为什么开发人员必须要了解数据库锁?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了为什么开发人员必须要了解数据库锁?相关的知识,希望对你有一定的参考价值。
1.锁?
1.1何为锁
锁在现实中的意义为:封闭的器物,以钥匙或暗码开启。在计算机中的锁一般用来管理对共享资源的并发访问,比如我们java同学熟悉的Lock,synchronized等都是我们常见的锁。当然在我们的数据库中也有锁用来控制资源的并发访问,这也是数据库和文件系统的区别之一。
1.2为什么要懂数据库锁?
通常来说对于一般的开发人员,在使用数据库的时候一般懂点DQL(select),DML(insert,update,delete)就够了。
小明是一个刚刚毕业在互联网公司工作的Java开发工程师,平常的工作就是完成PM的需求,当然在完成需求的同时肯定逃脱不了spring,springmvc,mybatis的那一套框架,所以一般来说sql还是自己手写,遇到比较复杂的sql会从网上去百度一下。对于一些比较重要操作,比如交易啊这些,小明会用spring的事务来对数据库的事务进行管理,由于数据量比较小目前还涉及不了分布式事务。
前几个月小明过得都还风调雨顺,知道有一天,小明接了一个需求,商家有个配置项,叫优惠配置项,可以配置买一送一,买一送二等等规则,当然这些配置是批量传输给后端的,这样就有个问题每个规则都得去匹配他到底是删除还是添加还是修改,这样后端逻辑就比较麻烦,聪明的小明想到了一个办法,直接删除这个商家的配置,然后全部添加进去。小明马上开发完毕,成功上线。
开始上线没什么毛病,但是日志经常会出现一些mysql-insert-deadlock异常。由于小明经验比较浅,对于这类型的问题第一次遇见,于是去问了他们组的老司机-大红,大红一看见这个问题,然后看了他的代码之后,输出了几个命令看了几个日志,马上定位了问题,告诉了小明:这是因为delete的时候会加间隙锁,但是间隙锁之间却可以兼容,但是插入新的数据的时候就会因为插入意向锁会被间隙锁阻塞,导致双方被资源被互占,导致死锁。小明听了之后似懂非懂,由于大红的事情比较多,不方便一直麻烦大红,所以决定自己下来自己想。下班过后,小明回想大红说的话,什么是间隙锁,什么是插入意向锁,看来作为开发者对数据库不应该只会写SQL啊,不然遇到一些疑难杂症完全没法解决啊。想完,于是小明就踏上了学习Mysql锁这条不归之路。
2.InnoDB
2.1mysql体系架构
小明没有着急去了解锁这方面的知识,他首先先了解了下Mysql体系架构: 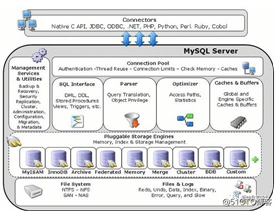
可以发现Mysql由连接池组件、管理服务和工具组件、sql接口组件、查询分析器组件、优化器组件、 缓冲组件、插件式存储引擎、物理文件组成。
小明发现在mysql中存储引擎是以插件的方式提供的,在Mysql中有多种存储引擎,每个存储引擎都有自己的特点。随后小明在命令行中打出了:
show engines G
;一看原来有这么多种引擎。
又打出了下面的命令,查看当前数据库默认的引擎:
show variables like
‘%storage_engine%‘
;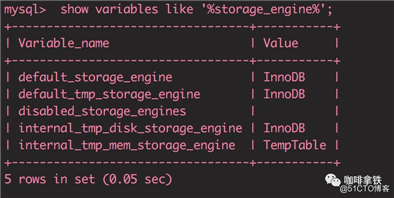
小明恍然大悟:原来自己的数据库是使用的InnoDB,依稀记得自己在上学的时候好像听说过有个引擎叫MyIsAM,小明想这两个有啥不同呢?马上查找了一下资料:
对比项 InnoDB MyIsAM
事务 支持 不支持
锁 支持MVCC行锁 表锁
外键 支持 不支持
存储空间 存储空间由于需要高速缓存,较大 可压缩
适用场景 有一定量的update和Insert 大量的select
小明大概了解了一下InnoDB和MyIsAM的区别,由于使用的是InnoDB,小明就没有过多的纠结这一块。
2.2事务的隔离性
小明在研究锁之前,又回想到之前上学的时候教过的数据库事务隔离性,其实锁在数据库中其功能之一也是用来实现事务隔离性。而事务的隔离性其实是用来解决,脏读,不可重复读,幻读几类问题。
2.2.1 脏读
一个事务读取到另一个事务未提交的更新数据。 什么意思呢?
