Kafka中副本机制的设计和原理
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka中副本机制的设计和原理相关的知识,希望对你有一定的参考价值。
在《图解Kafka中的基本概念》中已经对副本进行了介绍。我们先回顾下,Kafka中一个分区可以拥有多个副本,副本可分布于多台机器上。而在多个副本中,只会有一个Leader副本与客户端交互,也就是读写数据。其他则作为Follower副本,负责同步Leader的数据,当Leader宕机时,从Follower选举出新的Leader,从而解决分区单点问题。本文将继续深入了解Kafka中副本机制的设计和原理。
好处
副本机制的使用在计算机的世界里是很常见的,比如mysql、ZooKeeper、CDN等都有使用副本机制。使用副本机制所能带来的好处有以下几种:
- 提供数据冗余,提高可用性;
- 提供扩展性,增加读操作吞吐量;
- 改善数据局部,降低系统延时。
但并不是每个好处都能获得,这还是和具体的设计有关,比如本文的主角Kafka,只具有第一个好处,即提高可用性。这是因为副本中只有Leader可以和客户端交互,进行读写,其他副本是只能同步,不能分担读写压力。为什么这么设计?这和Kafka作为消息系统有关。比如当我们使用生产者成功写入消息后,希望消费者能立马读取到刚生产的消息,这也被称作“Read-Your-Writes”一致性,可理解为写后立即读,要实现这种一致性,如果是只在Leader上读写是很方便实现的。而且也同时保证了“Monotomic Reads”一致性,即单调读一致性,不会出现消息一会能读到,一会读不到的情况。你可能会问,为什么不让多个副本都可以读,来提高读操作吞吐量,同时加入其它机制来保证这两个一致性。笔者的理解是在Kafka中已经引入了分区和消费组机制,来提供扩展性,提高读吞吐量,所以这里没必要再为了提高读吞吐量,而让系统更复杂。
