Zookeeper的简单入门
Posted codeli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Zookeeper的简单入门相关的知识,希望对你有一定的参考价值。
Zookeeper
一、引言
在分布式环境下,如果舍弃springcloud,使用其他的分布式框架,那么注册中心,配置集中管理,集群管理,分布式锁,分布式任务,队列管理想单独实现怎么处理?
分布式系统面临的问题
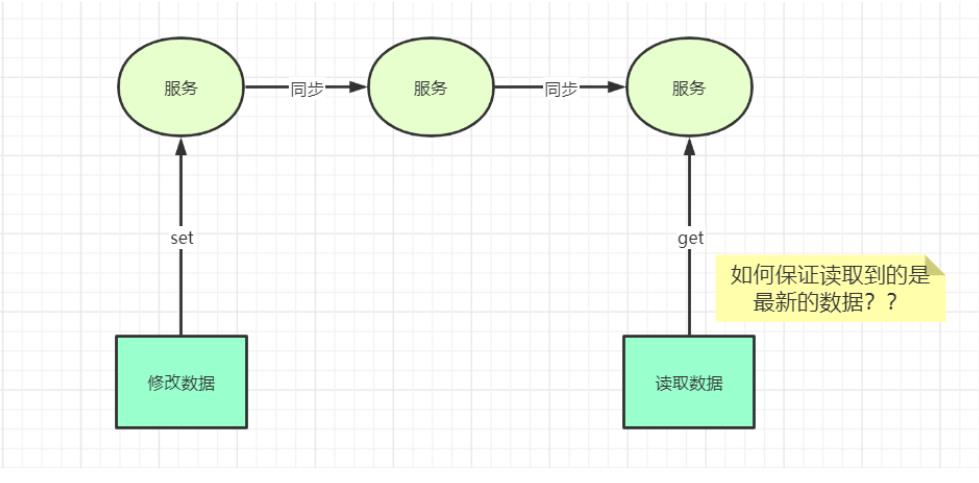
? 1、分布式系统如何实现对统一资源的访问,保证数据的一致性
? 2、集群中的Master宕机了,传统的做法是什么?zookeeper又是如何做的?
二、Zookeeper的介绍
2.1 简介
ZooKeeper是一个分布式服务的治理框架,是Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。
简单来说zookeeper=文件系统+监听通知机制
文件系统:zookeeper的文件系统就是一个树形结构的节点,节点可以存储数据
监听通知机制:客户端可以实时的对节点中的数据进行监听,当数据发送改变时,会通知监听机制
2.1 实现原理
zookepper服务正常启动后,所有的zookepper客户端都会监听某一个节点,当这个节点内容发生个改变后,zookeeper的服务会给所有的zookeeper客户端发送一个事件通知,客户端收到这个事件通知后,会拉取最新的数据
三、Zookeeper的安装
docker-compose.yml
version: "3.1"
services:
zk:
image: daocloud.io/daocloud/zookeeper:latest
restart: always
container_name: zk
ports:
- 2181:2181
四、Zookeeper架构【重点】
4.1 Zookeeper树形结构
每个子目录项都被成为一个znode节点(目录节点),和文件系统一样,我们能够自由的增加和删除节点,以及能够在节点中添加和删除子节点,唯一不同的是,zookeeper的节点可以用来存储数据

4.2 znode类型
PERSISTENT-持久化目录节点
? 客户端与zookeeper断开连接后,该节点依旧存在
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
? 客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号EPHEMERAL-临时目录节点
? 客户端与zookeeper断开连接后,该节点被删除
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
? 客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
简单说,znode分四种类型:
? 永久有序类型、永久无序类型、临时有序类型、临时无序类型,所有的有序类型在添加的时候,zookeeper会自动为我们添加一个id,用于排序,而无序的只有节点名称,zookeeper中的节点是不允许重复的
五、zookeeper的常用命令
5.1 进入zookeeper的客户端
先进入到zookeeper的容器中 我这里容器的名称为zookeeper
docker exec -it zookeeper /bin/bash # 进入zookeeper容器
#进入/opt/zookeeper/bin目录运行客户端
./zkCli.sh #进入客户端
5.2 常用命令

1、查询该节点的子节点
ls [节点]
2、创建节点
-s :表示是一个顺序节点
-e :表示是一个临时节点
path:表示路径
data:表示数据内容
acl:表示权限
如:create -s -e /demo 123 创建一个临时有序的节点demo,存储在跟目录下,节点的数据为123
create [-s] [-e] path data acl
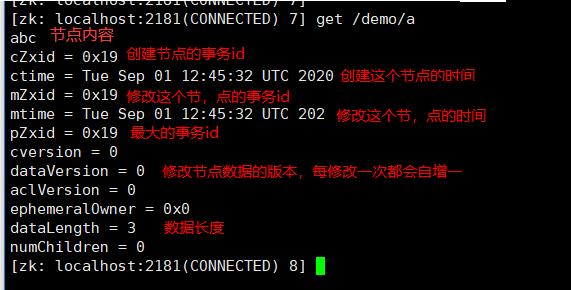
3、获取节点数据
get path # path表示节点地址
获取的节点信息
4、节点的删除
delete path #只能删除子节点,不能删除整个目录
rmr path # 可以删除整个目录
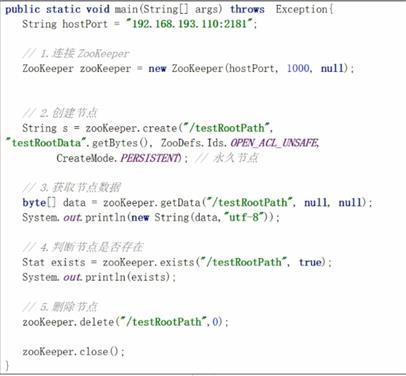
六、java操作zookeeper
6.1 使用最原生的api操作
6.2 使用zookeeper高级api操作节点
需要导入依赖
<!--zookeeper的高级API,内部已经包含了zookeeper依赖-->
