spark[源码]-sparkContext详解
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了spark[源码]-sparkContext详解相关的知识,希望对你有一定的参考价值。
spark简述
sparkContext在Spark应用程序的执行过程中起着主导作用,它负责与程序和spark集群进行交互,包括申请集群资源、创建RDD、accumulators及广播变量等。sparkContext与集群资源管理器、work节点交互图如下:
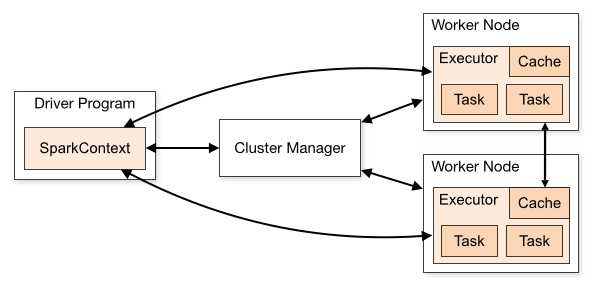
官网对图下面几点说明:
(1)不同的Spark应用程序对应该不同的Executor,这些Executor在整个应用程序执行期间都存在并且Executor中可以采用多线程的方式执行Task。这样做的好处是,各个Spark应用程序的执行是相互隔离的。除Spark应用程序向外部存储系统写数据进行数据交互这种方式外,各Spark应用程序间无法进行数据共享。
(2)Spark对于其使用的集群资源管理器没有感知能力,只要它能对Executor进行申请并通信即可。这意味着不管使用哪种资源管理器,其执行流程都是不变的。这样Spark可以不同的资源管理器进行交互。
(3)Spark应用程序在整个执行过程中要与Executors进行来回通信。
(4)Driver端负责Spark应用程序任务的调度,因此最好Driver应该靠近Worker节点。
1.源码鉴赏-综述
在spark程序运行起来后,程序就会创建sparkContext,解析用户的代码,当遇到action算的时候开始执行程序,但是在执行之前还有很多前提工作要在sparkContext中做的,请记住你要了解了sparkContext,你就了解了spark。
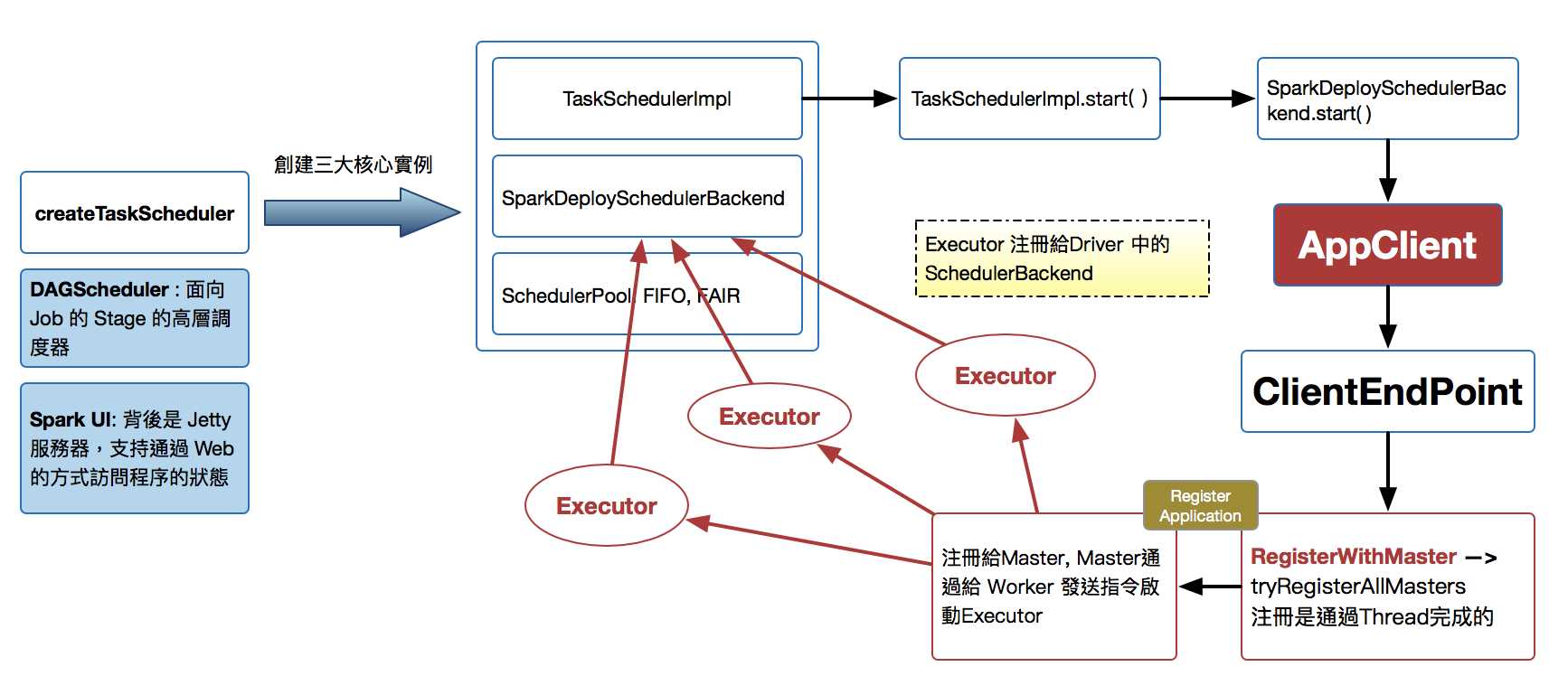
- sparkContext构建的顶级三大核心:DAGScheduler,TaskScheduler,SchedulerBackend.
- DAGScheduler是面向Job的Stage的高层调度器。
