解惑“高深”的Kafka时间轮原理,原来也就这么回事!
Posted huaweiyun
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了解惑“高深”的Kafka时间轮原理,原来也就这么回事!相关的知识,希望对你有一定的参考价值。
【摘要】 Kafka时间轮是Kafka实现高效的延时任务的基础,它模拟了现实生活中的钟表对时间的表示方式,同时,时间轮的方式并不仅限于Kafka,它是一种通用的时间表示方式,本文主要介绍Kafka中的时间轮原理。
Kafka中存在一些定时任务(DelayedOperation),如DelayedFetch、DelayedProduce、DelayedHeartbeat等,在Kafka中,定时任务的添加、轮转、执行、消亡等是通过时间轮来实现的。(时间轮并不是Kafka独有的设计,而是一种通用的实现方式,Netty中也有用到时间轮的方式)
1. 时间轮是什么
参考网上的两张图(摘自 https://blog.csdn.net/u013256816/article/details/80697456)
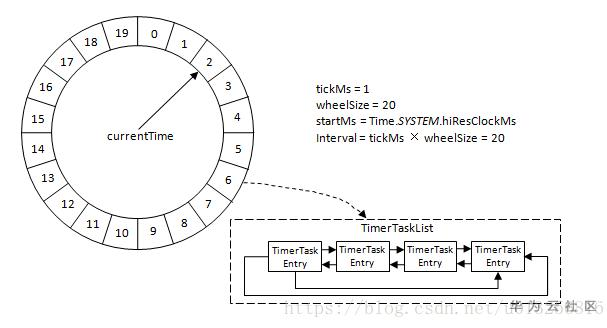
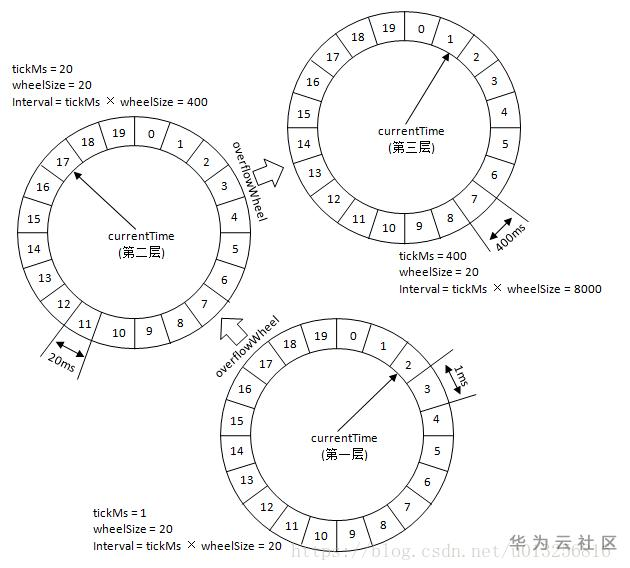
这两张图就比较清楚的说明了Kafka时间轮的结构了:类似现实中的钟表,由多个环形数组组成,每个环形数组包含20个时间单位,表示一个时间维度(一轮),如:第一层时间轮,数组中的每个元素代表1ms,一圈就是20ms,当延迟时间大于20ms时,就“进位”到第二层时间轮,第二层中,每“一格”表示20ms,依此类推…
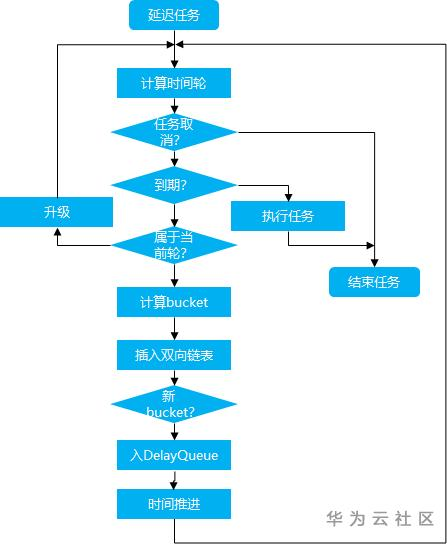
对于一个延迟任务,大体包含三个过程:进入时间轮、降级和到期执行。
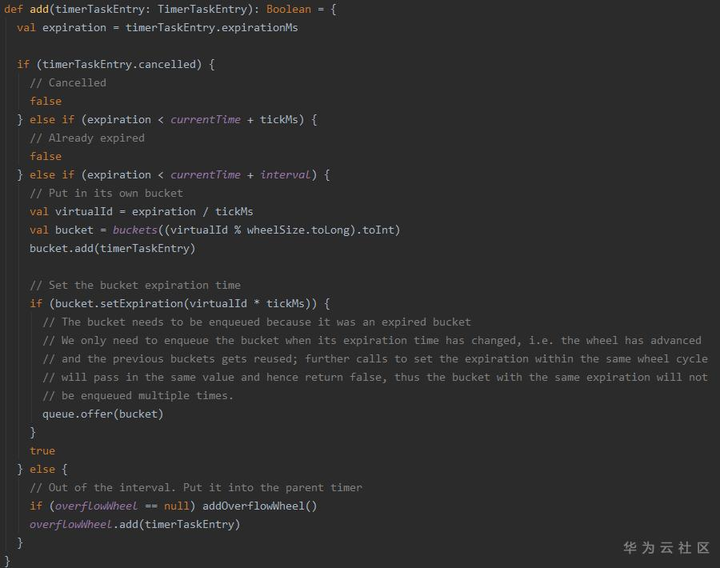
- 进入时间轮
1. 根据延迟时间计算对应的时间轮“层次”(如钟表中的“小时级”还是“分钟级”还是“秒级”,实际上是一个不断“升级”的过程,直到找到合适的“层次”)
2. 计算在该轮中的位置,并插入该位置(每个bucket是一个双向链表,可能包含多个延迟任务,这也是时间轮提高效率的一大原因,后面会提到)
