架构师实践课微服务如何拆分?大型微服务项目从何下手?
Posted 七牛云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了架构师实践课微服务如何拆分?大型微服务项目从何下手?相关的知识,希望对你有一定的参考价值。
继上期【架构师实践课】单体和微服务怎么选?单体到微服务怎么转?之后,万老师为我们带来了微服务系统设计专题的第二个议题:微服务设计痛点。
以下内容根据实践课整理。

微服务如何拆分
首先想和大家分享的,就是微服务应该如何拆分。

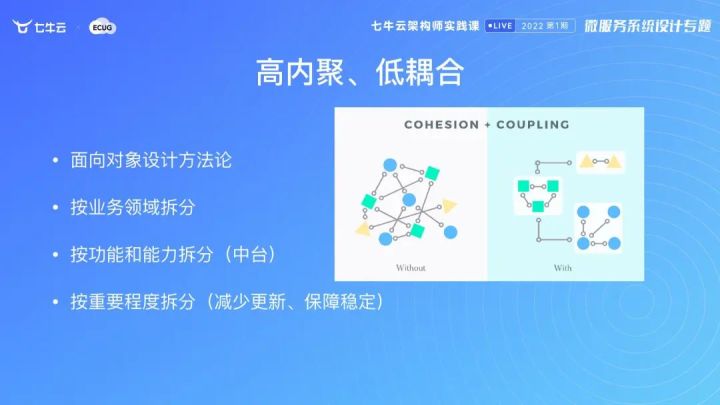
高内聚、低耦合
首先我觉得做微服务拆分,第一点需要考虑的就是面向对象的方法论。像下图所示,左边的部分比较分散,耦合度高,相对来讲没什么内聚性可言,反观右边就比较规整。其实我们做微服务拆分的时候,尽量让拆分出来的每一个服务是高内聚低耦合的,我们通过 API 或者是 RPC 的定义来做交互,这样就可以比较好拆分我们的微服务。
另外我们还要考虑从业务领域里来拆,不同的大功能点可以拆一拆。但是我也不建议拆太细,当你不确定这个东西要不要拆的时候,你最好不要去拆它。当你实在需要的时候再由粗到细地拆。按照功能和能力拆也是其中的一个场景,把一些常用的能力做下沉。比如做 UGC 内容肯定要鉴黄,鉴黄就是可以下沉的内容,不要做重复建设。下沉的能力多了以后,其实一个中台就出来了。大家避免重复造轮子,可以通过约定的 API 来调用。
而业务发展到一定阶段以后,会希望有些业务不更新,这样的情况就可以把它拆出来。当你的业务体量大到一定程度以后,只管既定抽象好的能力,其他所有的相关业务可以拆分出来。
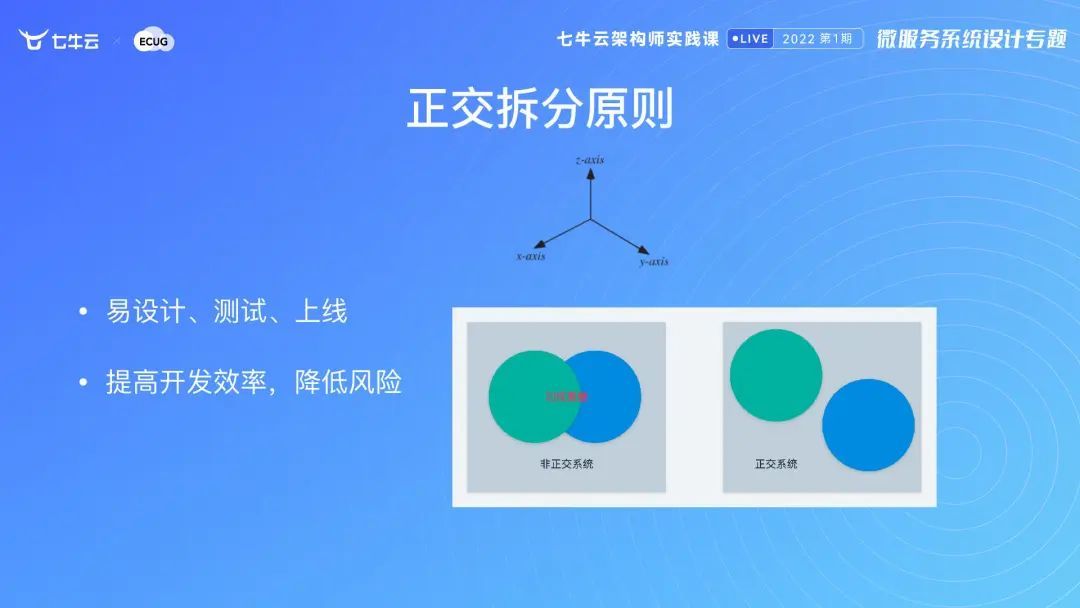
正交拆分
首先我们来了解什么是正交拆分,以 X 轴 Y 轴举例,它们就是正交并且相互垂直的,如果是这样,设计好以后再去修改它、写编码、测试、上线,相互之间不会有影响,以下图右边对正交系统为例,我改绿色不会影响蓝色。但是像左边叠在一起,就很容易相互影响,改中间重叠这一部分功能,A 和 B 都会影响。我们进行正交拆分后,相互之间没有相关性,开发效率也会比较高。原因在于我不需要和别人交流,在自治的系统中就可以搞定,只要保证我的接口是一致的,就不会对他人造成影响,从而降低风险。
避免服务过微
这是一个小厂甚至大厂都会面临的误区,服务过微我们一定要避免。每一个服务里一般有好多个 API,你把每个接口都拆分,最后就会发现公司不大但是却有上千甚至上万个微服务,没有足够的人力保障,又怎么去微服务呢?

