SparkStream
Posted zqzhen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了SparkStream相关的知识,希望对你有一定的参考价值。
有状态和无状态
无状态:仅限对收集周期内数据进行处理
有状态:将本次收集周期与前面的所有收集周期获得的数据统一进行处理,两个周期内的数据合并过程类似于SparkSQL中自定义聚合函数的buffer。
窗口函数
window operations可以设置窗口的大小和华东窗口的间隔来动态的获取当前Streaming的允许状态。基于窗口的操作会在一个比StreamingContext的批次间隔更长的时间范围内,通过整合多个批次的结果,计算出整个窗口的结果。
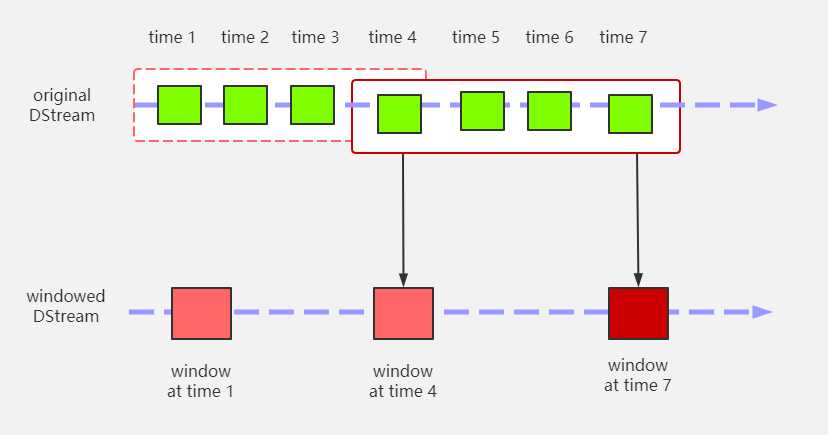
//scala中的窗口函数
val ints = List(1, 2, 3, 4)
val iterator = ints.sliding(2)
for (elem <- iterator) {
println(elem)
}
//spark中的窗口函数
val conf: SparkConf = new SparkConf().setAppName("111").setMaster("local[*]")
val context = new StreamingContext(conf, Seconds(3))
var line = KafkaUtils.createStream(context,"192.168.0.107:2181","zqz",Map("zqz"->3))
//窗口大小应该为采集周期的整数倍,窗口滑动步长也为采集周期的整数倍
line.window(Seconds(6),Seconds(3))
val value = line.flatMap(t => t._2.split(" ")).map((_, 1)).reduceByKey((_ + _))
context.start()
context.awaitTermination()
Trasform
允许DStream上执行任意的RDD-to-RDD函数,即使这些函数并没有在DStream的API中暴露出来,通过该函数可以方便的扩展Spark API。该函数每一批次调度一次。其实也就是对DStream中的RDD应用转换。
Join
连接操作,可以连接Stream-Stream,windows-Stream to windows-Stream、Stream-dataset
以上是关于SparkStream的主要内容,如果未能解决你的问题,请参考以下文章