可视化监控大型集群,这一个工具就够了!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了可视化监控大型集群,这一个工具就够了!相关的知识,希望对你有一定的参考价值。
许多企业使用Kubernetes来快速发布新功能并提高服务的可靠性。Rancher使团队能够减少管理其云原生工作负载的操作成本——但获得这些环境的持续可见性可能是一个挑战。
在这篇文章中,我们将探讨如何利用Rancher内置支持的Prometheus和Grafana快速开始监控编排工作负载。然后,我们将向你展示如何将Datadog与Rancher集成,通过丰富的可视化、算法告警和其他功能,帮助你获得对这些临时环境更深入的可见性。
Kubernetes监控所面临的挑战
Kubernetes集群本质上是复杂和动态的。容器以极快的速度启动和关闭:在对数千家组织的超过15亿个容器进行调查时,Datadog发现,编排容器的周转速度(一天)是未编排容器的两倍(两天)。
在这种快节奏的环境中,监控你的应用程序和基础设施比以往任何时候都重要。Rancher内置支持开源监控工具(如Prometheus和Grafana),允许你从Kubernetes集群中跟踪基本的健康和资源指标。
Prometheus按照预设的时间间隔从Kubernetes集群收集指标。虽然Prometheus没有可视化选项,但你可以使用Grafana内置的仪表板来显示健康和资源指标的总体情况,例如你的pods的CPU使用情况。
然而,一些开源解决方案并不是为了监控大型、动态Kubernetes集群而设计的。此外,Prometheus要求用户学习PromQL(这是一种专门的查询语言)以分析和汇总他们的数据。
虽然Prometheus和Grafana可以为你的集群提供一定程度的洞察力,但它们不能让你看到全貌。例如,你需要连接到其中一个Rancher支持的日志解决方案,以访问你环境中的日志。而为了排除代码级问题,你还需要部署一个应用程序性能监控解决方案。
最终,为了充分可视化你的编排集群,你需要在一个平台上监控所有这些数据源——指标、跟踪和日志。通过向整个企业的团队提供详细的、可操作的数据,一个全面的监控解决方案可以帮助减少检测和解决的平均时间(MTTD和MTTR)。
Datadog Agent:自动发现和自动伸缩服务
为了获得Rancher解决方案中每一层的持续可见性,你需要一个专门用于实时跟踪云原生环境的监控解决方案。Datadog Agent是一款轻量级的开源软件,它可以从你的容器和主机中收集指标、跟踪和日志,并将它们转发到你的账户,以便进行可视化、分析和告警。
由于Kubernetes部署处于不断变化的状态,因此无法手动跟踪哪些工作负载在哪些节点上运行,或者你的容器在哪里运行。为此,Datadog Agent使用Autodiscovery来检测容器何时启动或关闭,并自动开始收集你的容器和它们正在运行的服务的数据,如etcd和Consul。
Kubernetes内置的自动弹性伸缩功能可以根据需求(如CPU使用量激增)自动增加或减少工作负载,从而帮助提高服务的可靠性。自动伸缩还可以通过调整基础设施的规模来帮助管理成本。
Datadog扩展了弹性伸缩这一功能,使你能够根据已经在Datadog中监控的任何指标(包括自定义指标)自动伸缩Kubernetes工作负载。这对于根据需求的波动来扩展集群是非常有用的,特别是在“双十一”这样的关键业务时期。假设你的公司是一家零售商,拥有繁忙的在线业务。当销售正在起飞时,你的Kubernetes工作负载可以根据作为活动指标的自定义指标(如结账数量)进行自动伸缩,以确保流畅的购物体验。有关使用Datadog自动伸缩Kubernetes工作负载的更多细节,请查看以下文章:
