Pytorch使用分布式训练,单机多卡
Posted yh-blog
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Pytorch使用分布式训练,单机多卡相关的知识,希望对你有一定的参考价值。
pytorch的并行分为模型并行、数据并行
左侧模型并行:是网络太大,一张卡存不了,那么拆分,然后进行模型并行训练。
右侧数据并行:多个显卡同时采用数据训练网络的副本。
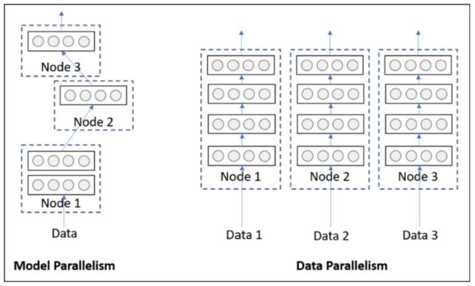
一、模型并行
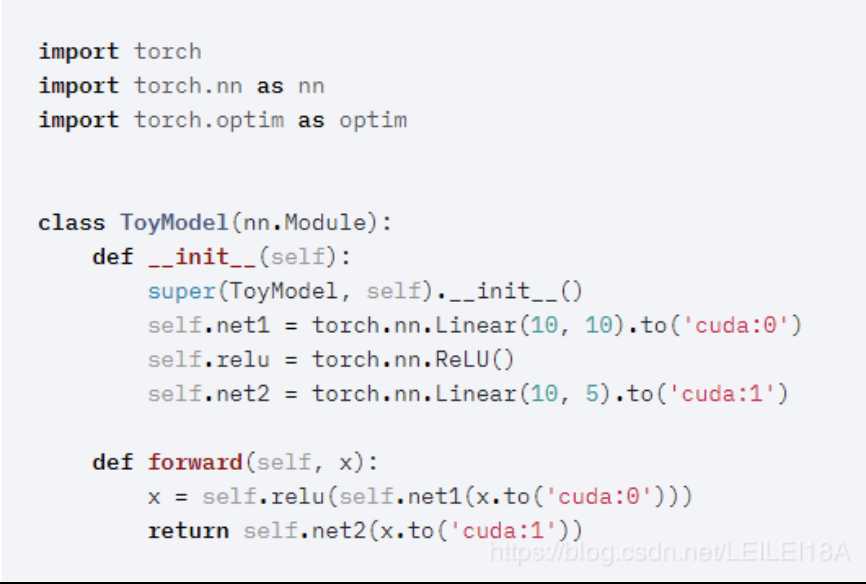
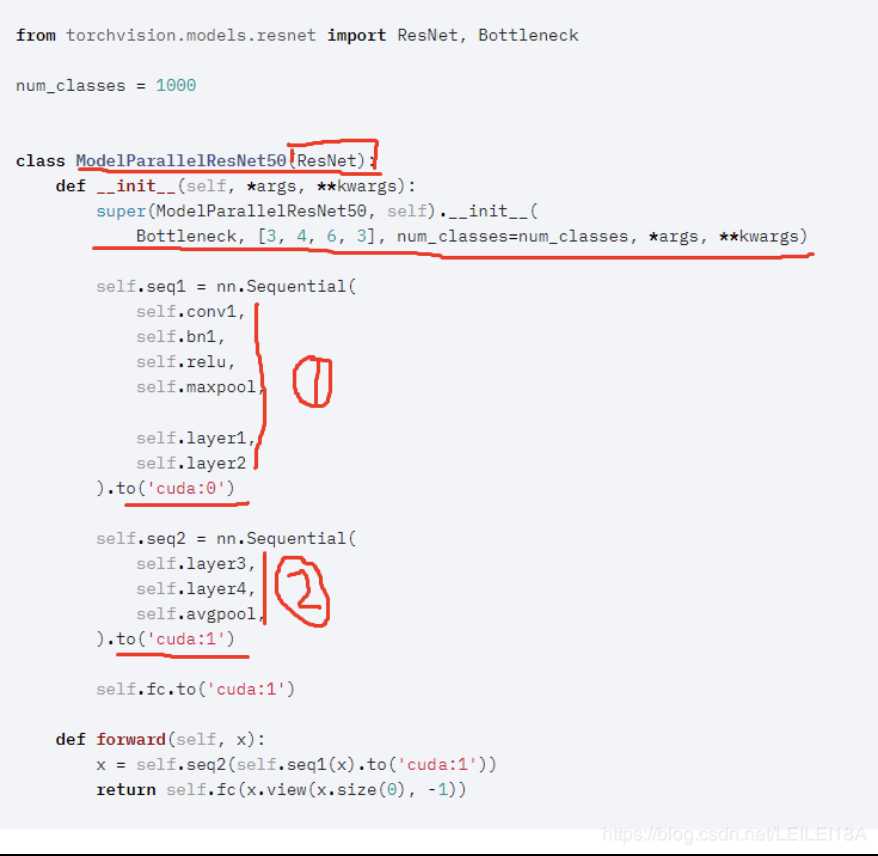
二、数据并行
数据并行的操作要求我们将数据划5分成多份,然后发送给多个 GPU 进行并行的计算。
注意:多卡训练要考虑通信开销的,是个trade off的过程,不见得四块卡一定比两块卡快多少,可能是训练到四块卡的时候通信开销已经占了大头
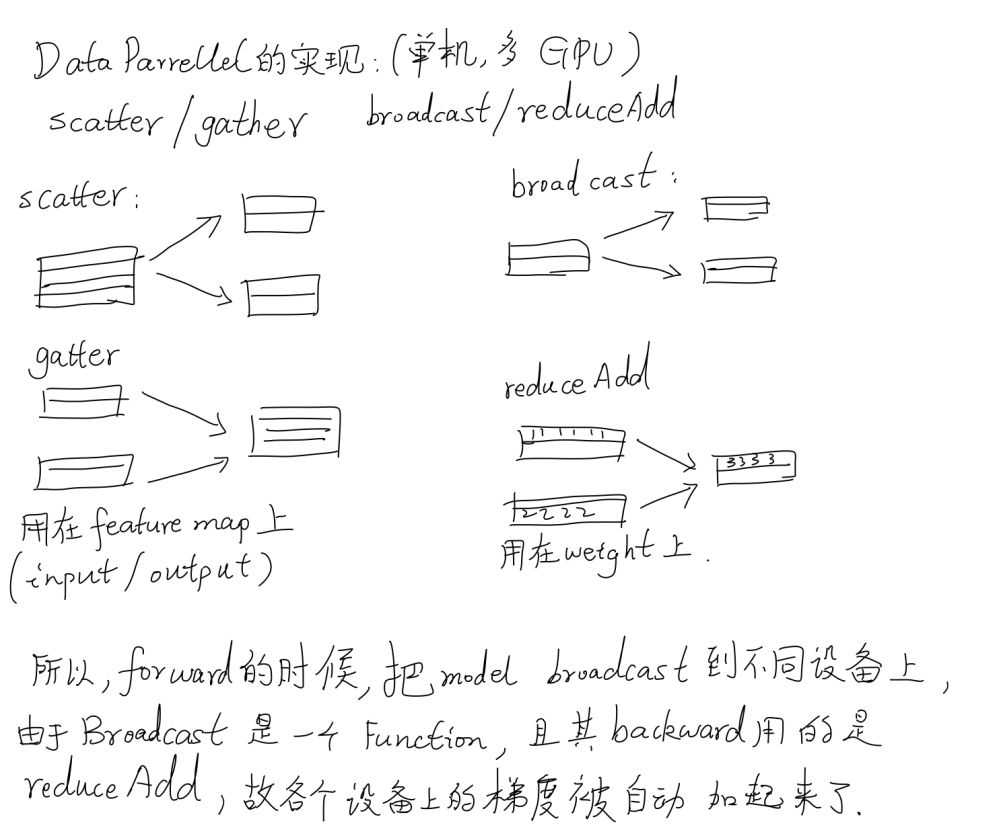
下面是一个简单的示例。要实现数据并行,第一个方法是采用 nn.parallel 中的几个函数,分别实现的功能如下所示:
-
复制(Replicate):将模型拷贝到多个 GPU 上;
-
分发(Scatter):将输入数据根据其第一个维度(通常就是 batch 大小)划分多份,并传送到多个 GPU 上;
-
收集(Gather):从多个 GPU 上传送回来的数据,再次连接回一起;
-
并行的应用(parallel_apply):将第三步得到的分布式的输入数据应用到第一步中拷贝的多个模型上。
- 实现代码如下
# Replicate module to devices in device_ids replicas = nn.parallel.replicate(module, device_ids) # Distribute input to devices in device_ids inputs = nn.parallel.scatter(input, device_ids) # Apply the models to corresponding inputs outputs = nn.parallel.parallel_apply(replicas, inputs) # Gather result from all devices to output_device result = nn.parallel.gather(outputs, output_device)
①nn.parallel.data_parallel(module, inputs, device_ids=None, output_device=None, dim=0, module_kwargs=None)
②class torch.nn.DataParallel(module, device_ids=None, output_device=None, dim=0)
可见二者的参数十分相似,通过device_ids参数可以指定在哪些GPU上进行优化,output_device指定输出到哪个GPU上。唯一的不同就在于前者直接利用多GPU并行计算得出结果,而后者则返回一个新的module,能够自动在多GPU上进行并行加速。
# method 1 new_net= nn.DataParallel(net, device_ids=[0, 1]) output= new_net(input) # method 2 output= nn.parallel.data_parallel(new_net, input, device_ids=[0, 1])
数据并行torch.nn.DataParallel
