数据库软件架构,到底要设计些什么?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据库软件架构,到底要设计些什么?相关的知识,希望对你有一定的参考价值。
一、基本概念
概念一:单库

概念二:分片
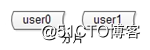
分片解决“数据量太大”这一问题,也就是通常说的“水平切分”。
一旦引入分片,势必面临“数据路由”的新问题,数据到底要访问哪个库。路由规则通常有3种方法:
(1)范围:range
优点:简单,容易扩展。
缺点:各库压力不均(新号段更活跃)。
(2)哈希:hash
优点:简单,数据均衡,负载均匀。
缺点:迁移麻烦(2库扩3库数据要迁移)。
(3)统一路由服务:router-config-server
优点:灵活性强,业务与路由算法解耦。
缺点:每次访问数据库前多一次查询。
大部分互联网公司采用的方案二:哈希路由。
概念三:分组
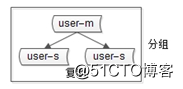
分组解决“可用性,性能提升”这一问题,分组通常通过主从复制的方式实现。
互联网公司数据库实际软件架构是“既分片,又分组”: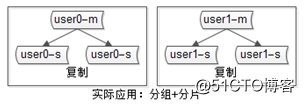
数据库软件架构,究竟设计些什么呢,至少要考虑以下四点:
- 如何保证数据可用性
- 如何提高数据库读性能(大部分应用读多写少,读会先成为瓶颈)
- 如何保证一致性
- 如何提高扩展性
二、如何保证数据的可用性?
解决可用性问题的思路是:冗余。
如何保证站点的可用性?冗余站点。
如何保证服务的可用性?冗余服务。
如何保证数据的可用性?冗余数据。
数据的冗余,会带来一个副作用:一致性问题。
如何保证数据库“读”高可用?
冗余读库。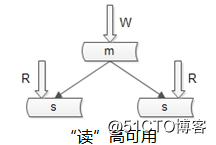
冗余读库带来什么副作用?
读写有延时,数据可能不一致。
上图是很多互联网公司mysql的架构,写仍然是单点,不能保证写高可用。
如何保证数据库“写”高可用?
冗余写库。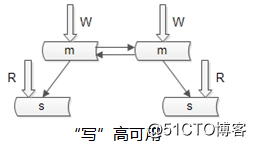
采用双主互备的方式,可以冗余写库。
冗余写库带来什么副作用?
双写同步,数据可能冲突(例如“自增id”同步冲突)。
如何解决同步冲突,有两种常见解决方案:
(1)两个写库使用不同的初始值,相同的步长来增加id:1写库的id为0,2,4,6...;2写库的id为1,3,5,7…;
(2)不使用数据的id,业务层自己生成唯一的id,保证数据不冲突;
阿里云的RDS服务号称写高可用,是如何实现的呢?
他们采用的就是类似于“双主同步”的方式(不再有从库了)。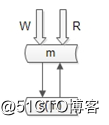
仍是双主,但只有一个主提供读写服务,另一个主是“shadow-master”,只用来保证高可用,平时不提供服务。
master挂了,shadow-master顶上,虚IP漂移,对业务层透明,不需要人工介入。
这种方式的好处:
(1)读写没有延时,无一致性问题;
(2)读写高可用;
不足是:
(1)不能通过加从库的方式扩展读性能;
(2)资源利用率为50%,一台冗余主没有提供服务;
画外音:所以,高可用RDS还挺贵的。
三、如何扩展读性能?
提高读性能的方式大致有三种,第一种是增加索引。
这种方式不展开,要提到的一点是,不同的库可以建立不同的索引。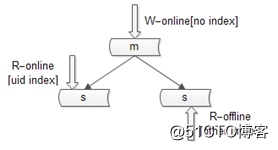
如上图:
(1)写库不建立索引;
(2)线上读库建立线上访问索引,例如uid;
(3)线下读库建立线下访问索引,例如time;
第二种扩充读性能的方式是,增加从库。
这种方法大家用的比较多,存在两个缺点:
(1)从库越多,同步越慢;
(2)同步越慢,数据不一致窗口越大;
第三种增加系统读性能的方式是,增加缓存。
常见的缓存架构如下: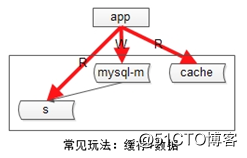
(1)上游是业务应用;
(2)下游是主库,从库(读写分离),缓存;
如果系统架构实施了服务化:
(1)上游是业务应用;
(2)中间是服务;
(3)下游是主库,从库,缓存;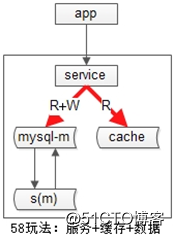
业务层不直接面向db和cache,服务层屏蔽了底层db、cache的复杂性。
不管采用主从的方式扩展读性能,还是缓存的方式扩展读性能,数据都要复制多份(主+从,db+cache),一定会引发一致性问题。
四、如何保证一致性?
主从数据库的一致性,通常有两种解决方案:
(1)中间件
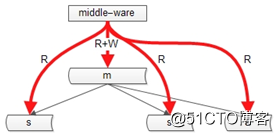
如果某一个key有写操作,在不一致时间窗口内,中间件会将这个key的读操作也路由到主库上。
(2)强制读主
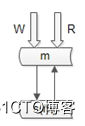
“双主高可用”的架构,主从一致性的问题能够大大缓解。
第二类不一致,是db与缓存间的不一致。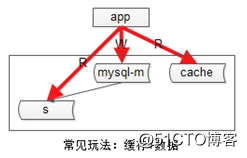
这一类不一致,《缓存架构,一篇足够?》里有非常详细的叙述,本文不再展开。
另外建议,所有允许cache miss的业务场景,缓存中的KEY都设置一个超时时间,这样即使出现不一致,有机会得到自修复。
五、如何保障数据库的扩展性?
秒级成倍数据库扩容:
《亿级数据DB秒级平滑扩容》
如果不是成倍扩容:
《100亿数据平滑数据迁移,不影响服务》
也可能,是要对字段进行扩展:
《1万属性,100亿数据,架构设计?》
这些方案,都有相关文章展开写过,本文不再赘述。
数据库软件架构,到底要设计些什么?
- 可用性
- 读性能
- 一致性
- 扩展性
希望对大家系统性理解数据库软件架构有帮助。
架构师之路-分享可落地技术
相关推荐:
《回表查询?索引覆盖?| 1分钟系列》新出炉
《优化工具,迅猛定位低效SQL | 1分钟系列》
《数据库允许空值(null)是悲剧的开始 | 1分钟系列》
《两类非常隐蔽的全表扫描 | 一分钟系列》
以上是关于数据库软件架构,到底要设计些什么?的主要内容,如果未能解决你的问题,请参考以下文章