MapReduce
Posted hapyygril
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MapReduce相关的知识,希望对你有一定的参考价值。
2. MAPREDUCE框架结构及核心运行机制
2.1 框架架构
一个完整的mapreduce程序在分布式运行时有三类实例进程:
1、MRAppMaster(Mapreduce application master):负责整个程序的过程调度及状态协调
2、MapTask:负责map阶段的整个数据处理流程
3、ReduceTask:负责reduce阶段的整个数据处理流程
2.2 MapReduce程序运行流程
(1) 一个mr程序启动的时候,最先启动的是MRAppMaster,MRAppMaster启动后根据本次job的描述信息,计算出需要的map task实例数量,然后向集群申请机器启动相应数量的map task进程;
(2) map task进程启动之后,根据给定的数据切片范围进行数据处理,主体流程为:
a) 利用客户指定的inputformat来获取RecordReader读取数据,形成输入KV对;
b) 将输入KV对传递给客户定义的map()方法,做逻辑运算,并将map()方法输出的KV对收集到缓存;
c) 将缓存中的KV对按照K分区排序后不断溢写到磁盘文件;
(3) MRAppMaster监控到所有map task进程任务完成之后,会根据客户指定的参数启动相应数量的reduce task进程,并告知reduce task进程要处理的数据范围(数据分区);
(4) Reduce task进程启动之后,根据MRAppMaster告知的待处理数据所在位置,从若干台map task运行所在机器上获取到若干个map task输出结果文件,并在本地进行重新归并排序,然后按照相同key的KV为一个组,调用客户定义的reduce()方法进行逻辑运算,并收集运算输出的结果KV,然后调用客户指定的outputformat将结果数据输出到外部存储。
2.2.1 MapReduce的示例wordcount运行过程解析
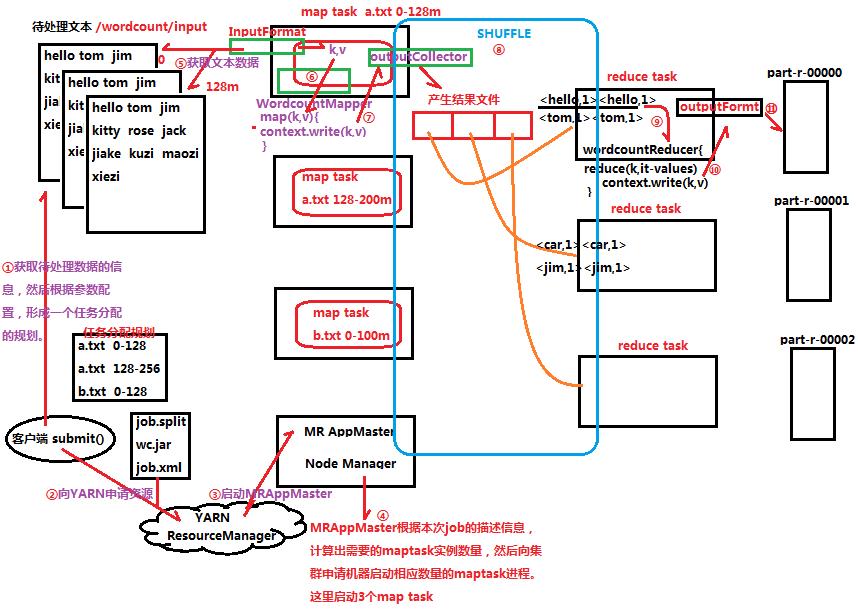
说明:
① client客户端获取待处理数据的信息(如多少个待处理的文件、待处理文件的大小),然后根据参数配置,形成一个任务分配的规划;
② client客户端向Yarn提交job.split、wc.jar和job.xml等相关文件,并申请资源;
③ Yarn首先启动Mr AppMaster;
④ MRAppMaster根据Yarn提供的本次job的描述信息,计算出需要的map task示例数量,然后向集群申请机器,启动相应的map task进程,这里启动3个map task;
⑤ map task根据任务分配规划分配的“a.txt 0-128”数据切片范围,通过InputFormat从中读取相应的数据,形成输入(K,V)键值对;