PyTorch 中实现数据并行的操作可以通过使用 torch.nn.DataParallel。
一、并行处理机制
DataParallel,是将输入一个 batch 的数据均分成多份,分别送到对应的 GPU 进行计算,各 个 GPU 得到的梯度累加。与 Module 相关的所有数据也都会以浅复制的方式复制多份。每个 GPU 将针对各自的输入数据独立进行 forward 计算,在 backward 时,每个卡上的梯度会汇总到原始的 module 上,再用反向传播更新单个 GPU 上的模型参数,再将更新后的模型参数复制到剩余指定的 GPU 中,以此来实现并行。
DataParallel会将定义的网络模型参数默认放在GPU 0上,所以dataparallel实质是可以看做把训练参数从GPU拷贝到其他的GPU同时训练,这样会导致内存和GPU使用率出现很严重的负载不均衡现象,即GPU 0的使用内存和使用率会大大超出其他显卡的使用内存,因为在这里GPU0作为master来进行梯度的汇总和模型的更新,再将计算任务下发给其他GPU,所以他的内存和使用率会比其他的高。
(图源知乎)
二、使用代码
注意我这里的代码时一个文本分类的,模型叫TextCNN
1.单gpu(用做对比)
import os os.environ["CUDA_VISIBLE_DEVICES"] = "0" #在训练函数和测试函数中,有两个地方要判断是否用cuda,将模型和数据搬到gpu上去 model = TextCNN(args) if args.cuda: model.cuda() 。。。 for batch_idx, (data, target) in enumerate(train_loader): if args.cuda: data, target = data.cuda(), target.cuda()
2.多gpu,DataParallel使用
#device_ids = [0,1,2,3] 如果不设定好要使用的device_ids的话, 程序会自动找到这个机器上面可以用的所有的显卡用于训练。 如果想要限制使用的显卡数,怎么办呢? 在代码最前面使用: os.environ[‘CUDA_VISIBLE_DEVICES‘] == ‘0,5‘ 或者 CUDA_VISIBLE_DEVICES=1,2,3 python # 限制代码能看到的GPU个数,这里表示指定只使用实际的0号和5号GPU # 注意:这里的赋值必须是字符串,list会报错 ————————————————下面是重点 if args.cuda: model = model.cuda() #这里将模型复制到gpu if len(device_ids)>1: model = nn.DataParallel(model) #when train and test data = data.cuda(non_blocking=True) target = target.cuda(non_blocking=True)
稍微完整一点:
# 这里要 model.cuda() model = nn.DataParallel(model.cuda(), device_ids=gpus, output_device=gpus[0]) for epoch in range(100): for batch_idx, (data, target) in enumerate(train_loader): # 这里要 images/target.cuda() images = images.cuda(non_blocking=True) target = target.cuda(non_blocking=True) ... output = model(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step()
3.cuda()函数解释