这种情况导致一个用户请求过来,A 调 B,B 调 C,C 调 D,一长串调下去,这样一来,问题不仅反映在成本和开销上,维护和性能都难以保障。所以在我的经验中,系统里规定不超过四个调用。这样保证服务力度是适中的。另外也要从团队上考虑,在微服务互相解耦的情况下让团队足够轻量,也是非常重要的。从以上多个方面,去避免微服务过微的问题。
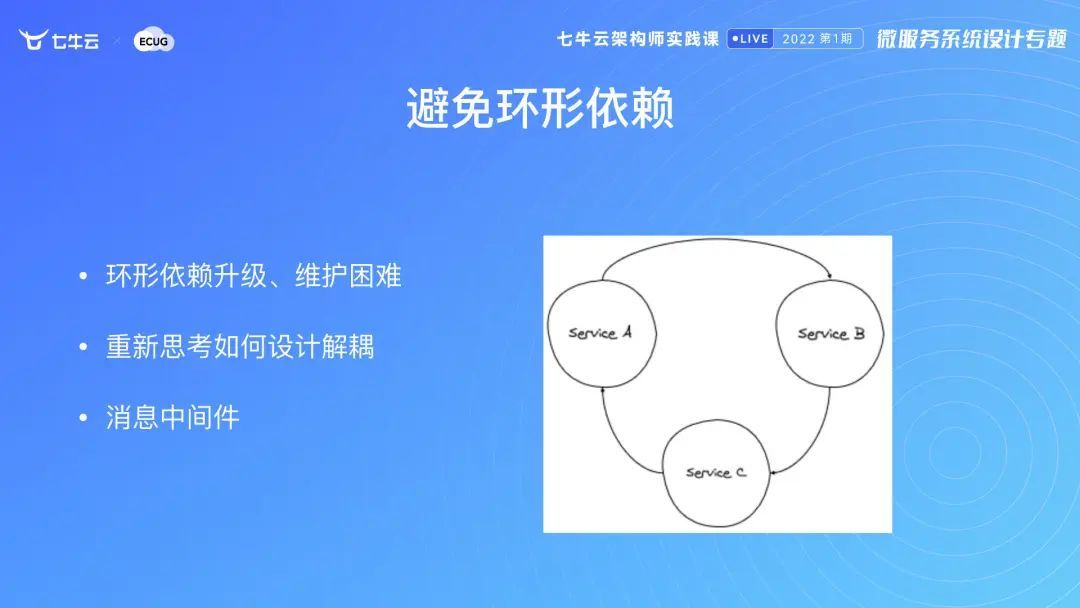
避免环形依赖
我在 go-zero 有这样的设计,以下图为例,比如说 A 调 B 的过程中,在启动的时候就会监测 B 的启动情况,如果没有启动便无法继续。正是通过这样的设计,避免 A 调 B,B 又调了 C,C 去调了 A 的局面。所以说我希望开发者重新思考如何去解耦,如何让服务设计解耦?解耦可以通过完全将其剥开实现,也可以用中间件的方式,去避免环形依赖。
考虑服务并行化、异步化
如果服务希望能够比较高效地返回,我们在设计上尽量保障它可以并行调用。在我的经验中,等待时间在0.1 秒用户认为是没有任何延迟的,1 秒内用户认为是可接受的,3 秒以上就会造成大量用户流失。