ISR副本
我们已经了解到当Leader宕机时,我们要从Follower中选举出新的Leader,但并不是所有的Follower都有资格参与选举。因为有的Follower的同步情况滞后,如果让他成为Leader将会导致消息丢失。而为了避免这个情况,Kafka引入了ISR(In-Sync Replica)副本的概念,这是一个集合,里面存放的是和Leader保持同步的副本并含有Leader。这是一个动态调整的集合,当副本由同步变为滞后时会从集合中剔除,而当副本由滞后变为同步时又会加入到集合中。
那么如何判断一个副本是同步还是滞后呢?Kafka在0.9版本之前,是根据replica.lag.max.messages参数来判断,其含义是同步副本所能落后的最大消息数,当Follower上的最大偏移量落后Leader大于replica.lag.max.messages时,就认为该副本是不同步的了,会从ISR中移除。如果ISR的值设置得过小,会导致Follower经常被踢出ISR,而如果设置过大,则当Leader宕机时,会造成较多消息的丢失。在实际使用时,很难给出一个合理值,这是因为当生产者为了提高吞吐量而调大batch.size时,会发送更多的消息到Leader上,这时候如果不增大replica.lag.max.messages,则会有Follower频繁被踢出ISR的现象,而当Follower发生Fetch请求同步后,又被加入到ISR中,ISR将频繁变动。鉴于该参数难以设定,Kafka在0.9版本引入了一个新的参数replica.lag.time.max.ms,默认10s,含义是当Follower超过10s没发送Fetch请求同步Leader时,就会认为不同步而被踢出ISR。从时间维度来考量,能够很好地避免生产者发送大量消息到Leader副本导致分区ISR频繁收缩和扩张的问题。