时间点 事务A 事务B
1 begin;
2 select from user where id = 1; begin;
3
update user set namm = ‘test‘ where id = 1;
4 select from user where id = 1;
5 commit; commit;
在事务A,B中,事务A在时间点2,4分别对user表中id=1的数据进行了查询了,但是事务B在时间点3进行了修改,导致了事务A在4中的查询出的结果其实是事务B修改后的。破坏了数据库中的隔离性。
2.2.2 不可重复读
在同一个事务中,多次读取同一数据返回的结果不同,和脏读不同的是这里读取的是已经提交过后的。
时间点 事务A 事务B
1 begin;
2 select from user where id = 1; begin;
3
update user set namm = ‘test‘ where id = 1;
4
commit;
5 select from user where id = 1;
6 commit;
在事务B中提交的操作在事务A第二次查询之前,但是依然读到了事务B的更新结果,也破坏了事务的隔离性。
2.2.3 幻读
一个事务读到另一个事务已提交的insert数据。
时间点 事务A 事务B
1 begin;
2 select from user where id > 1; begin;
3
insert user select 2;
4
commit;
5 select from user where id > 1;
6 commit;
在事务A中查询了两次id大于1的,在第一次id大于1查询结果中没有数据,但是由于事务B插入了一条Id=2的数据,导致事务A第二次查询时能查到事务B中插入的数据。
事务中的隔离性:
隔离级别 脏读 不可重复读 幻读
未提交读(RUC) NO NO NO
已提交读(RC) YES NO NO
可重复读(RR) YES YES NO
可串行化 YES YES YES
小明注意到在收集资料的过程中,有资料写到InnoDB和其他数据库有点不同,InnoDB的可重复读其实就能解决幻读了,小明心想:这InnoDB还挺牛逼的,我得好好看看到底是怎么个原理。
2.3 InnoDB锁类型
小明首先了解一下Mysql中常见的锁类型有哪些:
2.3.1 S or X
在InnoDb中实现了两个标准的行级锁,可以简单的看为两个读写锁:
- S-共享锁:又叫读锁,其他事务可以继续加共享锁,但是不能继续加排他锁。
- X-排他锁: 又叫写锁,一旦加了写锁之后,其他事务就不能加锁了。
兼容性:是指事务A获得一个某行某种锁之后,事务B同样的在这个行上尝试获取某种锁,如果能立即获取,则称锁兼容,反之叫冲突。
纵轴是代表已有的锁,横轴是代表尝试获取的锁。
. X S
X 冲突 冲突
S 冲突 兼容
2.3.2 意向锁
意向锁在InnoDB中是表级锁,和他的名字一样他是用来表达一个事务想要获取什么。意向锁分为:
- 意向共享锁:表达一个事务想要获取一张表中某几行的共享锁。
- 意向排他锁:表达一个事务想要获取一张表中某几行的排他锁。
这个锁有什么用呢?为什么需要这个锁呢? 首先说一下如果没有这个锁,如果要给这个表加上表锁,一般的做法是去遍历每一行看看他是否有行锁,这样的话效率太低,而我们有意向锁,只需要判断是否有意向锁即可,不需要再去一行行的去扫描。
在InnoDB中由于支持的是行级的锁,因此InnboDB锁的兼容性可以扩展如下:
. IX IS X S
IX 兼容 兼容 冲突 冲突
IS 兼容 兼容 冲突 兼容
X 冲突 冲突 冲突 冲突
S 冲突 兼容 冲突 兼容
2.3.3 自增长锁
自增长锁是一种特殊的表锁机制,提升并发插入性能。对于这个锁有几个特点:
- 在sql执行完就释放锁,并不是事务执行完。
- 对于Insert...select大数据量插入会影响插入性能,因为会阻塞另外一个事务执行。
- 自增算法可以配置。