⑥ 再通过wordcountMapper的map()方法做逻辑运算处理输入(K,V)键值对;
⑦ 缓存map方法输出的(K,V)键值对到outputCollector;
⑧ map task输出的(K,V)键值对经过shuffle流程分区排序等操作,形成新的(K,V集合)键值对;
⑨ reduce task对(K,V集合)键值对进行逻辑处理;
⑩ reduce task输出(K,V)键值对到outputFormat;
? outputFormat把传过来的(K,V)键值对输出到part-0000*等文本文件中;
3. 客户端向Yarn提交mr程序Job的流程
该流程即为“2.2.1 MapReduce的示例wordcount运行过程解析”中的第一、二步骤。
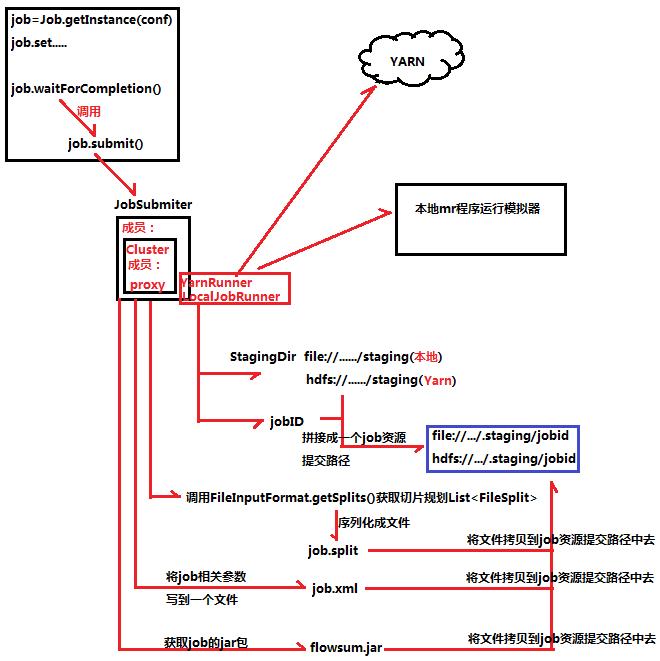
job.waitForCompletion()方法会调用job.submit方法,里面有JobSubmiter类,JobSubmiter类里面有Cluster类成员,Cluster类有个proxy代理成员,负责代理YarnRunner和代理LocalJobRunner。YarnRunner负责向Yarn提交job资源路径,而LocalJobRunner则是向本地提交job资源路径。YarnRunner和LocalJobRunner运行流程是一样,都是会产生StagingDir和JobID两个对象。JobSubmiter还会调用FileInputFormat.getSplits()方法获取切片规划List<FileSplit>并序列化生成job.split文件,根据客户端设置的job相关参数创建job.xml,最后还得获取job的jar包。StagingDir、JobID、job.spilt、job.xml和jar包共同拼接成一个job资源提交路径。
4. Map Task并行度决定机制
map task的平行度决定map阶段的任务处理并发度,进而影响到整个Job的处理速度。一个Job的map阶段并行度由客户端在提交Job时决定,而客户端对map阶段并行度的规划的基本逻辑为:将待处理数据执行逻辑切片(即按照一个特定切片的大小,将待处理数据划分成逻辑上的多个split),然后每一个split分配一个mapTask并行实例处理。这段逻辑及形成的切片规划描述文件job.split,由FileInputFormat的getSplits()方法完成。决定map阶段并行度的任务切片规划过程即为“2.2.1 MapReduce的示例wordcount运行过程解析”中的第一步骤。切片规划过程如下:
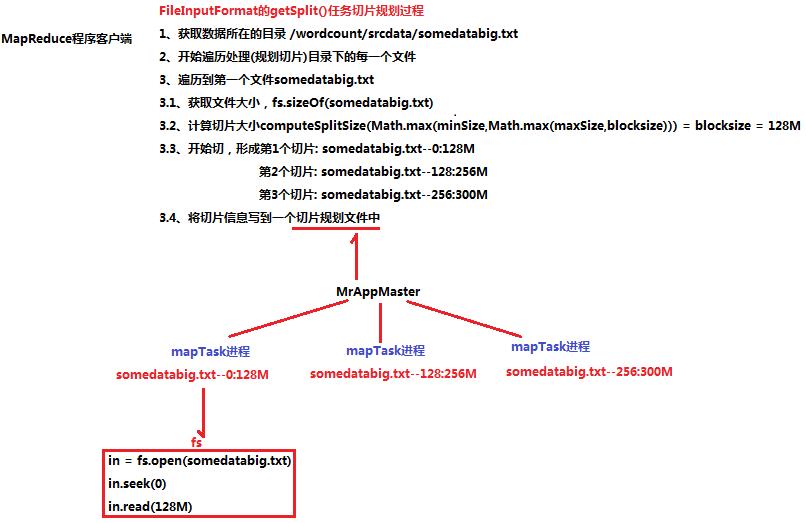
切片定义在FileInputFormat类中的getSplit()方法中。
FileInputFormat中默认的切片机制:
a) 简单地按照文件的内容长度进行切片;