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>2.12.0</version>
</dependency>
6.2.1 获取高级客户端CuratorFramework
/**
* 获取zookeeper客户端的工具类
* @param
* @return
*/
public class ZKUtils {
public static CuratorFramework getCKClient(){
//1、设置连接zookeeper的策略,超时时间2s后再重连3次
ExponentialBackoffRetry retry = new ExponentialBackoffRetry(2000, 3);
//2、创建zookeeper的客户端
CuratorFramework cf = CuratorFrameworkFactory.builder().connectString("192.168.40.100:2181").retryPolicy(retry).build();
//3、启动客户端
cf.start();
return cf;
}
}
添加节点
/**
* 测试添加节点
*/
@Test
public void testAddNode() throws Exception {
//1、获取zookeeper的客户端
CuratorFramework cf = ZKUtils.getCKClient();
//2、创建一个节点,数据是10
String s = cf.create().forPath("/test01", "10".getBytes("utf-8"));
}
添加永久有序节点
/**
* 测试添加永久有序节点
*/
@Test
public void testAddNode2() throws Exception {
//1、获取zookeeper的客户端
CuratorFramework cf = ZKUtils.getCKClient();
//2、设置节点永久有序
String test02 = cf.create().withMode(CreateMode.PERSISTENT_SEQUENTIAL).forPath("/test02", "test2".getBytes("utf-8"));
System.out.println(test02);
}
查询节点数据
/**
* 测试获取节
*/
@Test
public void testGetData() throws Exception {
//1、获取客户端
CuratorFramework cf = ZKUtils.getCKClient();
//2、根据节点目录获取数据
byte[] bytes = cf.getData().forPath("/test01");
System.out.println(new String(bytes));
}
查询子节点名称
/**
* 查询子节点名称
* @throws Exception
*/
@Test
public void testChildren() throws Exception {
CuratorFramework cf = ZKUtils.getCKClient();
List<String> nodes = cf.getChildren().forPath("/");
for (String node : nodes) {
System.out.println(node);
}
}
修改节点数据
/**
* 测试节点数据的修改
*/
@Test
public void testNodeUpdate() throws Exception {
//1、获取客户端
CuratorFramework cf = ZKUtils.getCKClient();
Stat stat = cf.setData().forPath("/test01", "20".getBytes("utf-8"));
byte[] bytes = cf.getData().forPath("/test01");
System.out.println(new String(bytes));
}
删除节点
/**
* 测试删除节
*/
@Test
public void testRemoveNode() throws Exception {
CuratorFramework cf = ZKUtils.getCKClient();
Void aVoid = cf.delete().forPath("/test01");
}
查询节点状态,Stat:封装了节点的一些状态,比如创建的事务id,创建的时间,修改的时间等......