在MySQL5.1.2版本之后,有了很多优化,可以根据不同的模式来进行调整自增加锁的方式。小明看到了这里打开了自己的MySQL发现是5.7之后,于是便输入了下面的语句,获取到当前锁的模式:
mysql
>
show variables like
‘innodb_autoinc_lock_mode‘
;
+--------------------------+-------+
|
Variable_name
|
Value
|
+--------------------------+-------+
|
innodb_autoinc_lock_mode
|
2
|
+--------------------------+-------+
1
row
in
set
(
0.01
sec
)在MySQL中innodbautoinclock_mode有3种配置模式:0、1、2,分别对应”传统模式”, “连续模式”, “交错模式”。
- 传统模式:也就是我们最上面的使用表锁。
- 连续模式:对于插入的时候可以确定行数的使用互斥量,对于不能确定行数的使用表锁的模式。
- 交错模式:所有的都使用互斥量,为什么叫交错模式呢,有可能在批量插入时自增值不是连续的,当然一般来说如果不看重自增值连续一般选择这个模式,性能是最好的。
2.4InnoDB锁算法
小明已经了解到了在InnoDB中有哪些锁类型,但是如何去使用这些锁,还是得靠锁算法。
2.4.1 记录锁(Record-Lock)
记录锁是锁住记录的,这里要说明的是这里锁住的是索引记录,而不是我们真正的数据记录。
- 如果锁的是非主键索引,会在自己的索引上面加锁之后然后再去主键上面加锁锁住.
- 如果没有表上没有索引(包括没有主键),则会使用隐藏的主键索引进行加锁。
- 如果要锁的列没有索引,则会进行全表记录加锁。
2.4.2 间隙锁
间隙锁顾名思义锁间隙,不锁记录。锁间隙的意思就是锁定某一个范围,间隙锁又叫gap锁,其不会阻塞其他的gap锁,但是会阻塞插入间隙锁,这也是用来防止幻读的关键。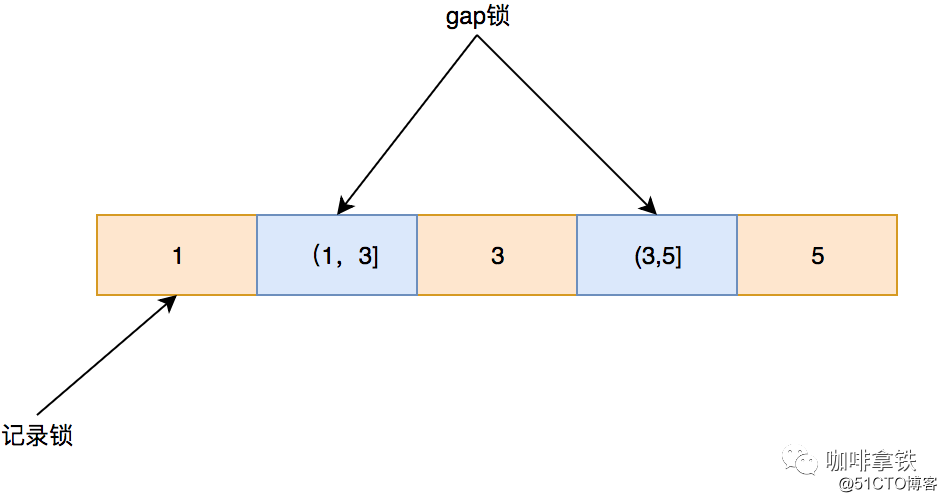
2.4.3 next-key锁
这个锁本质是记录锁加上gap锁。在RR隔离级别下(InnoDB默认),Innodb对于行的扫描锁定都是使用此算法,但是如果查询扫描中有唯一索引会退化成只使用记录锁。为什么呢? 因为唯一索引能确定行数,而其他索引不能确定行数,有可能在其他事务中会再次添加这个索引的数据会造成幻读。
这里也说明了为什么Mysql可以在RR级别下解决幻读。
2.4.4 插入意向锁
插入意向锁Mysql官方对其的解释:
An insert intention lock is a type of gap lock set by INSERT operations prior to row insertion. This lock signals the intent to insert in such a way that multiple transactions inserting into the same index gap need not wait for each other if they are not inserting at the same position within the gap. Suppose that there are index records with values of 4 and 7. Separate transactions that attempt to insert values of 5 and 6, respectively, each lock the gap between 4 and 7 with insert intention locks prior to obtaining the exclusive lock on the inserted row, but do not block each other because the rows are nonconflicting.