b) 切片大小,默认等于block大小;
c) 切片时不考虑数据集整体,而是逐个针对每一个文件单独切片

FileInputFormat中切片的大小的参数配置
通过分析源码,在FileInputFormat中,计算切片大小的逻辑:Math.max(minSize,Math.min(maxSize,blockSize));切片主要由这几个值来运算决定:
| minSize |
默认值:1 |
配置参数:mapreduce.input.fileinputformat.split.minSize |
| maxSize | 默认值:Long.MAXValue | 配置参数:mapreduce.input.fileinputformat.split.maxSize |
| blockSize | 默认情况下切片的大小 |
默认情况下,切片大小=blockSize
maxSize(切片最大值):参数如果调到比blockSize小,则会让切片变小,而且就等于配置的这个参数的值;
minSize(切片最小值):参数如果调的比blockSize大,则可以让切片变得比blockSize还大。
map并行度的经验之谈:
选择并发数的影响因素:①运算节点的硬件配置;②运算任务的类型:CPU密集型或IO密集型;③运算任务的数据量;
如果硬件配置为2*12core + 64G,恰当的map并行度是大约每个节点20~100个map,最好每个map的执行时间至少一分钟。
如果job的每个map或者reduce task的运行时间都只有30-40秒钟,那么就减少该job的map或者reduce数;每一个task(map|task)的setup和加入到调度器中进行调度,这个中间的过程可能都要花费几秒钟,所以如果每个task都非常快就跑完了,就会在task的开始和结束的时候浪费太多的时间。配置task的JVM重用可以改善该问题:mapred.job.jvm.num.tasks,默认是1,表示一个JVM上最多可以顺序执行的task数目(属于同一个Job)是1,也就是说一个task启动一个JVM。
如果input的文件非常的大,比如1TB,可以考虑将hdfs上的每个block size设大,比如设成256MB或者512MB。
5. Reduce Task并行度决定机制
Reduce task的并行度同样影响整个Job的执行并发度和执行效率,但与map task的并发数由切片数决定不同,Reduce task数量的决定是可以直接手动设置的。
如果数据分布不均匀,就有可能在reduce阶段产生数据倾斜
注意:reduce task数量并不是任意设置,还要考虑业务逻辑需求,有些情况下,需要计算全局汇总结果,就只能有1个reduce task。
尽量不要运行太多的reduce task。对大多数job来说,最好reduce的个数和集群中的reduce持平,或者比集群的reduce slots小。这个对于小集群而言,尤其重要。
