走向无后端的系统开发实践:CRUD自动化与强约定的REST接口
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了走向无后端的系统开发实践:CRUD自动化与强约定的REST接口相关的知识,希望对你有一定的参考价值。
走向无后端的系统开发实践:CRUD自动化与强约定的REST接口
导读:最近业界流行一种 serverless 的做法,就是将重的后端改成轻的后端或者干脆去掉后端,本文介绍的是袁新宇在高可用架构群分享的一种通过通用 CRUD 层来生成后端代码以去除传统后端开发的方法。
 袁新宇,浙江大学计算机博士,读博期间主要研究方向是并行编译和大规模互联网架构。2012 年创业,社交 APP 脸脸的技术合伙人,项目曾拿到俞敏洪的 A 轮投资。2015 年 6 月离开脸脸后加入一家医疗保险行业的创业公司‘亿保健康’,负责整体研发团队。
袁新宇,浙江大学计算机博士,读博期间主要研究方向是并行编译和大规模互联网架构。2012 年创业,社交 APP 脸脸的技术合伙人,项目曾拿到俞敏洪的 A 轮投资。2015 年 6 月离开脸脸后加入一家医疗保险行业的创业公司‘亿保健康’,负责整体研发团队。
今天给高可用架构读者分享的是今年做的一个无后端项目的总结。
1. 缘起
我们在 2016 年初上线了一个网上药房:老白网 laobai.com。
半年多的时间,老白网的官网销售额在全国自营的网上药房里已经排名前 10 了。电商的后端需要有一套供应链管理系统,但是由于药品的特殊性,药品采购/仓储/物流等需要符合 GSP 规范,导致我们目前外购并同时使用两套供应链系统,一套通用版满足基本的功能需求,一套主要是药品的 GSP 审核的需要,两个系统之间还需要数据交换。此外,这些外购的系统也无法满足我们自己的一些定制化开发的需求。所以就迫切需要自己开发一个满足 GSP 规范的药品行业供应链系统。
外购的第三方的供应链系统有 1000 多张表,功能上的复杂度主要在数据表多且有关联,对性能/并发上到是没有太多的要求。因为可以参考第三方的数据库结构设计,也可以参考第三方的界面设计,所以数据库/前端都没有太多的不确定性。
当时这个项目的团队情况是有一个靠谱的 DBA,有几个前端开发,但是缺少后端程序员。功能很多,需要开发的人力缺口很大,正是在这种情况下催生了本文提到的无后端技术方案。方案的主要考虑是:
1.数据库设计完成后,前端要求可以直接开始开发,不能等后端接口。
2.后端的开发工作量要尽可能少,多用代码生成技术,因为没有专职的后端程序员。
2. REST 的优点与不完备性
关于前后端之间的接口规范,主要有三种风格: RPC vs REST vs GraphQL。
- RPC 风格的接口规范是最传统的,但是不太合适基于 Web 的系统,所以本方案中不予考虑。
- GraphQL 调研了一下,它能够满足我们的第一个需求,前端可以定义接口,对后端接口依赖少。但是无法满足第二点,采用 GraphQL 的后端开发工作量很大,测试也麻烦,而且 GraphQL 太新,整个团队都没有使用的经验。
- REST 有很多可用的代码生成系统可参考,比如 rails scaffold / Django admin,不需要从零开始。所以综合考虑还是采用 REST 风格。
按照 Fielding 博士的说法,REST 只适用于应用软件的架构,不包括操作系统、网络软件和一些仅仅为得到系统支持而使用网络的架构风格 ( 例如,进程控制风格)。应用软件代表的是一个系统的“理解业务” (business-aware) 的那部分功能。
按照 REST 架构设计的 Web API 一般被成为 RESTful API。
REST 在数据库类应用中使用广泛。针对数据库中的一张表,RESTful API 通过约定来定义好 CRUD 的全部接口 API,不需要前后端之间沟通接口的设计,而且各种语言都有针对单表的 CRUD 后端自动代码生成,能够减少后端的开发工作量。约定大于配置是一个很好的软件工程实践,能够大大减少软件开发的复杂性。下面就是一个 RESTful 的 API 约定:
操作
HTTP Method
URI
获取列表数据
GET
/表名(.:format)
添加新数据
POST
/表名(.:format)
修改已有数据
PUT
/表名/:id(.:format)
查看已有数据
GET
/表名/:id(.:format)
删除已有数据
DELETE
/表名/:id(.:format)很多知名的软件和框架都采用了类似这套的约定,比如 Rails 开发框架/ Elasticsearch 搜索等。