可以看出插入意向锁是在插入的时候产生的,在多个事务同时写入不同数据至同一索引间隙的时候,并不需要等待其他事务完成,不会发生锁等待。假设有一个记录索引包含键值4和7,不同的事务分别插入5和6,每个事务都会产生一个加在4-7之间的插入意向锁,获取在插入行上的排它锁,但是不会被互相锁住,因为数据行并不冲突。
这里要说明的是如果有间隙锁了,插入意向锁会被阻塞。
2.5 MVCC
MVCC,多版本并发控制技术。在InnoDB中,在每一行记录的后面增加两个隐藏列,记录创建版本号和删除版本号。通过版本号和行锁,从而提高数据库系统并发性能。
在MVCC中,对于读操作可以分为两种读:
- 快照读:读取的历史数据,简单的select语句,不加锁,MVCC实现可重复读,使用的是MVCC机制读取undo中的已经提交的数据。所以它的读取是非阻塞的。
- 当前读:需要加锁的语句,update,insert,delete,select...for update等等都是当前读。
在RR隔离级别下的快照读,不是以begin事务开始的时间点作为snapshot建立时间点,而是以第一条select语句的时间点作为snapshot建立的时间点。以后的select都会读取当前时间点的快照值。
在RC隔离级别下每次快照读均会创建新的快照。
具体的原理是通过每行会有两个隐藏的字段一个是用来记录当前事务,一个是用来记录回滚的指向Undolog。利用undolog就可以读取到之前的快照,不需要单独开辟空间记录。
3.加锁分析
小明到这里,已经学习很多mysql锁有关的基础知识,所以决定自己创建一个表搞下实验。首先创建了一个简单的用户表:
CREATE TABLE
`user`
(
`id`
int
(
11
)
unsigned
NOT NULL AUTO_INCREMENT
,
`name`
varchar
(
11
)
CHARACTER SET utf8mb4 DEFAULT NULL
,
`comment`
varchar
(
11
)
CHARACTER SET utf8 DEFAULT NULL
,
PRIMARY KEY
(
`id`
),
KEY
`index_name`
(
`name`
)
)
ENGINE
=
InnoDB
AUTO_INCREMENT
=
0
DEFAULT CHARSET
=
utf8mb4 COLLATE
=
utf8mb4_bin
;然后插入了几条实验数据:
insert user
select
20
,
333
,
333
;
insert user
select
25
,
555
,
555
;
insert user
select
20
,
999
,
999
;数据库事务隔离选择了RR
3.1 实验1
小明开启了两个事务,进行实验1.
时间点 事务A 事务B
1 begin;
2 select * from user where name = ‘555‘ for update; begin;
3
insert user select 31,‘556‘,‘556‘;
4
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
小明开启了两个事务并输入了上面的语句,发现事务B居然出现了超时,小明看了一下自己明明是对name = 555这一行进行的加锁,为什么我想插入name=556给我阻塞了。于是小明打开命令行输入:
select
*
from
information_schema
.