- TaskScheduler是一个接口,是低层调度器,根据具体的ClusterManager的不同会有不同的实现。Standalone模式下具体实现的是TaskSchedulerlmpl。
- SchedulerBackend是一个接口,根据具体的ClusterManger的不同会有不同的实现,Standalone模式下具体的实现是SparkDeloySchedulerBackend。
- 从整个程序运行的角度来讲,sparkContext包含四大核心对象:DAGScheduler,TaskScheduler,SchedulerBackend,MapOutputTrackerMaster。
- SparkDeploySchedulerBackend有三大核心功能:
- 负责接收Master接受注册当前程序RegisterWithMaster。
- 接受集群中为当前应用程序而分配的计算资源Executor的注册并管理Executor。
- 负责发送Task到具体的Executor执行。
- SparkDeploySchedulerBackend是被TaskSchedulerlmpl管理的。
sparkContext变量初始化
创建sparkContext的时候会做很多初始化事情,初始化很多变量。
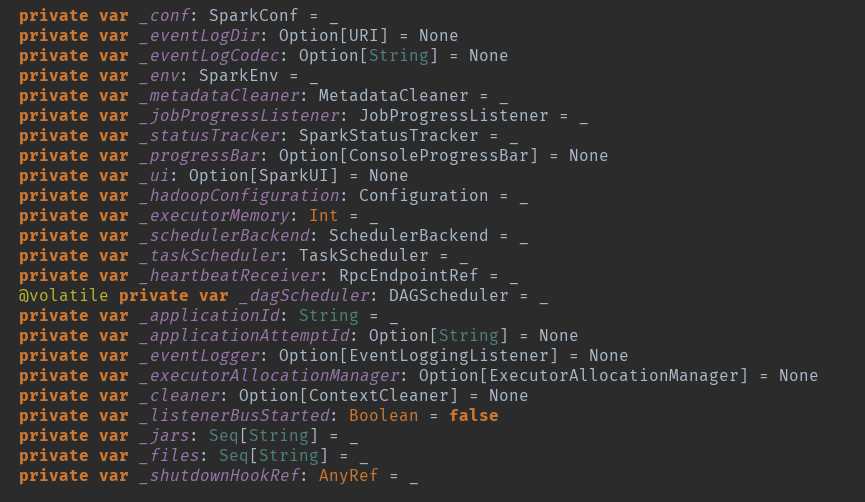
事件监控总线:private[spark] val listenerBus = new LiveListenerBus
第一个重要的初始化出来了:这个地方是创建sparkEnv,就是创建actor,根据判断创建dirver-actor

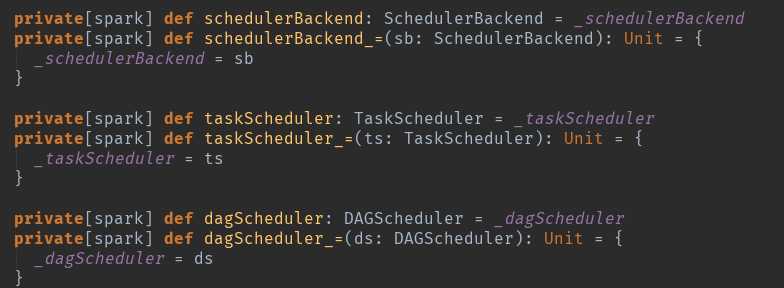
sparkContext的三大核心:这个只是一个定义getter和setter的方法,scala和java是有区别的,可以看看语法。但请时刻技术这三个核心。
从try开始了真正意义上的初始化操作了:396行。
_conf = config.clone():复制一个conf
_conf.validateSettings():检查一些关键配置和是否存在,一些默认配置如果不存在,添加默认设置参数。