6. MapReduce的shuffle机制
6.1 概述
MapReduce中,map阶段处理的数据如何传递给reduce阶段,是mapreduce框架中最关键的一个流程,这个流程就叫shuffle;
shuffle:洗牌、发牌——(核心机制:数据分区,排序,缓存);
具体来说:就是将maptask输出的处理结果数据,分发给reduce task,并在分发的过程中,对数据按key进行了分区和排序;
5.2 shuffle流程
shuffle是MR处理流程中的一个过程,它的每一个处理步骤是分散在各个map task和reduce task节点上完成的,整体来看,分为3个操作:
(1) 分区partition
(2) Sort根据key排序
(3) Combiner进行局部value的合并
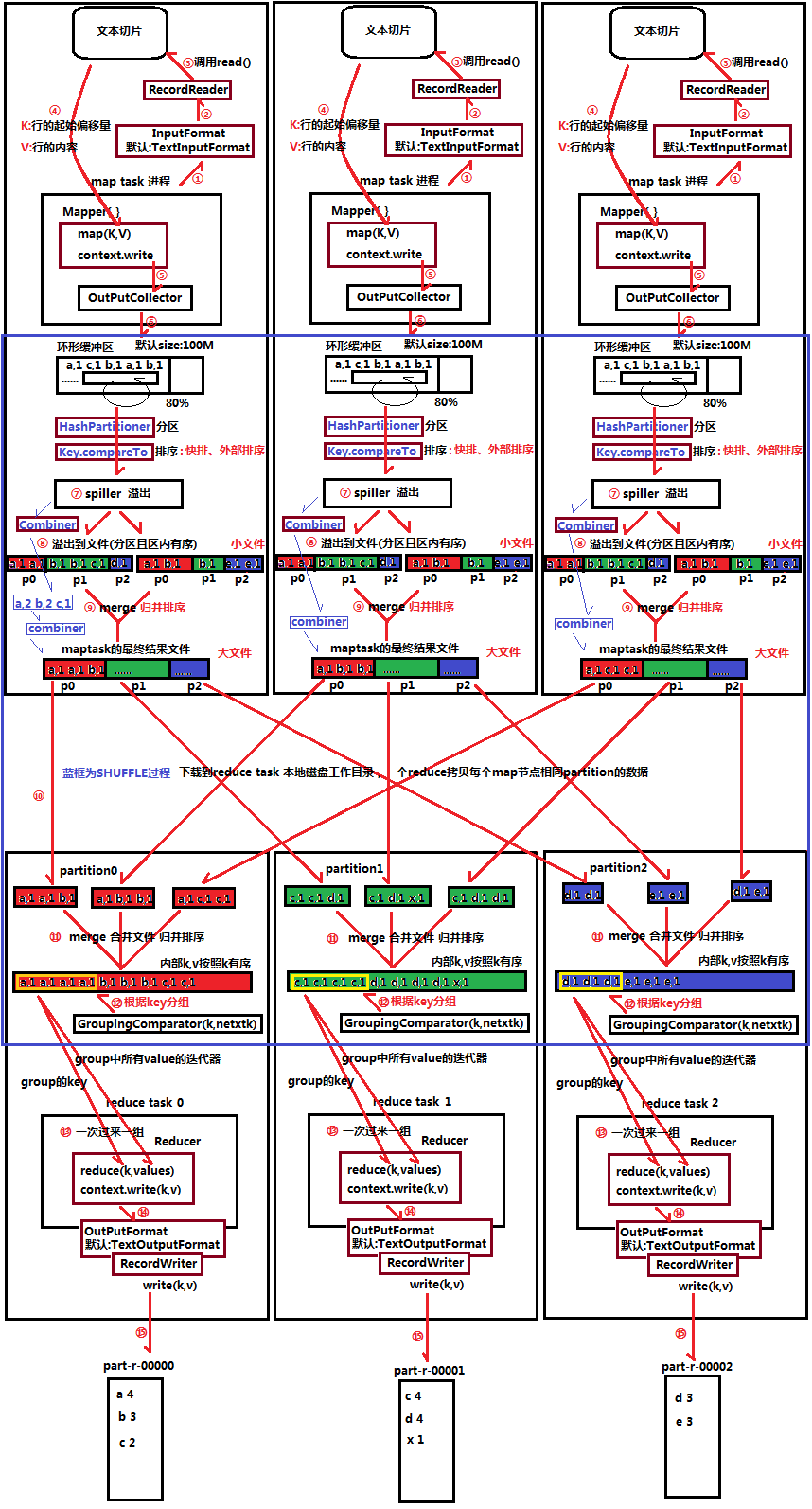
1、①②③④map task读文件,是通过TextInputFormat(--> RecordReader --> read()) 一次读一行,返回(key,value);
2、⑤上一步获取的(key,value)键值对经过Mapper的map方法逻辑处理形成新的(k,v)键值对,通过context.write输出到OutputCollector收集器;
3、⑥OutputCollector把收集到的(k,v)键值对写入到环形缓冲区中,环形缓冲区默认大小为100M,只写80%(环形缓冲区其实是一个数组,前面写着,后面有个组件清理这,写到文件中,防止溢出)。当环形缓冲区里面的数据达到其大小的80%时,就会触发spill溢出;
4、⑦spill溢出前需要对数据进行分区和排序,即会对环形缓冲区里面的每个(k,v)键值对hash一个partition值,相同partition值为同一分区,然会把环形缓冲区中的数据根据partition值和key值两个关键字升序排序;同一partition内的按照key排序;
5、⑧将环形缓冲区中排序后的内存数据不断spill溢出到本地磁盘文件,如果map阶段处理的数据量较大,可能会溢出多个文件;
6、⑨多个溢出文件会被merge合并成大的溢出文件,合并采用归并排序,所以合并的maptask最终结果文件还是分区且区内有序的;
7、⑩reduce task根据自己的分区号,去各个map task节点上copy拷贝相同partition的数据到reduce task本地磁盘工作目录;
9、?reduce task会把同一分区的来自不同map task的结果文件,再进行merge合并成一个大文件(归并排序),大文件内容按照k有序;
10、??合并成大文件后,shuffle的过程也就结束了,后面进入reduce task的逻辑运算过程,首先调用GroupingComparator对大文件里面的数据进行分组,从文件中每次取出一组(k,values)键值对,调用用户自定义的reduce()方法进行逻辑处理;