INNODB_LOCKS发现在事务A中给555加了Next-key锁,事务B插入的时候会首先进行插入意向锁的插入,于是得出下面结论: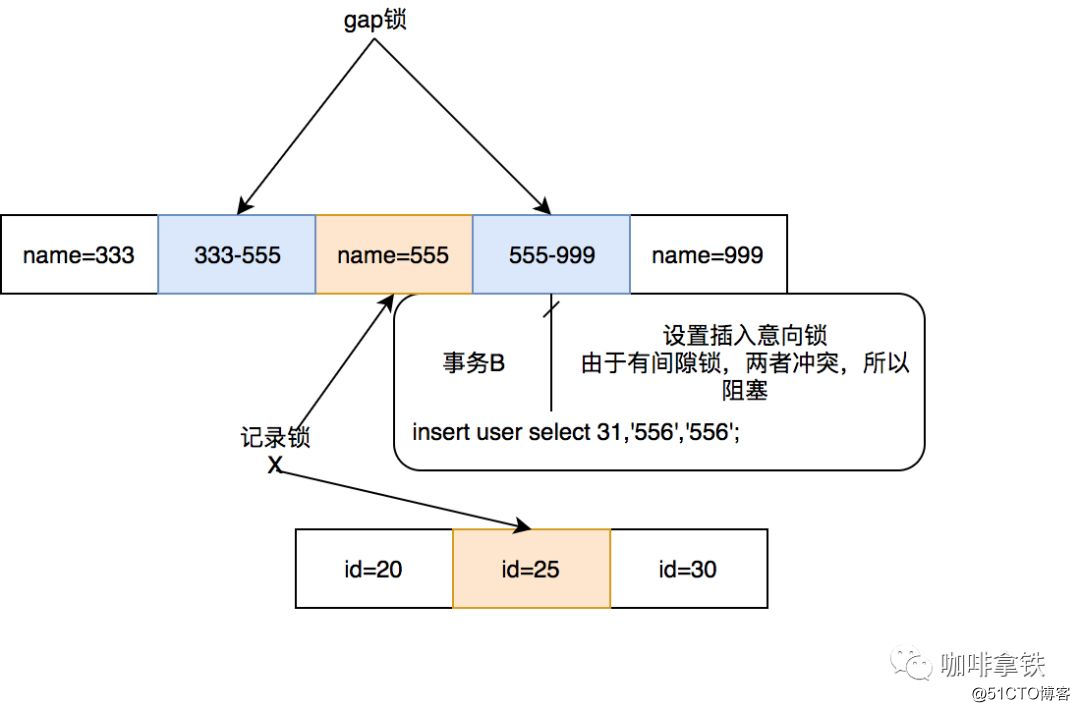
可以看见事务B由于间隙锁和插入意向锁的冲突,导致了阻塞。
3.2 实验2
小明发现上面查询条件用的是普通的非唯一索引,于是小明就试了一下主键索引:
时间点 事务A 事务B
1 begin;
2 select * from user where id = 25 for update; begin;
3
insert user select 26,‘666‘,‘666‘;
4
Query OK, 1 row affected (0.00 sec)
Records: 1 Duplicates: 0 Warnings: 0
居然发现事务B并没有发生阻塞,哎这个是咋回事呢,小明有点疑惑,按照实验1的套路应该会被阻塞啊,因为25-30之间会有间隙锁。于是小明又祭出了命令行,发现只加了X记录锁。原来是因为唯一索引会降级记录锁,这么做的理由是:非唯一索引加next-key锁由于不能确定明确的行数有可能其他事务在你查询的过程中,再次添加这个索引的数据,导致隔离性遭到破坏,也就是幻读。唯一索引由于明确了唯一的数据行,所以不需要添加间隙锁解决幻读。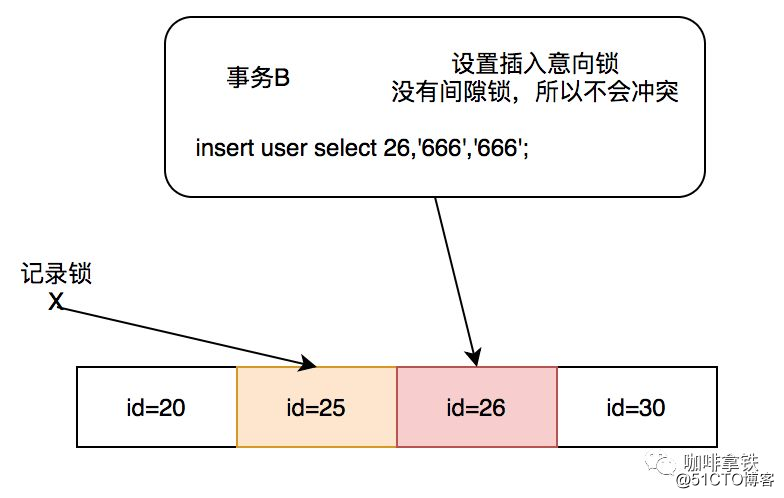
3.3 实验3
上面测试了主键索引,非唯一索引,这里还有个字段是没有索引,如果对其加锁会出现什么呢?
