使用pandas库对csv文件进行筛选和保存
Posted cyx-b
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用pandas库对csv文件进行筛选和保存相关的知识,希望对你有一定的参考价值。
这个操作现在看来真没啥难的,但是我找相关的资料真的找了好久。
多数大佬都是直接pandas官网甩我脸上,然后举一个入门级的例子。
https://pandas.pydata.org/docs/reference/index.html
首先导入pandas库
import pandas as pd
然后使用read_csv来打开指定的csv文件
df = pd.read_csv(‘./IP2LOCATION.csv‘,encoding= ‘utf-8‘)
这个函数里面需要写入csv文件的路径,如果是把csv文件保存到了python的工程文件夹下,则只需要./文件名即可,然后encoding=‘utf-8‘是使用utf-8方式编码,有时候需要换成gbk。
虽然我们读取的是csv文件,但其实由于我们使用的是pandas库,所以我们实际获得的是一个DataFrame的数据结构。
可以使用print(type(df))进行检验
print(type(df))

DataFrame 是表格型的数据结构。因此,我们可以将其当做表格。DataFrame 是以表格类似展示,而且还包含行标签、列标签。
我们可以添加一个列标签,使用方法为pandas.DataFrame.columns
在我们的例子中DataFrame类型的变量为df,因此使用方法为df.columns,我们添加的列标签为a、b、c、d、e、f
df.columns = [‘a‘,‘b‘,‘c‘,‘d‘,‘e‘,‘f‘]
然后,我们想把某一列中等于特定值的那些行提取出来
可以将读出来的内容当做一个列表,然后这个列表的元素是表中的每一行,然后这每一行也是一个列表,也就是列表中的列表。
比如,我想将表中第5列中值为Andhra Pradesh的行提取出来,并且由于我们之前定义了第五列的列标签为e
因此代码为:
data = df[df[‘e‘] == ‘Andhra Pradesh‘]
最后我们可以通过pandas中的to_csv,来将筛选出来的数据保存到新的csv文件中。
data.to_csv(‘my_IP2LOCATION.csv‘)
用法为表名. to_csv(‘所要保存地方的路径/表名.csv‘)
最后总结一下我们的代码
import pandas as pd df = pd.read_csv(‘./IP2LOCATION.csv‘,encoding= ‘utf-8‘) # print(type(df)) df.columns = [‘a‘,‘b‘,‘c‘,‘d‘,‘e‘,‘f‘] data = df[df[‘e‘] == ‘Andhra Pradesh‘] data.to_csv(‘my_IP2LOCATION.csv‘)
IP2LOCATION.csv内容如下:
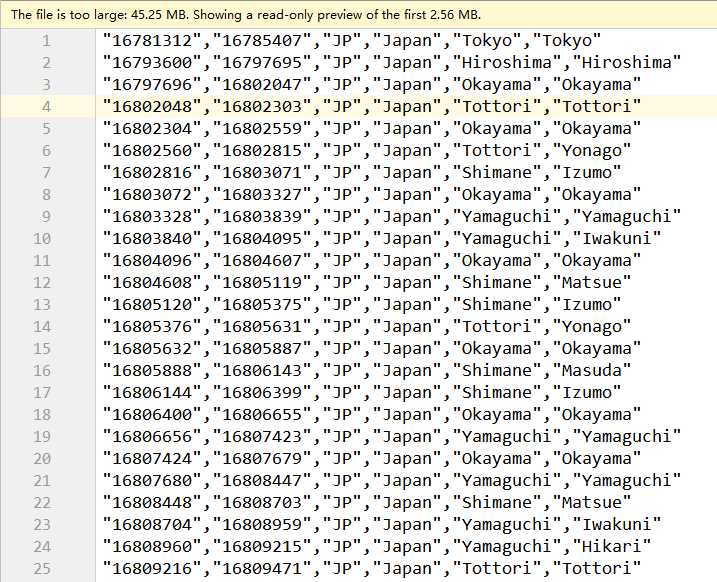
总共有759727行
然后经过我们的筛选后的my_IP2LOCATION.csv
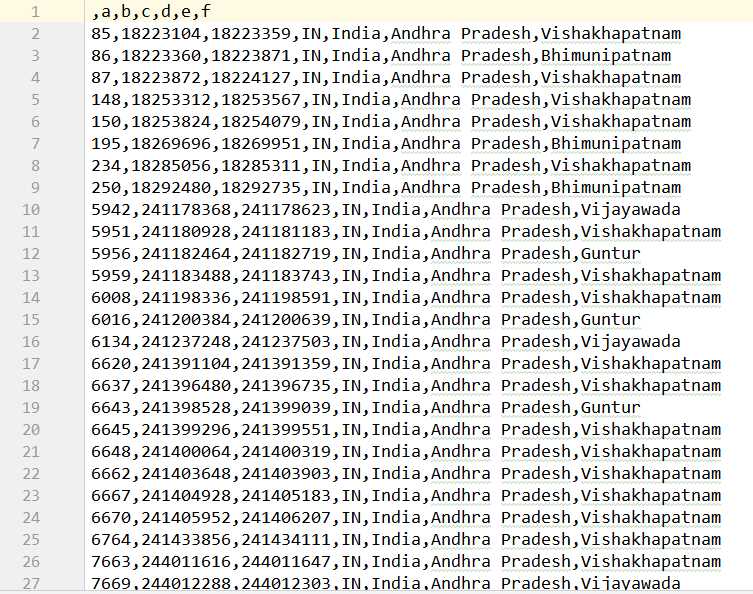
只有3461行
PS:可以使用print(len(df.values))来查看行数
以上是关于使用pandas库对csv文件进行筛选和保存的主要内容,如果未能解决你的问题,请参考以下文章