11、??最后通过OutputFormat方法将结果数据写到part-r-000**结果文件中;
注:shuffle中的环形缓冲区大小会影响到MapReduce程序的执行效率,原则上说,缓冲区越大,磁盘IO的次数越少,执行速度就越快。环形缓冲区的大小可以通过在mapred-site.xml中设置mapreduce.task.io.sort.mb的值来改变,默认100M。溢出的时候调用combiner组件,逻辑和reduce的一样,合并,相同的key,value相加,这样传效率高,不用一下子传好多相同的key,在数据量非常大的时候,这样的优化可以节省很多网络带宽和本地磁盘IO流的读写,具体的代码实现:定义一个combiner类,集成Reducer,输入类型和map的输出类型相同。
关于大量小文件的优化策略:
(1) 默认情况下,TextInputFormat对任务的切片机制是按文件规划切片,不管文件多小,都会是一个单独的切片,都会交给一个maptask,这样,如果有大量小文件,就会产生大量的maptask,处理效率极其低下;
(2) 优化策略:最好的方法是,在数据处理系统的最前端(预处理/采集),就将小文件先合并成大文件,再上传到HDFS做后续分析。补救措施是,如果已经是大量小文件在hdfs中,可以使用另一种InputFormat来做切片(CombineFileInputFormat),它的切片逻辑与FileInputFormat不同,它可以将多个小文件从逻辑上规划到一个切片中,这样,多个小文件就可以交给一个maptask来处理。
7. MapReduce中的序列化
7.1 概述
Java的序列化是一个重量级序列化框架(Serializable),一个对象被序列化后,会附带很多额外的信息(各种校验信息、header、继承体系等等),不便于在网络中高效传输;所以,hadoop自己开发了一套序列化机制(Writable),精简、高效。
7.2 自定义对象实现MR中的序列化接口
如果需要将自定义的bean放在key中传输,则还需要实现comparable接口,因为mapreduce的shuffle流程一定会对key进行排序,此时,自定义的bean实现的接口应该是:public class FlowBean implements WritableComparable<FlowBean>
参考资料:https://www.bbsmax.com/A/KE5Qjg6qdL/
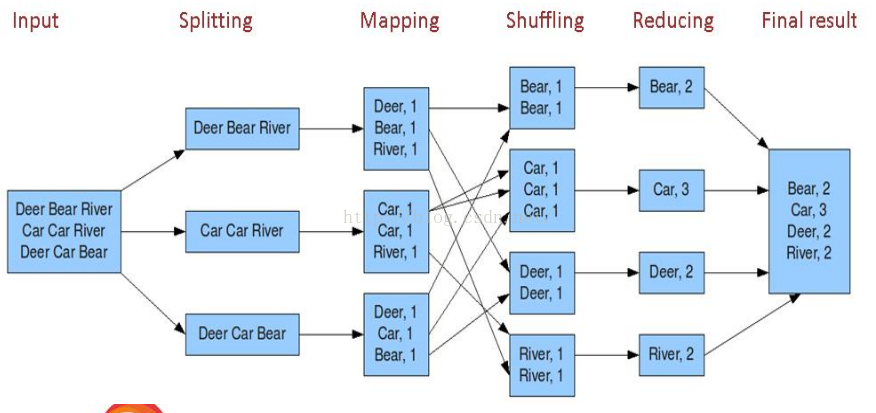
map阶段
(1)输入分片(input split)
在进行map计算之前,mapreduce会根据输入文件计算输入分片(input split),每个输入分片(input split)针对一个map任务
输入分片(input split)存储的并非数据本身,而是一个分片长度和一个记录数据的位置的数组,输入分片(input split)往往和hdfs的block(块)关系很密切