https://www.datadoghq.com/blog/autoscale-kubernetes-datadog/
Kubernetes特定的监控功能
无论你的环境是多云、多集群还是两者兼而有之,Datadog高度专业化的功能都可以帮助你实时监控你的容器化工作负载。Datadog通过从Kubernetes、Docker、云服务和其他技术导入的tag自动丰富你的监控数据。Tag为你的环境任意一层提供了持续的可见性,即使单个容器启动、停止或在主机间移动,你都能够获得可视化。例如,你可以搜索所有共享一个标签(例如,它们正在运行的服务名称)的容器,然后使用另一个标签(例如,可用性区域)来分解它们在不同区域的资源使用情况。
Datadog可以收集超过120个Kubernetes指标,帮助你从控制平面健康状况跟踪到pod级CPU限制的一切。所有这些监控数据都可以直接在应用中访问,而无需使用查询语言。
Datadog提供了几个功能来帮助你探索和可视化容器基础设施的数据。Container Map(datadoghq.com/blog/container-map/ )提供了一个Kubernetes环境的鸟瞰图,并允许你通过任何标签组合来过滤和分组容器,如docker_image、host和kube_deployment。
你还可以根据任何资源指标的实时值对容器进行颜色编码,如系统CPU或RSS内存。这让你可以一目了然地快速发现资源争夺问题,例如,如果一个节点比其他节点消耗了更多的CPU。

实时容器视图(Live Container view)可以显示基础架构中每个容器的流程级系统指标——以两秒的粒度绘制。由于 CPU 利用率等指标可能非常不稳定,这种高度的颗粒度确保了重要的峰值不会在噪音中消失。
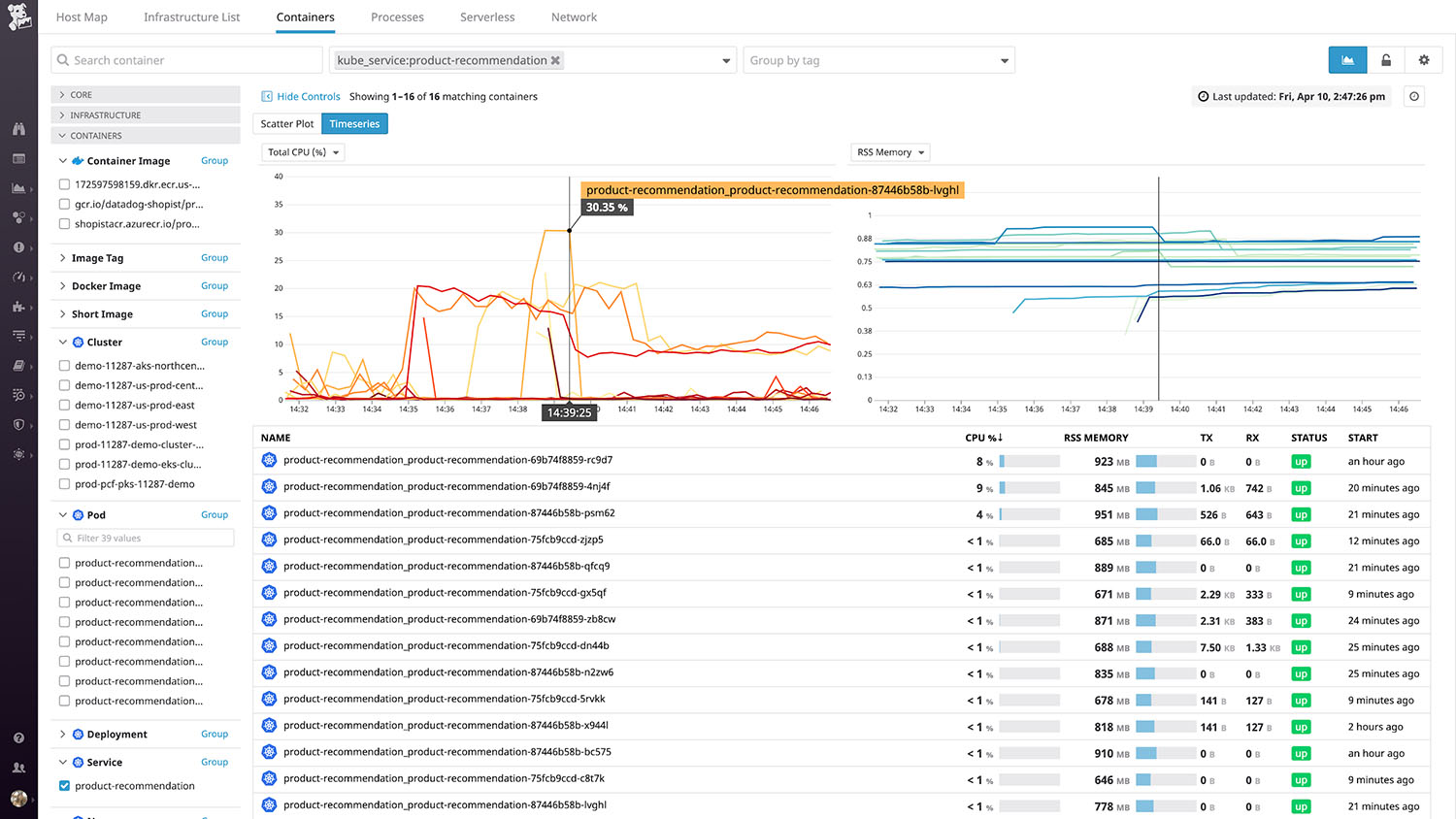
Container Map和 “实时容器 "视图均允许你使用任意组合的标签(如镜像名称或云提供商)对容器进行过滤和排序。要了解更多细节,你还可以单击以检查在任何单个容器上运行的进程,并查看从该容器收集的所有指标、日志和跟踪,获取这些信息只需点击几下。这可以帮助你调试问题,并确定是否需要调整资源的配置。
通过Datadog网络性能监控(NPM),你可以跟踪整个Kubernetes部署的实时网络流量,并快速调试问题。从本质上讲,Docker容器只受制于可用的CPU和内存量。因此,单个容器可能会使网络饱和并使整个系统瘫痪。
Datadog可以帮助你轻松隔离消耗最多网络吞吐量的容器,并通过导航到该服务的相关日志或请求跟踪来确定可能的根本原因。
Datadog+Rancher协同工作
通过Rancher的Datadog Helm chart,你的团队可以在几分钟内开始监控他们的Kubernetes环境。Datadog与Rancher协同工作,可以让你使用Rancher管理不同的协调环境,并部署Datadog来实时监控、排除故障和自动扩展环境。
此外,Datadog的算法监控引擎Watchdog可以发现并提醒团队成员注意性能异常(如延迟峰值或高错误率)。这使得团队能够在潜在问题(例如容器重启率异常高)升级之前解决问题。
我们已经向你展示了Datadog如何帮助你获得Rancher环境的全面可见性。通过Datadog,工程师可以使用APM来识别单个请求中的瓶颈,并准确定位代码级问题,收集和分析整个基础设施中每个容器的日志等。通过在一个平台上统一指标、日志和跟踪,Datadog消除了切换上下文或工具的需要。因此,可以加快团队故障排除工作流程,并充分利用Rancher管理大规模动态集群的全部潜力。
以上是关于可视化监控大型集群,这一个工具就够了!的主要内容,如果未能解决你的问题,请参考以下文章
数据可视化之PowerQuery篇二维表转一维表,看这篇文章就够了
数据可视化之PowerQuery篇二维表转一维表,看这篇文章就够了