Unclear Leader选举
当ISR集合为空时,即没有同步副本(Leader也挂了),无法选出下一个Leader,Kafka集群将会失效。而为了提高可用性,Kafka提供了unclean.leader.election.enable参数,当设置为true且ISR集合为空时,会进行Unclear Leader选举,允许在非同步副本中选出新的Leader,从而提高Kafka集群的可用性,但这样会造成消息丢失。在允许消息丢失的场景中,是可以开启此参数来提高可用性的。而其他情况,则不建议开启,而是通过其他手段来提高可用性。
LEO和HW
下面我们一起了解副本同步的原理。副本的本质其实是一个消息日志,为了让副本正常同步,需要通过一些变量记录副本的状态,如下图所示: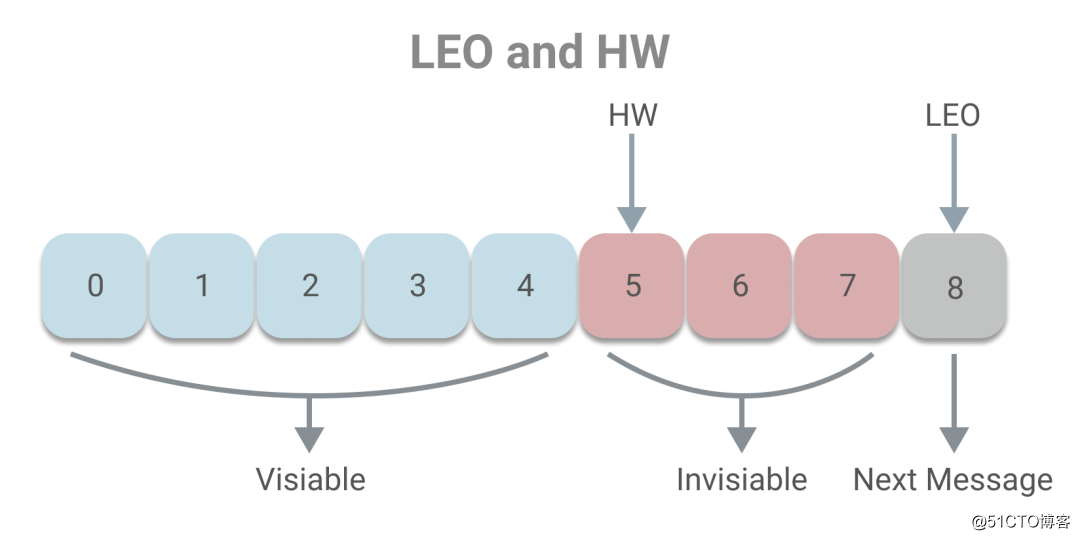
其中LEO(Last End Offset)记录了日志的下一条消息偏移量,即当前最新消息的偏移量加一。而HW(High Watermark)界定了消费者可见的消息,消费者可以消费小于HW的消息,而大于等于HW的消息将无法消费。HW和LEO的关系是HW一定小于LEO。下面介绍下HW的概念,其可翻译为高水位或高水印,这一概念通常用于在流式处理领域(如Flink、Spark等),流式系统将保证在HW为t时刻时,创建时间小于等于t时刻的所有事件都已经到达或可被观测到。而在Kafka中,HW的概念和时间无关,而是和偏移量有关,主要目的是为了保证一致性。试想如果一个消息到达了Leader,而Follower副本还未来得及同步,但该消息能已被消费者消费了,这时候Leader宕机,Follower副本中选出新的Leader,消息将丢失,出现不一致的现象。所以Kafka引入HW的概念,当消息被同步副本同步完成时,才让消息可被消费。