假如我们设定hdfs的块的大小是64mb,如果我们输入有三个文件,大小分别是3mb、65mb和127mb,
那么mapreduce会把3mb文件分为一个输入分片(input split),
65mb则是两个输入分片(input split)
127mb也是两个输入分片(input split)
那么就会有5个map任务将执行,而且每个map执行的数据大小不均,这个也是mapreduce优化计算的一个关键点。
在map阶段,使用job.setInputFormatClass定义的InputFormat将输入的数据集分割成小数据块splites,同时InputFormat提供一个RecordReder的实现。
使用的是TextInputFormat,RecordReader会将文本的字节偏移量作为key,这一行的文本作为value。这就是自定义Map的输入是<LongWritable, Text>
(2)分区
在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。
其实分区就是对数据进行hash。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combiner操作
这是提高reduce效率的一个关键所在。
(3)排序和Combiner
写入内存(缓冲区)==》排序 ==》 combiner ==》写入磁盘 ==》溢出文件
map在做输出时候会在内存里开启一个环形内存缓冲区,将结果写入内存(缓冲区)
map还会启动一个守护线程,如果缓冲区的内存达到了阀值的80%时候,这个守护线程就会把内容写到磁盘上,另外的20%内存可以继续写,这个过程叫spill;
写入内存和写入磁盘是互不干扰的,如果缓存区被撑满了,那么map就会阻塞写入内存的操作,让写入磁盘操作完成后再继续执行写入内存操作
每次spill操作也就是写入磁盘操作时候就会写一个溢出文件,也就是说在做map输出有几次spill就会产生多少个溢出文件,等map输出全部做完后,map会合并这些输出文件。
(4)将分区中的数据拷贝给相对应的reduce任务。
reduce阶段
(1)Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。
如果reduce端接受的数据量相当小,则直接存储在内存中,如果数据量超过了该缓冲区大小的一定比例,则对数据合并后溢写到磁盘中。
(2)随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。
(3)最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数
以上是关于MapReduce的主要内容,如果未能解决你的问题,请参考以下文章
大数据框架之Hadoop:MapReduceMapReduce框架原理——数据清洗(ETL)