所以在优化的时,能并行则并行。然后在不需要同步结果的,可以把它设计成异步化的方法,最简单的方式就是通过消息对列来解耦。我们可以通过 go-zero 提供的 mapreduce 的方式。Mapreduce 就是把请求分拆成很多个,最后汇总到一个地方。这也是社区中广受欢迎的做法。
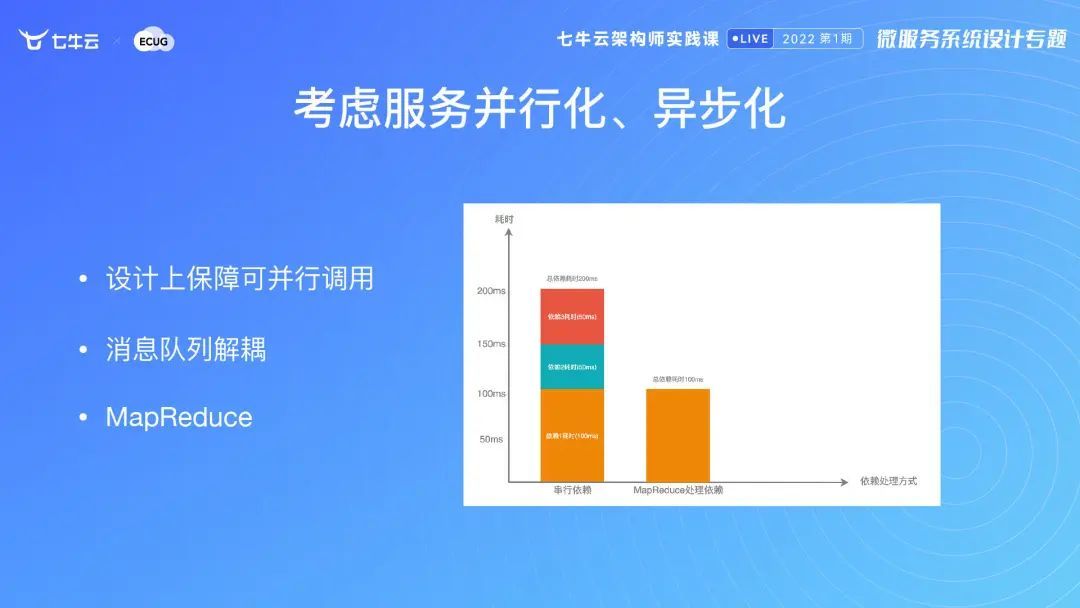
那么优化的结果是什么?在上图中我们可以看到,假如有 3 个请求可并行,如果最长请求是 100毫秒,另外两个 50毫秒,那我最后的结果依赖最长的只有 100毫秒。所以通过这样的方式,在我原来的系统中,最繁忙时段的平均延迟在 30毫秒以内,是非常非常快的。我也推荐大家可以回顾自己的业务,用这样的形式进行优化。
考虑接口幂等性
如果业务涉及到库存、支付等领域,是要考虑幂等性的。比如说 go-zero 里面,是坚决不加重试这个方法的。重试会带来很多问题,本来我们写程序就是面向故障编程,我们要允许失败承认失败。这样来看自动重试就出现较大弊端,相当于我们自己人为把系统干掉了。

