某音直播视频爬取
Posted xjrecord
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了某音直播视频爬取相关的知识,希望对你有一定的参考价值。
在很火的某音平台,爬取一些自己感兴趣的东西,一路上跌跌撞撞,做个记录,便于日后翻看回忆。
1、手动拉流(wireshark+VLC)
最最开始,使用wireshark抓包,然后拿到流后,结合VLC手动拉流,进度极慢,不过也是比较适合小量拉流,不然脚本维护不是很熟练的话,并没有事半功倍的效果。
2、读取json文件自动保存(fiddler+python+ffmpeg)
由于进度太慢,然后开始在网上搜索别人的教程跟着一步步走,但是还是相对比较曲折。起初还是找flv格式的流直接保存,不过效率是有提高,后来同事说ffmpeg直接保存m3u8的流更快,果不其然,的确要好一些,也算是尝到了一些甜头。
当然还是有一个问题,效率还是比较低,只能保存已经浏览的直播间的流。
因为我是手动滑到不同的直播间,然后用fiddlerScript将进入直播间的url保存到json文件,再用python读取json文件找到流地址,再ffmpeg自动分割保存,保存任意时长的视频。
3、尝试全自动化
工具:手机(模拟器)连接,python,ffmpeg,adb,weditor,fiddler
(1)adb建立连接;
(2)weditor连接设备,定位元素。(已经在上一篇中有记录https://www.cnblogs.com/xjrecord/p/13680248.html,也是还在摸索的路上,嘻嘻)
(3)python语言,调用uiautomator2和subprocess包;
(4)fiddler保存流地址到log文件中;
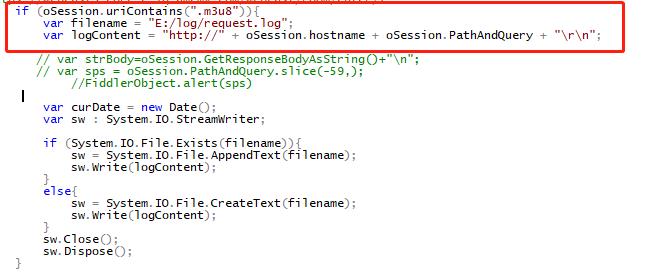
(5)读取文件中的流地址,ffmpeg分割保存视频
def shell(cmd):
print(‘执行命令:‘ + cmd)
p = subprocess.Popen(cmd, stdin=subprocess.PIPE, stdout=subprocess.PIPE, shell=True)
(stdout_output, err_output) = p.communicate()
time.sleep(2)
if err_output != None and len(err_output) != 0:
print("Shell err_output: " + str(err_output))
# print("stdout_output: " + str(stdout_output))
return stdout_output.decode().strip()
path =‘E:/dy/video/‘
count = 1
with open(r‘E:/log/request1.jsonl‘, ‘r‘) as f:
url = f.readline()[:-1]
print(url)
save_path =path + ‘dy-‘ +str(count) + ‘.mp4‘
cmd_save = "ffmpeg -i " + url + " -vcodec copy -t 15 " + save_path
shell(cmd_save)
以上是关于某音直播视频爬取的主要内容,如果未能解决你的问题,请参考以下文章