.cuda()函数返回一个存储在CUDA内存中的复制,其中device可以指定cuda设备。 但如果此storage对象早已在CUDA内存中存储,并且其所在的设备编号与cuda()函数传入的device参数一致,则不会发生复制操作,返回原对象。
cuda()函数的参数信息:
-
device (int) – 指定的GPU设备id. 默认为当前设备,即
torch.cuda.current_device()的返回值。 -
non_blocking (bool) – 如果此参数被设置为True, 并且此对象的资源存储在固定内存上(pinned memory),那么此cuda()函数产生的复制将与host端的原storage对象保持同步。否则此参数不起作用。
分布式数据并行 torch.nn.parallel.DistributedDataParallel
一、并行处理机制
DistributedDataParallel,支持 all-reduce,broadcast,send 和 receive 等等。通过 MPI 实现 CPU 通信,通过 NCCL 实现 GPU 通信。可以用于单机多卡也可用于多机多卡, 官方也曾经提到用 DistributedDataParallel 解决 DataParallel 速度慢,GPU 负载不均衡的问题。
效果比DataParallel好太多!!!torch.distributed相对于torch.nn.DataParalle 是一个底层的API,所以我们要修改我们的代码,使其能够独立的在机器(节点)中运行。
相比DataParallel优势如下:
在每次迭代中,每个进程具有自己的 optimizer ,并独立完成所有的优化步骤,进程内与一般的训练无异。
在各进程梯度计算完成之后,各进程需要将梯度进行汇总平均,然后再由 rank=0 的进程,将其 broadcast 到所有进程。之后,各进程用该梯度来独立的更新参数。
而 DataParallel是梯度汇总到gpu0,反向传播更新参数,再广播参数给其他的gpu
由于各进程中的模型,初始参数一致 (初始时刻进行一次 broadcast),而每次用于更新参数的梯度也一致,因此,各进程的模型参数始终保持一致。
而在 DataParallel 中,全程维护一个 optimizer,对各 GPU 上梯度进行求和,而在主 GPU 进行参数更新,之后再将模型参数 broadcast 到其他 GPU。
相较于 DataParallel,torch.distributed 传输的数据量更少,因此速度更快,效率更高。
2.每个进程包含独立的解释器和 GIL。
一般使用的Python解释器CPython:是用C语言实现Pyhon,是目前应用最广泛的解释器。全局锁使Python在多线程效能上表现不佳,全局解释器锁(Global Interpreter Lock)是Python用于同步线程的工具,使得任何时刻仅有一个线程在执行。
由于每个进程拥有独立的解释器和 GIL,消除了来自单个 Python 进程中的多个执行线程,模型副本或 GPU 的额外解释器开销和 GIL-thrashing ,因此可以减少解释器和 GIL 使用冲突。这对于严重依赖 Python runtime 的 models 而言,比如说包含 RNN 层或大量小组件的 models 而言,这尤为重要。
分布式几个概念:
-
即进程组。默认情况下,只有一个组,一个 job 即为一个组,也即一个 world。
当需要进行更加精细的通信时,可以通过 new_group 接口,使用 word 的子集,创建新组,用于集体通信等。
-
world size :
表示全局进程个数。
-
rank:
表示进程序号,用于进程间通讯,表征进程优先级。rank = 0 的主机为 master 节点。