当然针对实际的软件开发需求, REST 的规范还是太简单了。标准的 RESTful 接口只有四个动作, CRUD。一个最常见的扩展(或者说是误用),就是使用更多的动作。因为常见的后端开发框架是 controller + action 的模式,一个 controller 对应一个资源,里面配置多个 action 对应前端用户的多个动作。典型的,比如一个帖子,点赞 / 取消赞是两个动作。然后随着业务的发展,还有锁帖 / 解锁操作,回复帖子 / 查看所有 0 回复帖子等等需要。于是就有了下面的这种 URL 设计:
POST /topics/follow
POST /topics/unfollow
POST /topics/lock
POST /topics/unlock
POST /topics/reply
GET /topics/no_reply
慢慢的,接口越来越复杂,离原来的 RESTful 风格越来越远。当然,有人觉得这种风格也不错。而 DHH 的观点是这种风格 URL 需要改造为 RESTful 的风格,比如对于点赞的场景,可以认为有一个资源是 topics / follows,然后这个资源有添加和删除两个操作。
关于 DHH 对这种风格的讨论,可参考这个链接 [1],中文翻译版 [2]。
http://jeromedalbert.com/how-dhh-organizes-his-rails-controllers/
http://mp.weixin.qq.com/s?__biz=MzAxNDEyMDI5NA==&mid=453464461&idx=1&sn=57341bf83cef600efb930a134f9ca636
这还只是对单表资源的 CRUD 操作,我们碰到的 RESTful 规范主要是缺失下面的一些部分:
- 查询/分页/排序的支持。RESTful 接口只有一个列表的接口,对查询相关的功能没有约定。
- 批量操作的支持。RESTful 接口默认只支持单个资源的操作,而实际的业务场景中经常需要有批量操作的需求,比如商品的批量上架、数据的批量删除等。
- 有关联的数据表的支持。RESTful 只支持单个资源的 CRUD,而实际业务中经常有主子表的级联保存,关联表的查询等。
所以本方案主要考虑两点:
扩展 REST,针对上述三种场景约定好接口规范。目的是让前端程序员只需要知道接口约定,就可以针对所有的数据库表进行接口开发。无需提供详细的接口说明文档。
如何通过自动代码生成的方式实现这些规范,以减少后端开发的工作量。
3. RESTful 扩展:单表批量操作(添加/更新/删除)
批量新增接口
REST 规范没有约定如何实现批量操作,也没有说明提交参数和返回值的格式。实践中,Elasticsearch 提供了批量操作的入口/_bulk,统一处理所有的批量操作,可以在一次请求里完成索引/更新/删除等多个操作。本方案对批量操作的要求更严格,只支持单表数据的一种操作。对于批量新增接口,我们重用 RESTful 的新增接口,只是提交的数据格式不一样。
单个新增的话,提交的是一个单个的 hash 对象
{
"表名单数": {id:id, field:value,...}
}
批量新增的话,提交的里层数据是一个数组
{
"表名复数": [{id:id1, field:value,...},{id:id2}...]
}
而且约定在所有的输入输出中,如果是集合对象,名字采用复数形式;如果是单个对象,名字采用单数形式。当然,还有一个约定是所有的主键的字段名都是“id”。请求中的 field 直接对应数据库的列名。如果 id 不传,则由数据库提供自动生成的主键。
批量修改接口
对于如何定义批量修改接口,有点左右为难。首先,无法按照批量新增的模式重用修改接口,因为 RESTful 的单条数据修改接口“PUT /表名/:id”和单个id绑定了。如果严格参考 DHH 的做法,批量修改也需要抽象成一个资源,类似于点赞,而不应该增加一个动作。
但是我对这个做法不习惯,批量修改我认为还是和 CRUD 一个性质的。所以还是决定增加了一个动作 batch_update,也是整个约定里唯一增加的动作。批量修改接口的url地址是“/表名/batch_update.json”,提交的 JSON 数据格式和批量新增接口一致。
批量删除接口
批量删除接口也没有按照 DHH 的说法抽象成资源,而是重用了 RESTful 的删除接口,只是id的格式不一样。批量删除接口,一次传入多个 id,id 之间以英文逗号“,”分割。
所以针对批量操作,本方案增加了两个约定如下:
操作