上述即是LEO和HW的基本概念,下面我们看下具体是如何工作的。
在每个副本中都存有LEO和HW,而Leader副本中除了存有自身的LEO和HW,还存储了其他Follower副本的LEO和HW值,为了区分我们把Leader上存储的Follower副本的LEO和HW值叫做远程副本的LEO和HW值,如下图所示: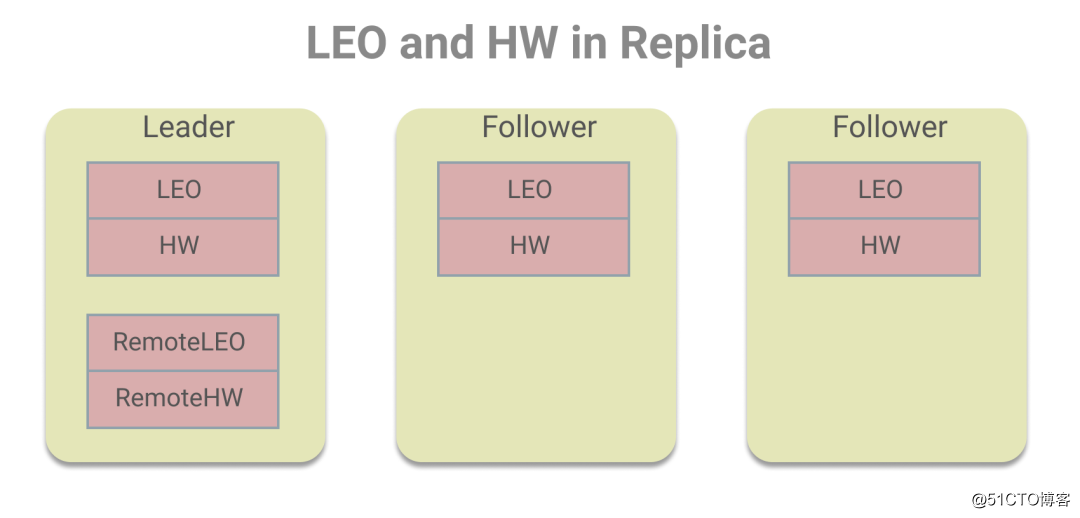
之所以这么设计,是为了HW的更新,Leader需保证HW是ISR副本集合中LEO的最小值。关于具体的更新,我们分为Follower副本和Leader副本来看。
Follower副本更新LEO和HW的时机只有向Leader拉取了消息之后,会用当前的偏移量加1来更新LEO,并且用Leader的HW值和当前LEO的最小值来更新HW:
CurrentOffset + 1 -> LEO
min(LEO, LeaderHW) -> HWLEO的更新,很好理解。那为什么HW要取LEO和LeaderHW的最小值,为什么不直接取LeaderHW,LeaderHW不是一定大于LEO吗?我们在前文简单的提到了LeaderHW是根据同步副本来决定,所以LeaderHW一定小于所有同步副本的LEO,而并不一定小于非同步副本的LEO,所以如果一个非同步副本在拉取消息,那LEO是会小于LeaderHW的,则应用当前LEO值来更新HW。
说完了Follower副本上LEO和HW的更新,下面看Leader副本。
正常情况下Leader副本的更新时机有两个:一、收到生产者的消息;二、被Follower拉取消息。
当收到生产者消息时,会用当前偏移量加1来更新LEO,然后取LEO和远程ISR副本中LEO的最小值更新HW。