-
local_rank:
进程内,GPU 编号,非显式参数,由 torch.distributed.launch 内部指定。比方说, rank = 3,local_rank = 0 表示第 3 个进程内的第 1 块 GPU。
二、使用流程
Pytorch 中分布式的基本使用流程如下:
-
在使用
distributed包的任何其他函数之前,需要使用init_process_group初始化进程组,同时初始化distributed包。 -
如果需要进行小组内集体通信,用
new_group创建子分组 -
创建分布式并行模型
DDP(model, device_ids=device_ids) -
为数据集创建
Sampler -
使用启动工具
torch.distributed.launch在每个主机上执行一次脚本,开始训练 -
使用
destory_process_group()销毁进程组
三、使用代码
1. 添加参数 --local_rank #每个进程分配一个 local_rank 参数,表示当前进程在当前主机上的编号。例如:rank=2, local_rank=0 表示第 3 个节点上的第 1 个进程。 # 这个参数是torch.distributed.launch传递过来的,我们设置位置参数来接受,local_rank代表当前程序进程使用的GPU标号 parser = argparse.ArgumentParser() parser.add_argument(‘--local_rank‘, default=-1, type=int, help=‘node rank for distributed training‘) args = parser.parse_args() print(args.local_rank)) 2.初始化使用nccl后端 dist.init_process_group(backend=‘nccl‘) # When using a single GPU per process and per # DistributedDataParallel, we need to divide the batch size # ourselves based on the total number of GPUs we have device_ids=[1,3] ngpus_per_node=len(device_ids) args.batch_size = int(args.batch_size / ngpus_per_node) #ps 检查nccl是否可用 #torch.distributed.is_nccl_available () 3.使用DistributedSampler #别忘了设置pin_memory=true #使用 DistributedSampler 对数据集进行划分。它能帮助我们将每个 batch 划分成几个 partition,在当前进程中只需要获取和 rank 对应的那个 partition 进行训练 train_dataset = MyDataset(train_filelist, train_labellist, args.sentence_max_size, embedding, word2id) train_sampler = t.utils.data.distributed.DistributedSampler(train_dataset) train_dataloader = DataLoader(train_dataset, pin_memory=true, shuffle=(train_sampler is None), batch_size=args.batch_size, num_workers=args.workers, sampler=train_sampler ) #DataLoader:num_workers这个参数决定了有几个进程来处理data loading。