HTTP Method
URI
批量修改数据
POST
/表名/batch_update(.:format)
批量删除数据
DELETE
/表名/:id,:id4. RESTful 扩展:单表查询
单表的查询,URI 直接重用 REST 规范,但是要约定好查询的参数的传递规范。我们定义了下面这些查询的请求格式
s[field]=value
s[like[field]]=value
s[date[field]]=value
s[range[field]]=value
s[in[field]]=value
s[cmp[field,field]]=
分别代表精确查询/like字符串模糊查询/date日期范围查询/range范围查询/in枚举查询。这些查询基本满足了 OLTP 业务的常见需求,报表统计类需求有专门的报表系统。
如果有多个查询条件,条件之间是逻辑与的关系。
s[field1]=value1&s[like[field2]]=value2
查询的 field 直接对应到数据库的字段。如果 field 有逗号“,”,则表示同时查询多个字段,其中一个满足条件即可,也就是 OR 查询。
"/warehouses.json?s[like[company,address]]=测试"
这个查询的意思是查找所有 company 包含‘测试’或者 address 包含‘测试’的所有仓库。
针对 date/range/in 查询,支持value中包含逗号“,”。以 range 查询为例,“1,5”代表范围是1到5,",5"代表小于等于5,"3,“代表大于等于3。
"/warehouses.json?s[range[id]]=1,5"
"/warehouses.json?s[range[id]]=,5"
"/warehouses.json?s[range[id]]=3,"
分页/排序/Count计数
"/warehouses.json?page=1"
"/warehouses.json?page=1&per=100"
"/warehouses.json?page=1&order=id+desc"
"/warehouses.json?page=1&per=100&count=1"
分页参数page/per,排序参数order,计数参数count之间都是可以自由组合的。
5. RESTful 扩展:关联表支持
5.1 外键查询的支持
上一节提到的单表查询规范,其中的 field 字段,增加对特殊符号”.“的支持,用于外键查询。这样 Field 可以包含三种类型:
单个key;
多字段的key,格式:"key1,key2,..."
外键的key,格式:“key1.key2”。
其中,多字段的 key 的格式表示多个字段的or查询,上文已经提及。外键查询要求被查询的表有对应的外键字段。比如仓库属于公司,那么 warehouses 表有一个外键 company_id,company 有 id、name 字段,那么可以有下面的查询:
"warehouses.json?s[company.name]=测试公司"
"warehouses.json?s[range[company.id]]=1,5"
这两个查询的含义是显而易见的。
5.2 关联表查看
本系统支持在查看一条数据时,自动带出关联的父表的数据。同时也支持带出给定的几个关联子表数据:传递参数many=表1[,表2],比如:
GET warehouses/1.json?many=stores
查看编号为1的仓库的基本信息,同时给出这个仓库下面的所有库位的信息。这个查询要求stores表有一个外键指向warehouses表。
5.3 子表的级联新增和删除
主子表的级联保存
有很多业务场景需要支持在一个事务里保存主表和关联的多个子表的数据。级联保存的接口和批量保存的接口类似,只是提交的参数有区别。主子表新增的话,提交的数据格式如下:
{
"主表单数": {id:id, field:value,...} ,
"子表复数": [{id:id1, field:value,...},{id:id2,}...]
}
主子表的级联删除
关联表之间如果存在数据库外键约束,单独删除主表的数据是不能成功的。此时就需要把依赖于该主表的所有子表数据也删除。在删除的接口增加一个 many 参数,用于处理这种情况,传递格式“many=表1[,表2]”,比如:
warehouses/1234.json?many=stores
关联表删除和批量删除是一个接口,可以一次性删除。比如:
/1,2,3,4.json?many=table1s,table2s