/**
*测试查询节点状态
* @throws Exception
*/
@Test
public void testStatus() throws Exception {
CuratorFramework client = ZKUtils.getCKClient();
Stat stat = client.checkExists().forPath("/demo");
System.out.println(stat);
}
6.2 zookeeper的节点监听机制
/**
* 测试zookeeper的监听机制
*/
@Test
public void testListener() throws IOException {
//1、使用工具类获取高级api对象CuratorFramework
CuratorFramework cf = ZKUtils.getCKClient();
//2、设置监听的节点
TreeCache treeCache = new TreeCache(cf,"/demo");
//3、设置触发监听机制的回调函数
treeCache.getListenable().addListener(new TreeCacheListener() {
//当监听的节点对象触发监听机制,就会调用该回调方法
@Override
public void childEvent(CuratorFramework client, TreeCacheEvent event) throws Exception {
//4、获取时间的类型,返回的Type是一个匿名内部枚举类,
//NODE_ADDED:节点添加
// NODE_UPDATED, 节点的修改
// NODE_REMOVED, 节点的删除
//INITIALIZED 节点初始化
TreeCacheEvent.Type type = event.getType();
System.out.println(type);
//节点发送的数据
ChildData data = event.getData();
String path = data.getPath();
byte[] data1 = data.getData();
Stat stat = data.getStat();
switch (type){
case NODE_ADDED: // 添加事件
System.out.println("添加【"+data.getPath()+"】节点");
break;
case NODE_UPDATED: // 添加事件
System.out.println("修改【"+data.getPath()+"】节点内容:【"+new String(data.getData())+"】,version:"+data.getStat().getVersion());
break;
case NODE_REMOVED:
System.out.println("删除【"+data.getPath()+"】节点");
break;
default:
break;
}
}
});
//阻塞线程,使线程一致处于监听状态
System.in.read();
}
七、应用场景
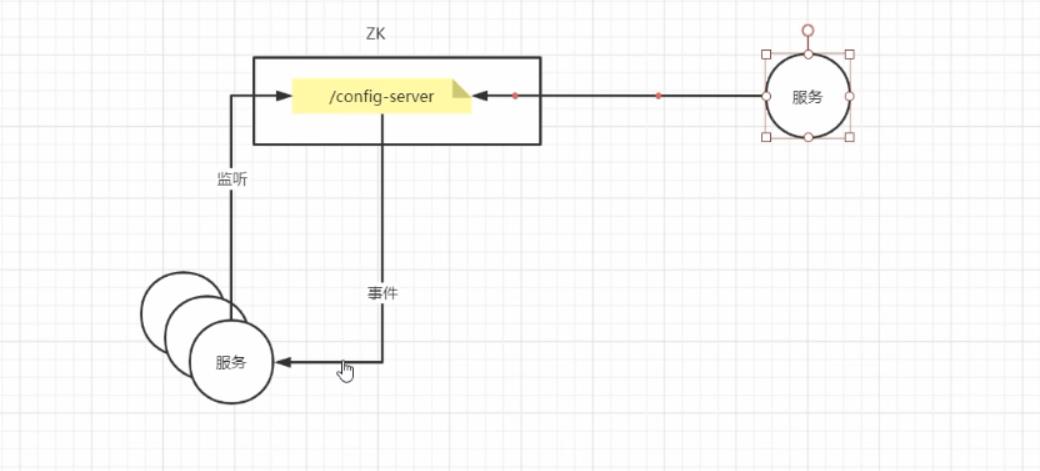
7.1 配置文件管理
? 将需要统一管理的配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中。
7.2 集群管理
? 所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与 zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除。新机器加入也是类似,
我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
7.3 分布式锁
我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。用完删除掉自己创建的distribute_lock 节点就释放出锁
7.4 命名服务(Dubbo监控中心原理)
在日常开发中,我们会遇到这样的场景:服务A需要访问服务B,但是服务B还在开发过程中(未完成),那么服务A(此时已完成)就不知道如何获取服务B的访问路径了,使用zookeeper的服务就可以简单解决:服务B部署成功后,可以先到zookeeper注册服务(即在zookeeper添加节点/service/B和节点数据)。服务A开发结束后,部署到服务器,然后服务A监控zookeeper服务节点/service/B,如果发现节点有数据了,那么服务A就可以访问服务B了。
7.5 发现服务

注册一个持久节点/service/business/what,他下面的每个子节点都是一个可用服务,保存了服务的地址端口等信息,服务调用者通过zookeeper获取/service/business/what所有子节点信息来得到可用的服务。下面的节点都是临时节点,服务器启动的时候会过来注册一个临时节点,服务器挂掉之后或主动关闭之后,临时节点会自动移除,这样就可以保证使用者获取的what服务都是可用的,而且可以动态的扩容缩容。
?