0意味着所有的数据都会被load进主进程 #注意 testset不用sampler 4.分布式训练 #使用 DistributedDataParallel 包装模型,它能帮助我们为不同 GPU 上求得的梯度进行 all reduce(即汇总不同 GPU 计算所得的梯度,并同步计算结果)。all reduce 后不同 GPU 中模型的梯度均为 all reduce 之前各 GPU 梯度的均值: net = textCNN(args,vectors=t.FloatTensor(wvmodel.vectors)) if args.cuda: # net.cuda(device_ids[0]) net.cuda() if len(device_ids)>1: net=torch.nn.parallel.DistributedDataParallel(net,find_unused_parameters=True) 5.最后,把数据和模型加载到当前进程使用的 GPU 中,正常进行正反向传播: for batch_idx, (data, target) in enumerate(train_loader): if args.cuda: data, target = data.cuda(), target.cuda() output = net(images) loss = criterion(output, target) ... optimizer.zero_grad() loss.backward() optimizer.step() 6.在使用时,命令行调用 torch.distributed.launch 启动器启动: #pytorch 为我们提供了 torch.distributed.launch 启动器,用于在命令行分布式地执行 python 文件。 #--nproc_per_node参数指定为当前主机创建的进程数。一般设定为=NUM_GPUS_YOU_HAVE当前主机的 GPU 数量,每个进程独立执行训练脚本。 #这里是单机多卡,所以node=1,就是一台主机,一台主机上--nproc_per_node个进程 CUDA_VISIBLE_DEVICES=0,1,2,3 python -m torch.distributed.launch --nproc_per_node=4 main.py
四、一些解释
1、启动辅助工具 Launch utility
启动实用程序torch.distributed.launch,此帮助程序可用于为每个节点启动多个进程以进行分布式训练,它在每个训练节点上产生多个分布式训练进程。
这个工具可以用作CPU或者GPU,如果被用于GPU,每个GPU产生一个进程Process。该工具既可以用来做单节点多GPU训练,也可用于多节点多GPU训练。如果是单节点多GPU,将会在单个GPU上运行一个分布式进程,据称可以非常好地改进单节点训练性能。如果用于多节点分布式训练,则通过在每个节点上产生多个进程来获得更好的多节点分布式训练性能。如果有Infiniband接口则加速比会更高。
在 单节点分布式训练 或 多节点分布式训练 的两种情况下,该工具将为每个节点启动给定数量的进程(--nproc_per_node)。如果用于GPU培训,则此数字需要小于或等于当前系统上的GPU数量(nproc_per_node),并且每个进程将在从GPU 0到GPU(nproc_per_node - 1)的单个GPU上运行。
2、NCCL 后端
NCCL 的全称为 Nvidia 聚合通信库(NVIDIA Collective Communications Library),是一个可以实现多个 GPU、多个结点间聚合通信的库,在 PCIe、Nvlink、InfiniBand 上可以实现较高的通信速度。