CurrentOffset + 1 -> LEO
min(LEO, RemoteIsrLEO) -> HW而当Follower拉取消息时,会更新Leader上存储的Follower副本LEO,然后判断是否需要更新HW,更新的方式和上述相同。
FollowerLEO -> RemoteLEO
min(LEO, RemoteIsrLEO) -> HW除了这两种正常情况,而当发生故障时,例如Leader宕机,Follower被选为新的Leader,会尝试更新HW。还有副本被踢出ISR时,也会尝试更新HW。
下面我们看下更新LEO和HW的示例,假设分区中有两个副本,min.insync.replica=1。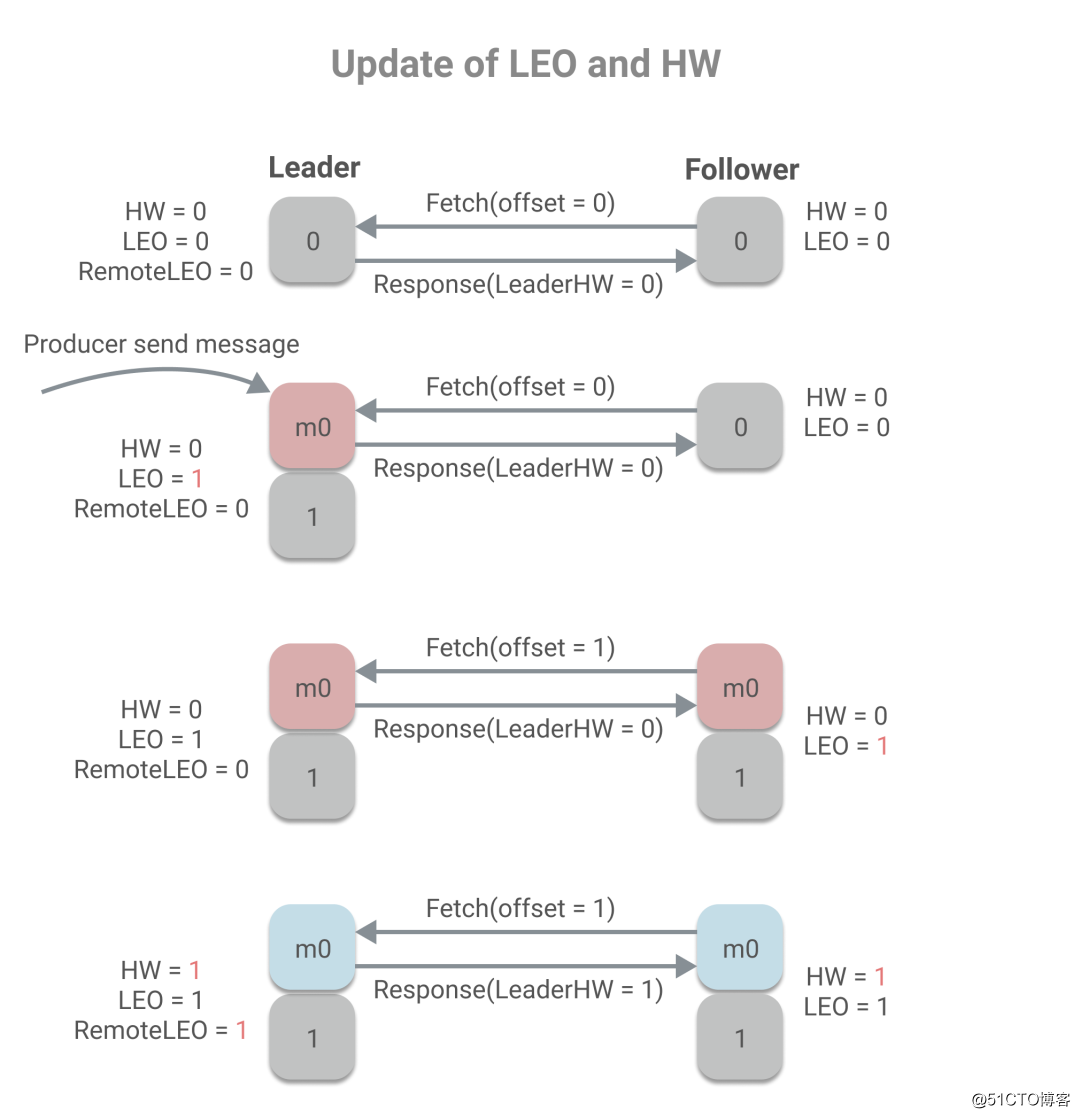
从上述过程中,我们可以看到remoteLEO、LeaderHW和FollowerHW的更新发生于Follower更新LEO后的第二轮Fetch请求,而这也意味着,更新需要额外一次Fetch请求。而这也将导致在Leader切换时,会存在数据丢失和数据不一致的问题。下面是数据丢失的示例: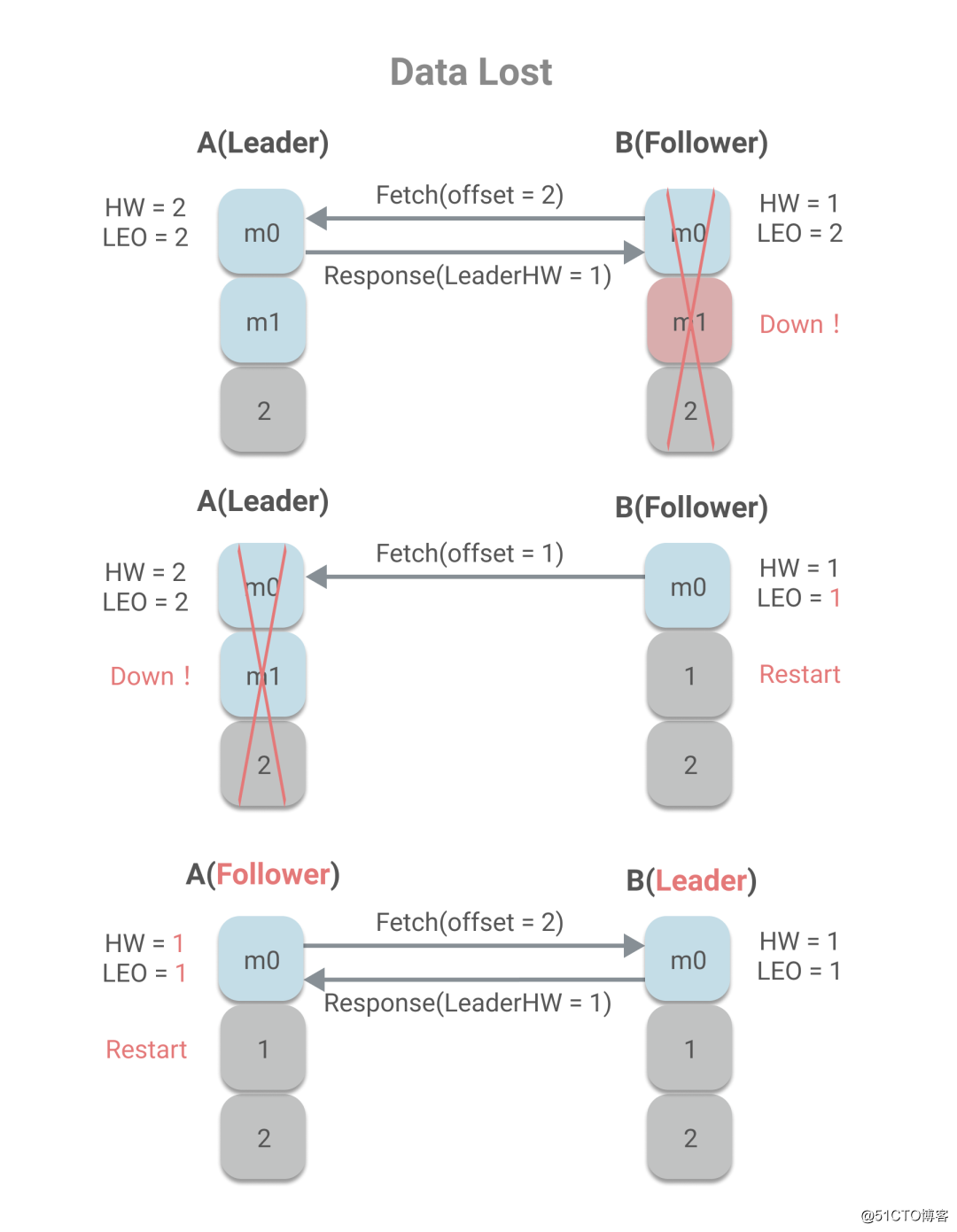
当B作为Follower已经Fetch了最新的消息,但是在发送第二轮Fetch时,未来得及处理响应,宕机了。当重启时,会根据HW更新LEO,将发生日志截断,消息m1被丢弃。这时再发送Fetch请求给A,A宕机了,则B未能同步到消息m1,同时B被选为Leader,而当A重启时,作为Follower同步B的消息时,会根据A的HW值更新HW和LEO,因此由2变成了1,也将发生日志截断,而已发送成功的消息m1将永久丢失。
数据不一致的情况如下: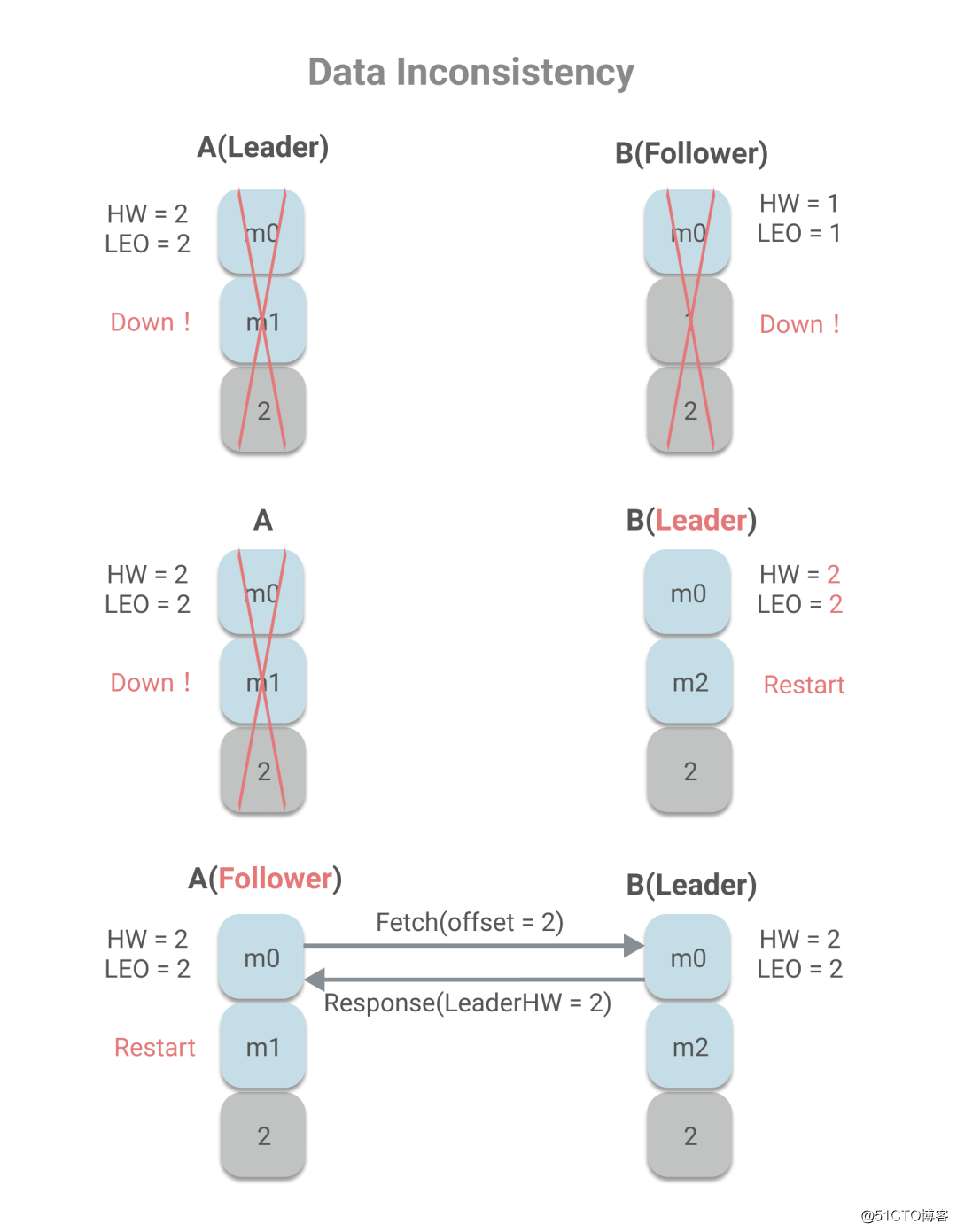