八、Zookeeper集群【重点】
8.1 Zookeeper集群架构图
| 集群架构图 |
|---|
 |
8.2 Zookeeper集群中节点的角色
- Leader(Master):事务请求的唯一处理者,也可以处理读请求。
- Follower(Slave):可以直接处理客户端的读请求,并向客户端响应;但其不会处理事务请求,其只会将客户端事务请求转发给Leader来处理,同步 Leader 中的事务处理结果;Leader 选举过程的参与者,具有选举权与被选举权。(就好像正式工)
- Observer(Slave):可以理解为不参与 Leader 选举的 Follower,在 Leader 选举过程中没有选举权
与被选举权;同时,对于 Leader 的提案没有表决权。用于协助 Follower 处理更多的客
户端读请求。Observer 的增加,会提高集群读请求处理的吞吐量,但不会增加事务请求
的通过压力,不会增加 Leader 选举的压力。(就好像临时工)
8.3 Zookeeper数据同步
? ZooKeeper 集群的所有机器通过一个 Leader来完成写服务(也可以完成读)。Follower只提供读服务,不能提供写服务。
1、客户端发送写的命令给zookeeper
2、zookeeper收到命令后将这个命令发送给领导者leader
3、领导者leader接收到这个命令后将执行这个命令
4、领导者leader执行完这个命令后广播给所有的追随者follower(从而导致数据的一致性)
5、所有的追随者follower收到广播后也在执行写的命令
6、所有的追随者follower写完后,向领导者leader汇报写的情况,是写成功了还是写失败了
7、领导者leader收到所有追随者follwer的汇报情况后,只要有一半的成功就广播第二个命令,事务提交
8、追随者follower收到广播后进行事务提交
8.4 Zookeeper选举
每一个Zookeeper服务都会被分配一个全局唯一的myid,myid是一个数字。
Zookeeper在执行写数据时,每一个节点都有一个自己的FIFO的队列。保证写每一个数据的时候,顺序是不会乱的,Zookeeper还会给每一个数据分配一个全局唯一的zxid,数据越新zxid就越大。
选举Leader:
- 选举出zxid最大的节点作为Leader。
- 在zxid相同的节点中,选举出一个myid最大的节点,作为Leader。
? zookeeper会出现这样一种情况,当master节点因为网络故障与其他节点失去联系时,剩余节点会重新进行leader选举。问题在于,选举leader的时间太长,30 ~ 120s, 且选举期间整个zk集群都是不可用的,这就导致在选举期间注册服务瘫痪。在云部署的环境下,因网络问题使得zk集群失 去master节点是较大概率会发生的事,虽然服务能够最终恢复,但是漫长的选举时间导致的注册长期不可用是不能容忍的。
8.5 搭建Zookeeper集群
1、2181:对cline端提供服务
2、3888:选举leader使用
3、2888:集群内机器通讯使用(Leader监听此端口)
version: "3.1"
services:
zk1:
image: zookeeper
restart: always
container_name: zk1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk2:
image: zookeeper
restart: always
container_name: zk2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
zk3:
image: zookeeper
restart: always
container_name: zk3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zk1:2888:3888;2181 server.2=zk2:2888:3888;2181 server.3=zk3:2888:3888;2181
6.6 Zookeeper过半数存活原则
? 在zookeeper集群中,当存活的机器数量超过总机器的一半的时候,整个集群才能正常工作,否则拒绝访问。基于过半数存活原则,zookeeper的集群机器数量一定是奇数台,因为2N+1和2N+2的容灾能力是一样的,基于成本考虑2N+1台的选择方案更优。
6.7 为什么Zookeeper需要设计一个过半数存活机制?