_conf.set("spark.executor.id", SparkContext.DRIVER_IDENTIFIER):请注意这个,其实在spark眼里没有driver的概念,都是Executor,只是id标签标记为了driver而已。
sparkEnv初始化:http://www.cnblogs.com/chushiyaoyue/p/7472904.html
下面是三大核心的创建:
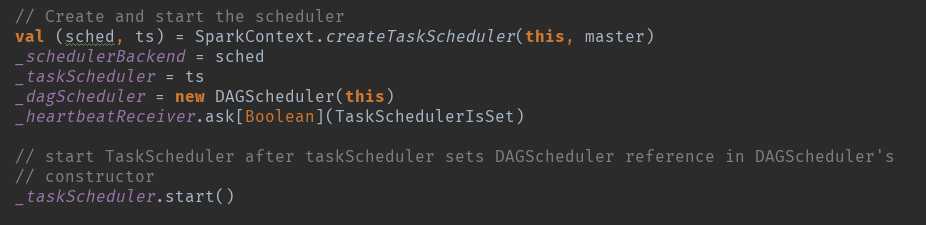
创建createTaskScheduler:根据master的运行情况创建:

这个地方用到了正则匹配来判断master的模式,我们以standalone的模式来讲解:
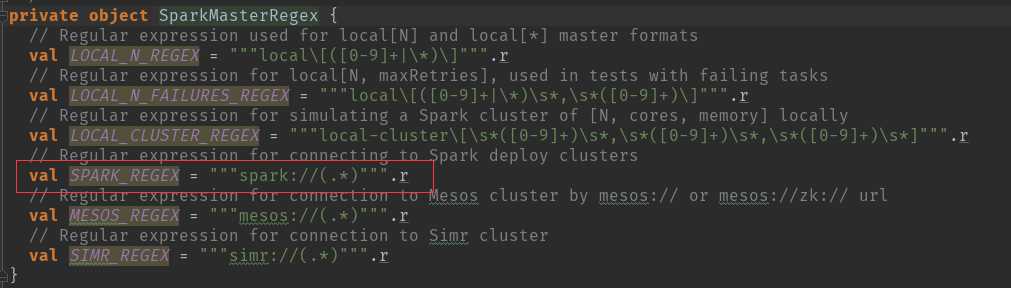
根据模式匹配:TaskSchedulerImpl 创建,注意集群模式默认重试4次,本地模式只尝试1次。

可以自己观察一下其他模式的创建情况,但是会发现TaskSchedulerlmpl基本上是一样。具体的TaskSchedulerImpl的实例创建和initialize()请参看另一篇文章。
http://www.cnblogs.com/chushiyaoyue/p/7475013.html
new TaskSchedulerImpl(sc):主要的是初始化一些变量。
scheduler.initialize(backend):创建资源配置池和资源调度算法,同时通过SchdulableBuilder.addTaskSetmanager:SchdulableBuilder会确定TaskSetManager的调度顺序,然后按照TaskSetManager来确定每个Task具体运行在哪个ExecutorBackend中。
创建_dagScheduler = new DAGScheduler(this)
启动taskScheduler
在这个方法中再调用 backend (SparkDeploySchedulerBackend) 的 start( ) 方法。

这个地方先启动super.start()方法,在这个类CoarseGrainedSchedulerBackend里面。
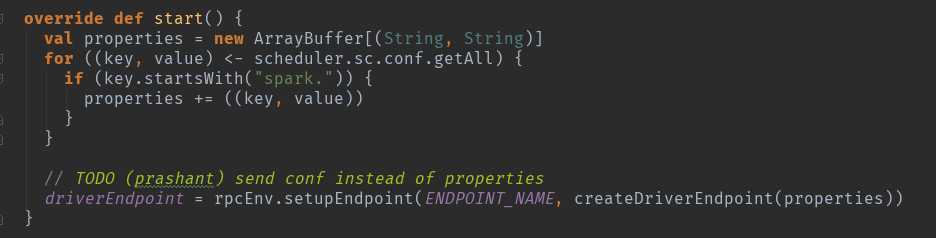