A作为Leader,A已写入m0、m1两条消息,且HW为2,而B作为Follower,只有m0消息,且HW为1。若A、B同时宕机,且B重启时,A还未恢复,则B被选为Leader。
集群处于上述这种状态有两种情况可能导致,一、宕机前,B不在ISR中,因此A未待B同步,即更新了HW,且unclear leader为true,允许B成为Leader;二、宕机前,B同步了消息m1,且发送了第二轮Fetch请求,Leader更新HW,但B未将消息m1落地到磁盘,宕机了,当再重启时,消息m1丢失,只剩m0。在B重启作为Leader之后,收到消息m2。A宕机重启后向成为Leader的B发送Fetch请求,发现自己的HW和B的HW一致,都是2,因此不会进行消息截断,而这也造成了数据不一致。
Leader Epoch
为了解决HW可能造成的数据丢失和数据不一致问题,Kafka引入了Leader Epoch机制,在每个副本日志目录下都有一个leader-epoch-checkpoint文件,用于保存Leader Epoch信息,其内容示例如下:
0 0
1 300
2 500上面每一行为一个Leader Epoch,分为两部分,前者Epoch,表示Leader版本号,是一个单调递增的正整数,每当Leader变更时,都会加1,后者StartOffset,为每一代Leader写入的第一条消息的位移。例如第0代Leader写的第一条消息位移为0,而第1代Leader写的第一条消息位移为300,也意味着第0代Leader在写了0-299号消息后挂了,重新选出了新的Leader。下面我们看下Leader Epoch如何工作:
- 当副本成为Leader时:
当收到生产者发来的第一条消息时,会将新的epoch和当前LEO添加到leader-epoch-checkpoint文件中。