那么说回幂等,要解决幂等有几种常见的方式,比如说我们在 DB 里面建一个 ID 作为唯一索引,当第二次写这个唯一索引肯定就重复了,这是一个方式。第二个可以用 token 的方式,当 token 消费完了下次就不会重复处理。另外还可以建去重表之类的东西,都可以去解决。
数据结构独立性
go-zero 有两个概念,一个是 API 文件来定义客户端请求和返回是什么,另一个是 RPC 的请求和返回,两者是不同的数据结构。可能大家想问能不能重用,因为每次都要写很麻烦。其实不行,原因在于 API 这一层本来就是对外的,所以对外提供 API 接口一定尽可能稳定,内部要增加一个功能 RPC 肯定要改,如果说你放一个的话,外部的 API 也改了。这个数据两面是透传的,会造成感染。就像我们现在 go1.18 出来以后,泛型是会传染的,你一用了泛型,依赖你的就都会有泛型。正是因为这种传染性,我觉得在设计结构的时候,尽可能保证它的独立性,不要把数据接口混用,也最好不要去用一个现有的方法来 copy/paste。

拒绝联表查询
我们在做微服务设计的时候,要尽可能的拒绝联表查询,这个点讲的非常多,但是很多人不能理解这个问题。上面层制约再好没有用,我们一定要去避免数据的耦合。绝大部分业务都会牵扯到 DB 这一层的,只要数据没有耦合便很好治理。

而且当 DB 跟不同服务共享时,会导致性能问题。不同的业务来做复杂的操作,但是对 DB 来讲,让大家把所有的东西全都清楚落地是比较难的。我是倾向简单化,喜欢把所有的东西都落到最重要的一条规则里面。比如只要是 C 端的,如果我们检测你有 JOIN 就不让你合代码。通过一个简单的规则,就能比较好地落地。
大型微服务项目从何下手
下面我想和大家聊的话题是,大型微服务项目应该从何下手。

下图是大型微服务的架构概览,包含的信息还是非常多的。
首先看我们大型的系统有哪些部分?安卓、ios、WEB 端或 PC 通过 CDN 进来,然后通过 WAF 走到 Service Load balancer、nginx 里面来。接下来到我们的 kubernetes 集群,再往上走就是 Nginx 和线上服务,来把日志搜集到 kafka 里面,然后 kafka 里会把这些数据收集做大数据分析。
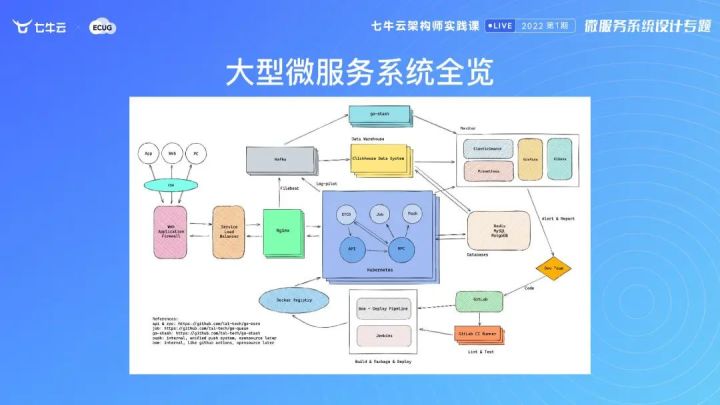
然后上面通过 go stash,也就是我基于 log stash 写的一个简化版,基本上可以使得性能提升 5 倍左右,需求从原本的 30台服务器降到 3-5 台,所以能写到 ES 里面做日志的查询。
中间的这个 kubernetes 集群是很多个集群,然后右边是日志查询。因为有问题的时候需要通过一个 ID 把所有的东西查出来。会有大屏去显示我们的监控指标。
后面是我们的数据,会写到 mysql 和 mongo 里面,对于关系数据会写到 mysql 里面,对于消息等文档化的数据会写到 mogo 里面,然后做缓存。
我们会通过右上角的监控进行告警。但是监控一定要少而精,如果是「狼来了」式的报警,就毫无价值。
有了报警以后,我们可以通过 get larunner 或 get up 的方式来触发,把我们的代码提交过来以后,会触发应用信息系统 CICD 的流程。我们的 CICD 的流程还是比较智能的,比如说每天晚上 6 点以后发,发完了会自动去提交灰度,预发环境、灰度环境。触发到第二天早上 10点之前,如果没有人为干预,我们就会再灰度发到我们的 kubernetes 集群里面,如果一个小时没问题,我们自动触发第二个、第三个、第四个集群,只要我们触发一下发布,整个流程是自动的。
全局视角看微服务系统