NCCL 高度优化和兼容了 MPI,并且可以感知 GPU 的拓扑,促进多 GPU 多节点的加速,最大化 GPU 内的带宽利用率,所以深度学习框架的研究员可以利用 NCCL 的这个优势,在多个结点内或者跨界点间可以充分利用所有可利用的 GPU。
NCCL 对 CPU 和 GPU 均有较好支持,且 torch.distributed 对其也提供了原生支持。
对于每台主机均使用多进程的情况,使用 NCCL 可以获得最大化的性能。每个进程内,不许对其使用的 GPUs 具有独占权。若进程之间共享 GPUs 资源,则可能导致 deadlocks。
3、DistributedSampler
torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=None, rank=None)
参数
-
dataset
进行采样的数据集
-
num_replicas
分布式训练中,参与训练的进程数
-
rank
当前进程的 rank 序号(必须位于分布式训练中)
说明
对数据集进行采样,使之划分为几个子集,不同 GPU 读取的数据应该是不一样的。
一般与 DistributedDataParallel 配合使用。此时,每个进程可以传递一个 DistributedSampler 实例作为一个 Dataloader sampler,并加载原始数据集的一个子集作为该进程的输入。
在 Dataparallel 中,数据被直接划分到多个 GPU 上,数据传输会极大的影响效率。相比之下,在 DistributedDataParallel 使用 sampler 可以为每个进程划分一部分数据集,并避免不同进程之间数据重复。
注意:在 DataParallel 中,batch size 设置必须为单卡的 n 倍,但是在 DistributedDataParallel 内,batch size 设置于单卡一样即可。
两种方法的使用情况,负载和训练时间
一、DataParallel

PID相同的是一个程序
在两张GPU上,本人用了3种不同batchsize跑的结果如下,
batch=64(蓝色),主卡3678MB,副卡1833MB
batch=128(黑色),主卡3741MB,副卡1863MB
batch=256(红色),主卡3821MB,副卡1925MB
总体看来,主卡,默认是指定的卡中序号排在第一个的,内存使用情况是副卡的2倍,负载不太均衡
batch=512时,训练时间和准确率
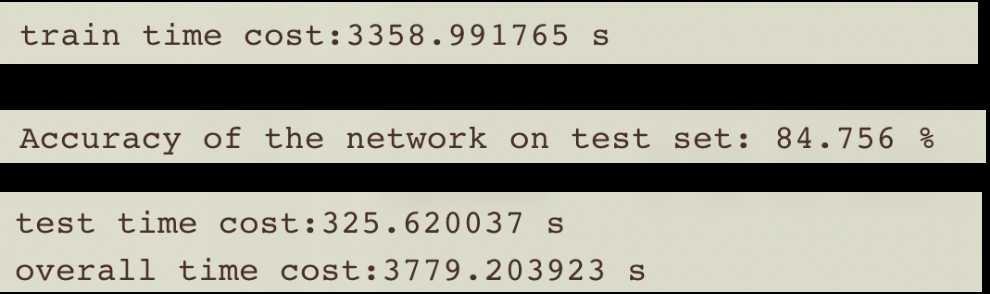
二、DistributedDataParallel
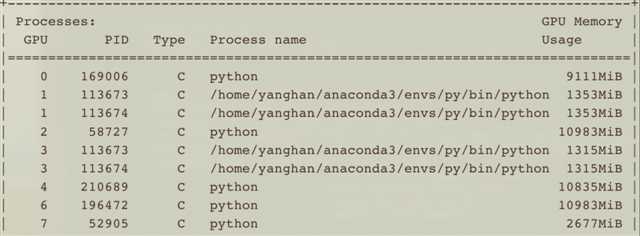
其中PID为113673、113674的是我的程序,用了两张卡,总体有两个进程,可以看到,负载相对很均衡了。
batch=500时,训练时间和准确率:
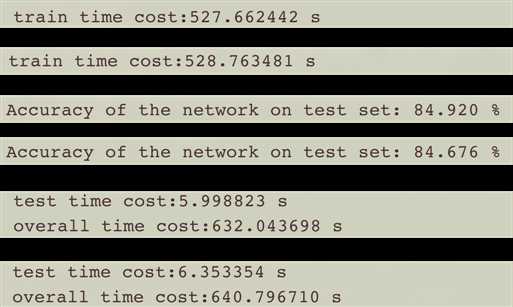
相比DataParallel,训练时间缩减了好几倍!推荐大家使用分布式数据并行
-------------------
参考:https://blog.csdn.net/zwqjoy/article/details/89415933
https://www.ctolib.com/tczhangzhi-pytorch-distributed.html
以上是关于Pytorch使用分布式训练,单机多卡的主要内容,如果未能解决你的问题,请参考以下文章
当代研究生应当掌握的5种Pytorch并行训练方法(单机多卡)
PyTorch多卡分布式训练DistributedDataParallel 使用方法