- 当副本成为Follower时:
a.向Leader发送LeaderEpochRequest请求,请求内容中含有Follower当前本地的最新Epoch;
b.Leader将返回给Follower的响应中含有一个LastOffset,其取值规则为:
i.若FollowerLastEpoch = LeaderLastEpoch,则取Leader LEO;
ii.否则,取大于FollowerLastEpoch的第一个Leader Epoch中的StartOffset。
c.Follower在拿到LastOffset后,若LastOffset < LEO,将截断日志;
d.Follower开始正常工作,发送Fetch请求;
我们再回顾看下数据丢失和数据不一致的场景,在应用了LeaderEpoch后发生什么改变: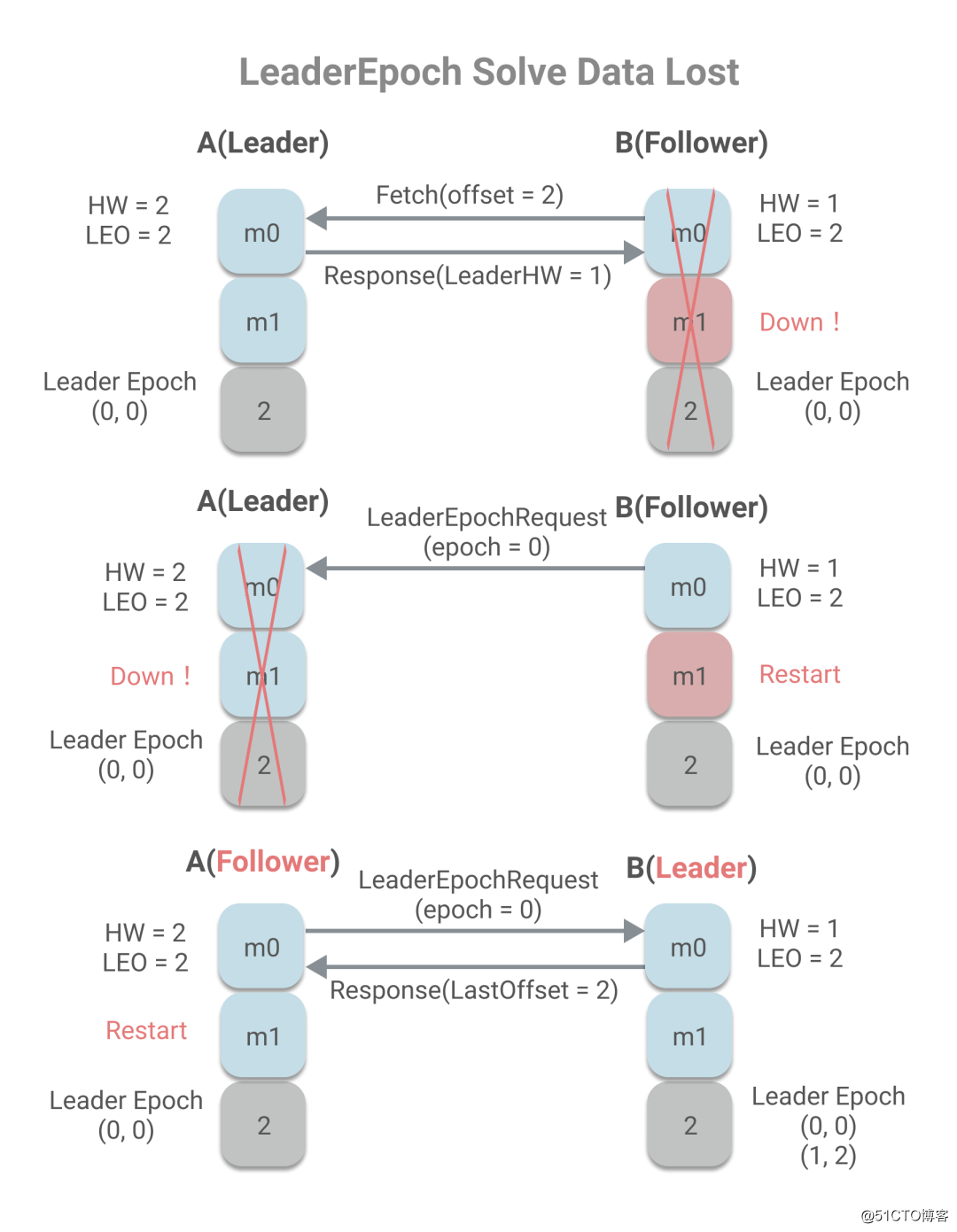
当B作为Follower已经Fetch了最新的消息,但是发送第二轮Fetch时,未来得及处理响应,宕机了。当重启时,会向A发送LeaderEpochRequest请求。如果A没宕机,由于 FollowerLastEpoch = LeaderLastEpoch,所以将LeaderLEO,即2作为LastOffset给A,又因为LastOffset=LEO,所以不会截断日志。这种情况比较简单,而图中所画的情况是A宕机的情况,没返回LeaderEpochRequest的响应的情况。这时候B会被选作Leader,将当前LEO和新的Epoch写进leader-epoch-checkpoint文件中。