时间点 事务A 事务B
1 begin;
2 select * from user where comment = ‘555‘ for update; begin;
3
insert user select 26,‘666‘,‘666‘;
4
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
5
insert user select 31,‘3131‘,‘3131‘;
6
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
7
insert user select 10,‘100‘,‘100‘;
8
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
小明一看哎哟我去,这个咋回事呢,咋不管是用实验1非间隙锁范围的数据,还是用间隙锁里面的数据都不行,难道是加了表锁吗?
的确,如果用没有索引的数据,其会对所有聚簇索引上都加上next-key锁。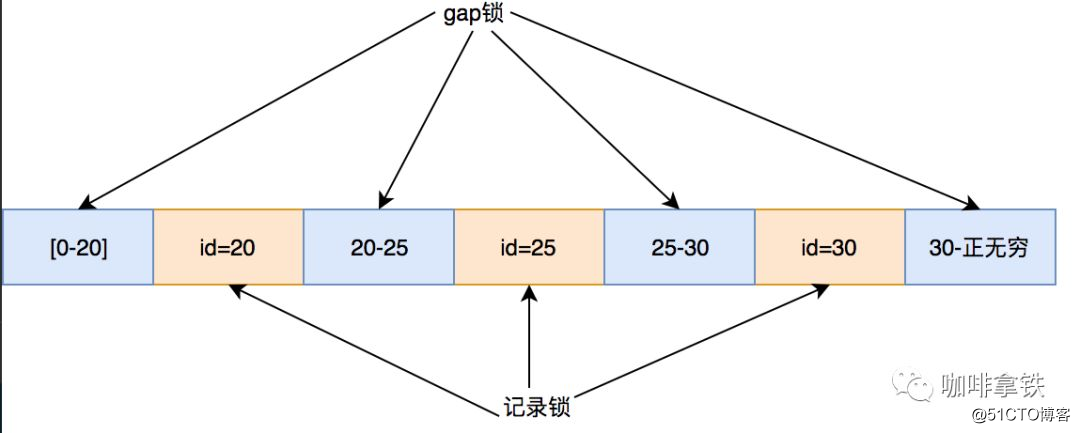
所以大家平常开发的时候如果对查询条件没有索引的,一定进行一致性读,也就是加锁读,会导致全表加上索引,会导致其他事务全部阻塞,数据库基本会处于不可用状态。
4.回到事故
4.1 死锁
小明做完实验之后总算是了解清楚了加锁的一些基本套路,但是之前线上出现的死锁又是什么东西呢?
死锁:是指两个或两个以上的事务在执行过程中,因争夺资源而造成的一种互相等待的现象。说明有等待才会有死锁,解决死锁可以通过去掉等待,比如回滚事务。
解决死锁的两个办法:
- 等待超时:当某一个事务等待超时之后回滚该事务,另外一个事务就可以执行了,但是这样做效率较低,会出现等待时间,还有个问题是如果这个事务所占的权重较大,已经更新了很多数据了,但是被回滚了,就会导致资源浪费。
- 等待图(wait-for-graph): 等待图用来描述事务之间的等待关系,当这个图如果出现回路如下:
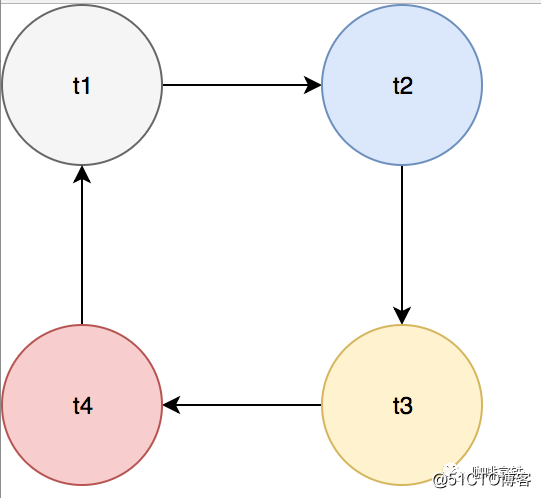
就出现回滚,通常来说InnoDB会选择回滚权重较小的事务,也就是undo较小的事务。
4.2 线上问题
小明到这里,基本需要的基本功都有了,于是在自己的本地表中开始复现这个问题:
时间点 事务A 事务B
1 begin; begin;
2 delete from user where name = ‘777‘; delete from user where name = ‘666‘;
3 insert user select 27,‘777‘,‘777‘; insert user select 26,‘666‘,‘666‘;
4 ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction Query OK, 1 row affected (14.32 sec) Records: 1 Duplicates: 0 Warnings: 0
可以看见事务A出现被回滚了,而事务B成功执行。 具体每个时间点发生了什么呢?