这个方法主要是实例化DriverEndpoint,DriverEndpoint是整个集群内部和应用程序交互的关键。
时刻记住RpcEndpoint的声明周期==constructor -> onStart -> receive* -> onStop
当实例化完成以后调用onStart方法
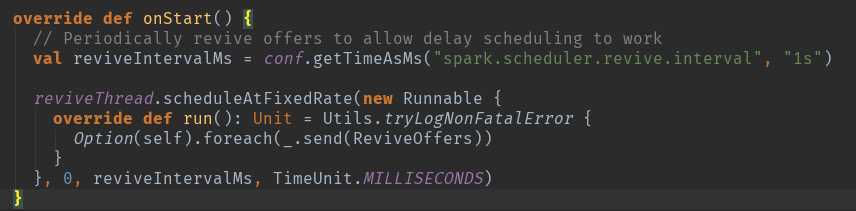
DriverEndpoint在实例化的时候根据Spark的RPC的消息工作机制会调用生命周期方法onStart方法,在该方法执行时会执行Option(self).foreach(_.send(ReviveOffers))来周期性地发ReviveOffers消息给自己,ReviveOffers是个空的object,会触发makeOffers来‘Make fake resource offers on all executors’。
开始创建的时候是发送的空的,这是在等待执行具体的task的时候用的。
注册app到master
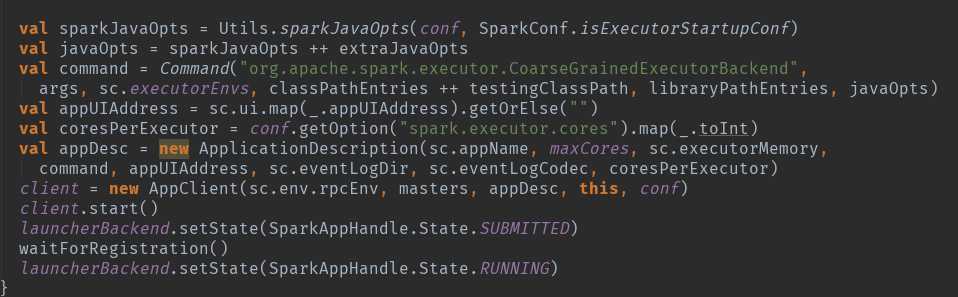
通过SparkDeploySchedulerBackend 注册到Master 的时候会将以上的 command 提交给 Master ,请注意org.apache.spark.executor.CoarseGrainedExecutorBackend,将来会通过这个启动启动执行的executor。
master发指令给worker去启动Executor所有的进程的时候加载的main方法所在的入口类就是coommand中的CoarseGrainedExecutorBackend,当然你可以实现自己的ExecutorBackend,在CoarseGrainnedExecutorBackend中启动Executor(Executor是先注册在实例化),Executor通过线程值并发执行Task。
整体上的内容大概是这样的启动过程,其中存在很多具体的细节,在后续的文章中在详细介绍吧。
以上是关于spark[源码]-sparkContext详解的主要内容,如果未能解决你的问题,请参考以下文章