当A作为Follower重启后,发送LeaderEpochRequest请求,包含最新的epoch值0,当B收到请求后,由于FollowerLastEpoch < LeaderLastEpoch,所以会取大于FollowerLastEpoch的第一个Leader Epoch中的StartOffset,即2。当A收到响应时,由于LEO = LastOffset,所以不会发生日志截断,也就不会丢失数据。
下面是数据不一致情况: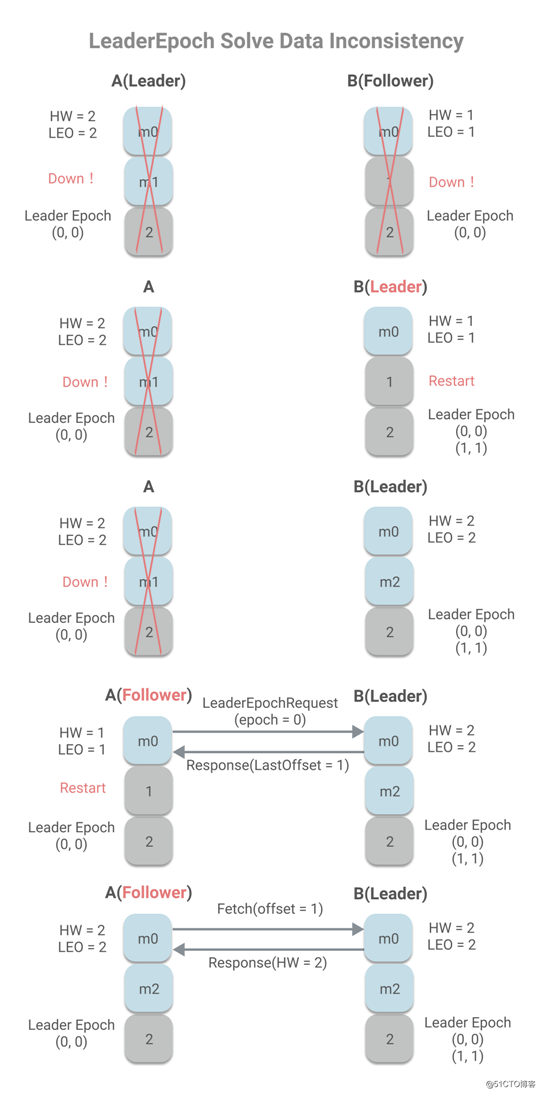
A作为Leader,A已写入m0、m1两条消息,且HW为2,而B作为Follower,只有消息m0,且HW为1,A、B同时宕机。B重启,被选为Leader,将写入新的LeaderEpoch(1, 1)。B开始工作,收到消息m2时。这是A重启,将作为Follower将发送LeaderEpochRequert(FollowerLastEpoch=0),B返回大于FollowerLastEpoch的第一个LeaderEpoch的StartOffset,即1,小于当前LEO值,所以将发生日志截断,并发送Fetch请求,同步消息m2,避免了消息不一致问题。
你可能会问,m2消息那岂不是丢失了?是的,m2消息丢失了,但这种情况的发送的根本原因在于min.insync.replicas的值设置为1,即没有任何其他副本同步的情况下,就认为m2消息为已提交状态。LeaderEpoch不能解决min.insync.replicas为1带来的数据丢失问题,但是可以解决其所带来的数据不一致问题。而我们之前所说能解决的数据丢失问题,是指消息已经成功同步到Follower上,但因HW未及时更新引起的数据丢失问题。
以上是关于Kafka中副本机制的设计和原理的主要内容,如果未能解决你的问题,请参考以下文章
kakfa从入门到放弃: 分区和副本机制高级与低级API kafka-eagle原理数据清理限速