时间点2:事务A删除name = ‘777‘的数据,需要对777这个索引加上next-Key锁,但是其不存在,所以只对555-999之间加间隙锁,同理事务B也对555-999之间加间隙锁。间隙锁之间是兼容的。
时间点3:事务A,执行Insert操作,首先插入意向锁,但是555-999之间有间隙锁,由于插入意向锁和间隙锁冲突,事务A阻塞,等待事务B释放间隙锁。事务B同理,等待事务A释放间隙锁。于是出现了A->B,B->A回路等待。
时间点4:事务管理器选择回滚事务A,事务B插入操作执行成功。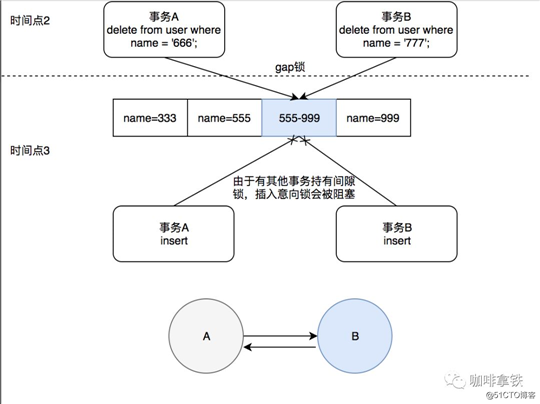
4.3 修复BUG
这个问题总算是被小明找到了,就是因为间隙锁,现在需要解决这个问题,这个问题的原因是出现了间隙锁,那就来去掉他吧:
- 方案一:隔离级别降级为RC,在RC级别下不会加入间隙锁,所以就不会出现毛病了,但是在RC级别下会出现幻读,可提交读都破坏隔离性的毛病,所以这个方案不行。
- 方案二:隔离级别升级为可序列化,小明经过测试后发现不会出现这个问题,但是在可序列化级别下,性能会较低,会出现较多的锁等待,同样的也不考虑。
- 方案三:修改代码逻辑,不要直接删,改成每个数据由业务逻辑去判断哪些是更新,哪些是删除,那些是添加,这个工作量稍大,小明写这个直接删除的逻辑就是为了不做这些复杂的事的,所以这个方案先不考虑。
- 方案四:较少的修改代码逻辑,在删除之前,可以通过快照查询(不加锁),如果查询没有结果,则直接插入,如果有通过主键进行删除,在之前第三节实验2中,通过唯一索引会降级为记录锁,所以不存在间隙锁。
经过考虑小明选择了第四种,马上进行了修复,然后上线观察验证,发现现在已经不会出现这个Bug了,这下小明总算能睡个安稳觉了。
4.4 如何防止死锁
小明通过基础的学习和平常的经验总结了如下几点:
- 以固定的顺序访问表和行。交叉访问更容易造成事务等待回路。
- 尽量避免大事务,占有的资源锁越多,越容易出现死锁。建议拆成小事务。
- 降低隔离级别。如果业务允许(上面4.3也分析了,某些业务并不能允许),将隔离级别调低也是较好的选择,比如将隔离级别从RR调整为RC,可以避免掉很多因为gap锁造成的死锁。
- 为表添加合理的索引。防止没有索引出现表锁,出现的死锁的概率会突增。
最后
由于篇幅有限很多东西并不能介绍全如果感兴趣的同学可以阅读《Mysql技术内幕-InnoDB引擎》第6章 以及 何大师的MySQL 加锁处理分析。作者本人水平有限,如果有什么错误,还请指正。
最后打个广告,如果你觉得这篇文章对你有文章,可以关注我的技术公众号,最近作者收集了很多最新的学习资料视频以及面试资料,关注之后即可领取,你的关注和转发是对我最大的支持,O(∩_∩)O

以上是关于为什么开发人员必须要了解数据库锁?的主要内容,如果未能解决你的问题,请参考以下文章
嵌入式开发人员,这些ROMFLASH硬盘技术知识,必须要了解
讲讲insert on duplicate key update 的死锁坑