3. 若该bucket是首次插入,需要将该bucket加入DelayQueue中(DelayQueue的引入是为了解决“空推进”,后面会提到)
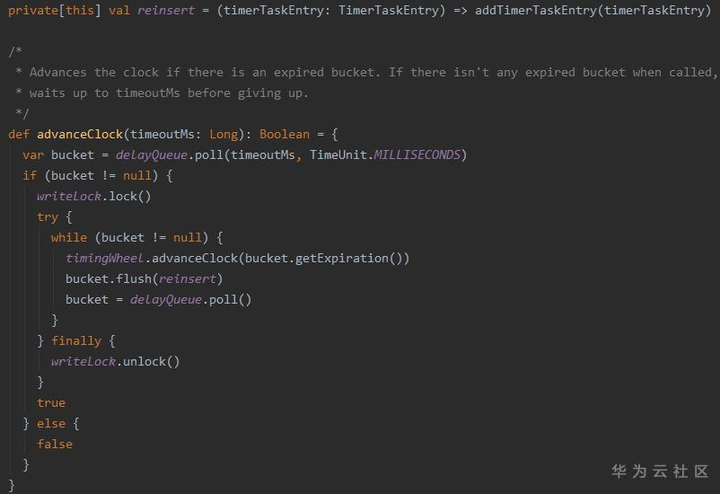
- 降级
1. 当时间“推进”到某个bucket时,说明该bucket中的任务在当前时间轮中的时间已经走完,需要进行“降级”,即进入更小粒度的时间轮中,reinsert的过程和进入时间轮是类似的
- 到期执行
1. 在reinsert的过程中,若发现已经到期,则执行这些任务
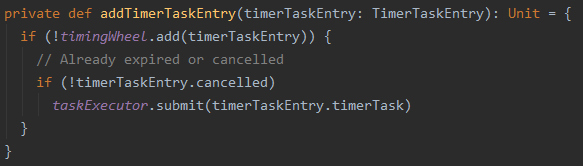
整体过程大致如下:
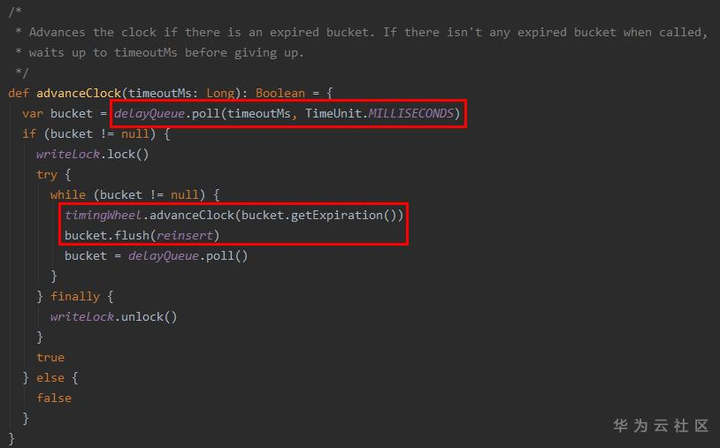
2. 时间的“推进”
一种直观的想法是,像现实中的钟表一样,“一格一格”地走,这样就需要有一个线程一直不停的执行,而大多数情况下,时间轮中的bucket大部分是空的,指针的“推进”就没有实质作用,因此,为了减少这种“空推进”,Kafka引入了DelayQueue,以bucket为单位入队,每当有bucket到期,即queue.poll能拿到结果时,才进行时间的“推进”,减少了 ExpiredOperationReaper 线程空转的开销。
3. 为什么要用时间轮
用到延迟任务时,比较直接的想法是DelayQueue、ScheduledThreadPoolExecutor 这些,而时间轮相比之下,最大的优势是在时间复杂度上:
时间复杂度对比:
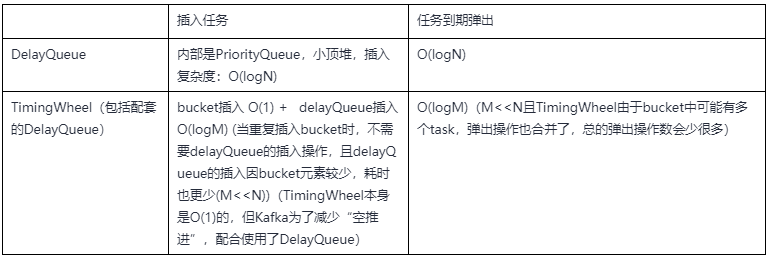
因此,理论上,当任务较多时,TimingWheel的时间性能优势会更明显
总结一下Kafka时间轮性能高的几个主要原因:
(1)时间轮的结构+双向列表bucket,使得插入操作可以达到O(1)的时间复杂度
(2)Bucket的设计让多个任务“合并”,使得同一个bucket的多次插入只需要在delayQueue中入队一次,同时减少了delayQueue中元素数量,堆的深度也减小,delayqueue的插入和弹出操作开销也更小
以上是关于解惑“高深”的Kafka时间轮原理,原来也就这么回事!的主要内容,如果未能解决你的问题,请参考以下文章