理也很简单,就是把班级编号,班级名称挪出去单独建表。并且把班级编号作为主键。第三范式的最终要求就是,非主属性里面除了其他表的主键以外,存在于其他表的非主键属性统统不能放。
今天的内容就先讲到这,而关系型数据库的规范化的课呢,其实到这就可以停了,因为后面的内容实在很少用,不用去理解也OK。大家有兴趣就听听,没兴趣就不听也无妨。
世界上总有一帮学究,真是有钻研到底的精神,又或许为了彰显他们的与众不同,和研究茴香豆的茴字有四种写法差不多,考虑了一堆其他的场景来创建更规范化的模型。这其中有BCNF,4NF和5NF,据说还有6NF,不过6NF这个我真不知道。下节课我就花点时间讲讲BCNF,4NF和5NF。不过再次提醒,这段真可以不用学。好,我们下节课再见。
↓↓↓ 点击"阅读原文" 【查看作者更多文章】
天善智能 www.hellobi.com 是一个专注于商业智能BI、数据分析、数据挖掘和大数据技术的垂直社区平台。
问答社区和在线学院是国内最大的商业智能BI 和大数据领域的技术社区和在线学习平台,技术版块与在线课程已经覆盖 商业智能、数据分析、数据挖掘、大数据、数据仓库、Microsoft BI、Oracle BIEE、IBM Cognos、SAP BO、Kettle、Informatica、DataStage、Halo BI、QlikView、Tableau、Hadoop 等国外主流产品和技术。
线上活动:Friday BI Fly 每周五晚 20:30,技术和行业交流,20余个微信直播群互动交流。
线下活动:Saturday BI Fly 在全国各大城市巡回举办200人-500人规模的大数据沙龙交流活动,每月1-2次。
天善智能积极地推动国产商业智能 BI 和大数据产品与技术在国内的普及与发展。
以上是关于视频教程|高质量数据库建模之数据模型规范化:一二三范式知多少!的主要内容,如果未能解决你的问题,请参考以下文章