*脑裂问题*
集群中的节点监听不到leader节点的心跳, 就会认为leader节点出了问题, 此时集群将分裂为不同的小集群, 这些小集群会各自选举出自己的leader节点, 导致原有的集群中出现多个leader节点。
为了防止网络脑裂,保证数据的强一致性,因为整个集群中,有可能因为网络问题"脑裂",导致整个集群分为2个甚至多个集群,如果没有过半数存活机制,那么整个zookeeper会变成多个集群,那么zookeeper提供的数据无法再保证数据一致性;

脑裂:指因网络问题,原本一个完整的集群被支分为多个小集群,从而导致数据的存储不一致
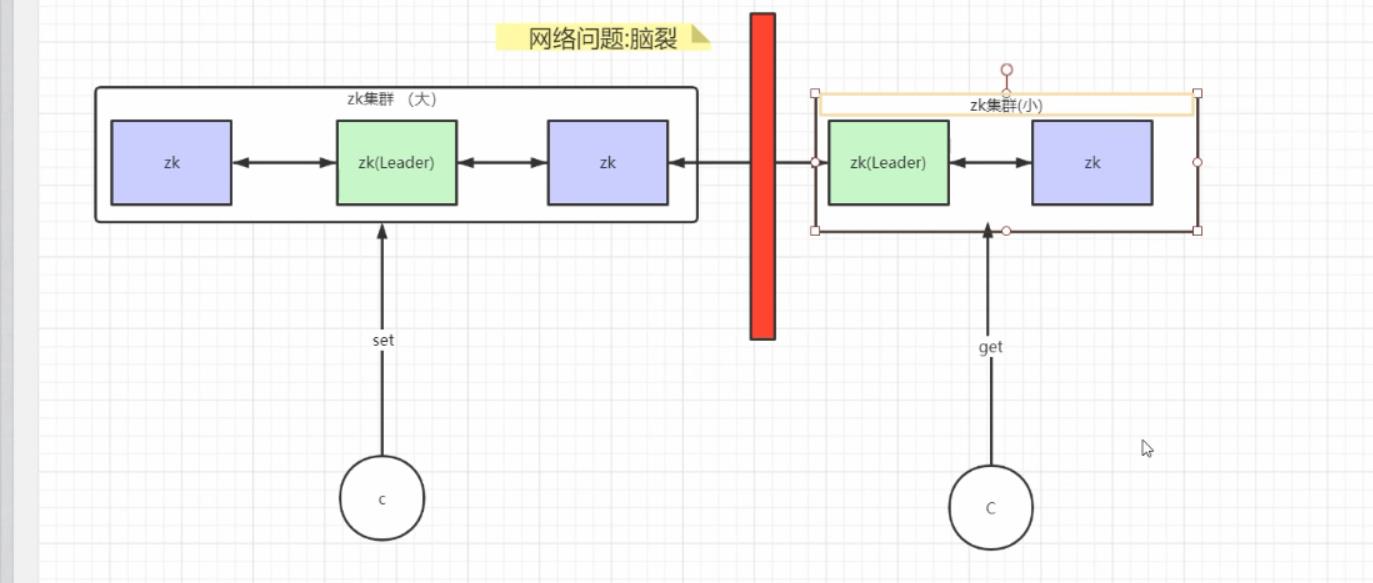
zookeeper采取的策略:集群过半数存活原则
当zookeeper集群出现脑裂问题的时候,只有超过原本集群数量一般以上的小集群才会存活
比如原本集群是5台,脑类后分成2 、3集群,然而2小集群就不再存活,让3存活,从而保证数据的一致性
所以zookeeper选择过半数存活的原则是因为解决脑裂问题和保证数据一致性
以上是关于Zookeeper的简单入门的主要内容,如果未能解决你的问题,请参考以下文章