代表批量删除“1,2,3,4”四个数据,其中每个数据都级联删除两个子表“table1s,table2s”的所有关联数据。
6. 后端的自动代码生成
上面讲的所有关于强约定的 RESTful 接口,目的是给定数据库的情况下,前端就可以独立完成供应链系统的开发。而后端则需要在给定了数据库的情况下,自动生成实现所有上述接口约定的代码。完成这个艰巨任务的前提是数据库结构符合一定的规范。
6.1 数据库约定
数据库命名首先是采用了标准的 rails 数据库约定:
- 表名用英文复数形式,多个单词之间用下划线“ _”分割。表名/字段名除了字母/数字/下划线,不能包含其它特殊字符。
- 主键的名字都是” ID“
- 外键的名字都是“表名单数 _id”,非外键字段不能以” _id" 结尾
- 每张表可以添加默认的创建时间/修改时间字段,字段名称必须是 "created_at" “ updated_at",类型是 datetime
然后是本项目特定的数据库约束:
如果一张表里有多个关联到另外一张表的外键,命名规则是“前缀 _ 表名单数 _id”。比如一张库存调拨单,会有来源仓库和目的仓库,都需要外键关联到仓库表,此时就需要通过前缀 "from_warehouse_id" 和 "to_warehouse_id" 来区分;
如果要使用多个数据库,不同的数据库之间不要有同名的表 ;
6.2 建立数据表关联
本方案并不是通过获取数据库的外键约束来获取数据表之间的关联,而是通过命名约定来获取关联信息。这样的好处是方案更灵活,且支持跨数据库的外键关联。
通常情况下,一个外键有三种可能:一对一,一对多,多对多。为了简化实现,本方案只采用一对多。“一对一”是“一对多”的特例,“多对多”则可以用两个“一对多”来表示。
关联关系是双向的,对于两个表 table1s 和table2s,如果 table1 有一个字段table2_id,那么 table1 是多方,table2 是一方,用 rails 来描述就是:
Table1 belongs_to table2
Table2 has_many table1s
通过外键的命名规则扫描所有数据库,建立表关联的过程如下:
1) 标准匹配
对每一张表,查看所有以“_id”结尾的字段名,把该字段的去掉“_id”的前缀匹配表名,如果找到了,就建立两个表的关联关系。匹配表名的时候是不区分数据库的,所以表关联支持跨数据库的关联。
2) 去前缀后匹配
对于以“id”结尾的字段名,如果上一步没有匹配到表名,那么进一步去掉以“”分割的前缀,把剩下的中间部分去匹配表名
3) 序列化关系数据,并在运行时读取
上面扫描得到的两个关系:belongs_to 和 has_many,组织成两个 hash 表,key 是表名,value 是对应关系的表名的数组,然后把这两个 hash 对象序列化成 YAML 文件,文件名分别是 belongs.yaml 和 many.yaml。Rails 程序启动时,会读取这两个文件,然后重新反序列化得到 belongs_to 和 has_many 的两个 hash 表。
6.3 代码生成过程
代码生成系统不是从零开始开发的,而是重用了 rails 框架提供的 scaffold 功能。Rails 框架提供了比较完善的单表 CRUD 功能。整个代码生成系统基本按照下面的流程实现的:
- 第一步是给每张表提供基础的 CRUD 功能,直接使用了 rails 的 scaffold 功能。
- 然后是实现单表的查询功能,根据 URL 中传递的查询参数,在模版 controller 中增加对应的 where 条件。
- 接着是批量操作相关的 CUD 功能,基本上就是在一个循环里实现单个表的 CUD 逻辑。
- 然后是关联操作相关的 CRUD 功能,和批量操作的区别在于要验证关联关系。
- 接着实现关联表的查询功能,和单表查询的区别在于两点: 1 要验证关联关系,2 要做两个表之间的 join
- 最后修改 rails 的启动代码,实现表关联数据的预加载,增加对 JSON 格式的验证等。
Q&A
提问:REST 是对接口的一种约束或者说协议,这么理解对吗?
袁新宇:REST 是一种架构风格,简单理解就是我们现在使用的基于 Web 的网络架构,RESTful API 则是一组满足 REST 架构的 API 约定。有两种经典的图
REST 架构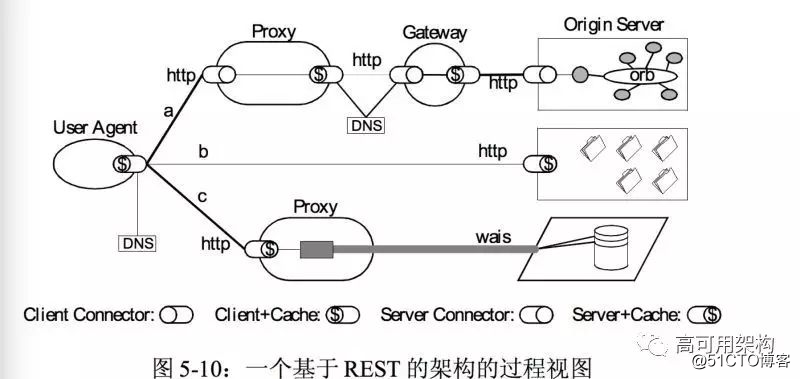
RESTful API 约定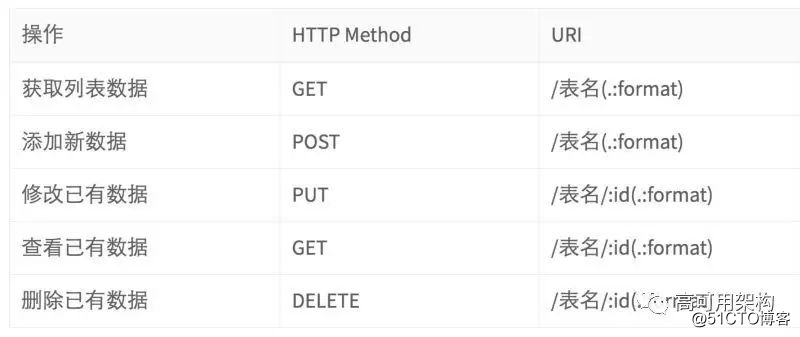
提问:REST、SOAP、XML-RPC 能简单对比下吗?
袁新宇:个人理解 REST 是一种架构风格,而 RESTful API 则更合适和 SOAP、XML-RPC 对比。SOAP 是早期的一个 Web Service 规范,以 XML 格式为载体,目前在 .net 社区还有使用,缺点是太笨重/繁琐。XML-RPC 范围更窄,不包括 SOAP 的服务注册发现等内容
提问:分享中提到的自动化问题,是通过通用的接口,在接口参数中上传对应的表映射关系,然后转换成对相应的表操作吗?
袁新宇:比如数据库有两张表 warehouses/companies,那么通过代码生成系统会生成一个web应用,提供两个 RESTful API
/warehouses.json?s[like[name,address]]=测试
/warehouses.json?page=1&per=100&count=1
/warehouses.json?s[company.name]=测试公司
/companies/1.json?many=warehouses
提问:请问要部署这样的系统,除了要满足文中说的数据库约定,配置复杂吗,需要进行什么样的配置?
袁新宇:配置不复杂,主要就是配置数据库,然后生成代码。这块可以补充说明一下。
数据库配置文件是 config 目录下的 database.yaml,在这个文件里配置数据库连接。默认的三个数据库连接是 development/test/production,分别代表开发/测试/发布环境下的默认数据库连接。如果一个环境下要连多个数据库,按照类似的命名规则加前缀即可。比如 user_development / user_test / user_production 等。
默认情况下,在开发环境使用的是本地文件缓存;在发布环境下使用的是 memcache。Memcache 的服务器地址要设置在环境变量“MEMCACHE_SERVERS”中。
提问:类似的系统 Java 写的有吗?
袁新宇:单表 CURD 的,Java 也有类似的,但是成熟度不高。多表的应该没有。
提问:RESTful 扩展部分,会不会有性能问题呢,比如模糊查询或者 join 操作,这块怎么考虑的?分表分库是生成一个项目吧?
袁新宇:需要到分表分库的阶段,那么也就不适合用代码生成这类方案的。因为数据量这么大,应该是一个成功的项目了,自然有足够的开发资源来支撑它。这次分享里提到的多数据库,是业务分离的需要。不同的数据库由不同的团队管理。分表分库则是一个开发团队,为了性能/数据量把一个数据库分拆为多个。
提问: GraphQL 和 RESTful 怎么看?上述对 RESTful 的拓展和 GraphQL 很像
袁新宇:GraphQL 更灵活,以后也许会逐步流行起来,对于性能要求很高(需要扣每一个输出的字段,不能有冗余)/使用很广泛的项目(一个接口不能满足多个调用方的不同的场景需求),使用 GraphQL 定义接口很好的。但是 GraphQL 还没有太多的库/框架来提高开发/测试的效率。
相关阅读
- 从LAMP到框架式开发的SOA:土巴兔8年架构之道
- 跨机房微服务高可用方案:DerbySoft路由服务设计与实现
热门活动
GIAC 全球互联网架构大会将在 12 月 16 ~ 17 日在北京举行。大会精心策划了语言与架构专题,将会介绍 Python, Java 等语言场景的微服务架构。
访问 thegiac.com 或识别二维码了解全部精彩议程,最终演讲议题以官网为准。
参加 GIAC,全面了解最新互联网架构知识,最后一周优惠,购买双日套票,高可用架构后花园会员最低仅需 900 元,非会员最低只需 1,260 元,识别二维码或点击阅读原文进入购买页面。


以上是关于走向无后端的系统开发实践:CRUD自动化与强约定的REST接口的主要内容,如果未能解决你的问题,请参考以下文章