因为我们今天讲架构课,肯定要从更全局的视角看我们的微服务,正如上图我列出来的这些问题,都需要我们认真考虑。
自建 or 公有云
首先我们要考虑的就是选择自建还是公有云?虽然现在自建不多,但也是一个选项。因为如果用公有云,要受制于约束条件,私有云就可以自己来做,可控性比较强,利于数据安全,但缺点在于运维的成本比较高,需要自行去进行构建。你要把这些东西构建起来,其实是比较麻烦的。

那么对于公有云来讲呢,首先优势在于可扩展性很高,可以承载很大的业务增长空间,不用做额外的考虑。另外公有云把一些可靠性的问题都已经帮你解决了,当然我也会用混合云的方式,来让可靠性更高。同时它的运维成本低很多,我之前的项目里差不多有 5000 万用户和 1000万日活,只需要两个运维就能稳定支撑 4 个 9 的稳定性。而且我们频繁发布频繁更新,如果没有云厂商肯定是搞不定。
那么我在选择公有云的时候,主要有两个考虑的点,首先是云厂商的技术是不是独有的?如果是独有的我不会用,因为会被它绑定,后续对迁移造成困难。
另一个考虑是多云。因为云厂商它也会有故障,所以如果在成本允许的情况下,我推荐大家考虑多云。
系统安全性和数据安全性

系统安全性我认为是重要的,因为一旦出现了安全问题,小则业务故障大则公司倒闭,所以大家一定要重视。我们在做系统安全性的时候,是需要去考虑一下数据安全的,不能被别人黑进来把数据都拉走。比如大家知道的各种密码泄露事件,都是系统安全隐患导致的。
所以说我们在做架构的时候,肯定要方方面面保障我们系统的安全。我们能不对外一定不要对外,一定要最小化端口和服务的接口。假如节点是对外的,一定要去检查哪些端口在监听,有哪些服务起了。因为我们的很多服务是开源项目,万一出了一个安全漏洞,马上就会被扫描,导致整个系统被劫持,数据被盗走。
对我们来讲,假如你要保留一个端口,那就只保留一个,比如说你要保留 443 就只保留它,其他全部关掉,这也是一个很重要的点。
另外我们公司做大以后,你不可能保证所有人都是充分可信任的,这也就要求我们防外也防内。所有的事情需要做审计,要做隔离,要有堡垒机。比如说异地办公的情况会通过 VPN 的方式连到公司,所以堡垒机要加 IP 的限制,这是一种非常有效的防护。
社会工程的攻击大家也不要忽视。哪些事情能做哪些事情不能做,很多行为已经触犯法律,需要大家一步步提高自己的安全意识。但同时社会工程的攻击是最难防的,所以请大家务必小心。
最后还有一点要提醒大家,离开工位请锁电脑。
负载均衡、反向代理和 ingress

负载均衡在业务量不大的时候,不一定需要,如果有需要直接买 SLB 就好了,成本上可以接受,也能简单高效地解决业务架构的问题。
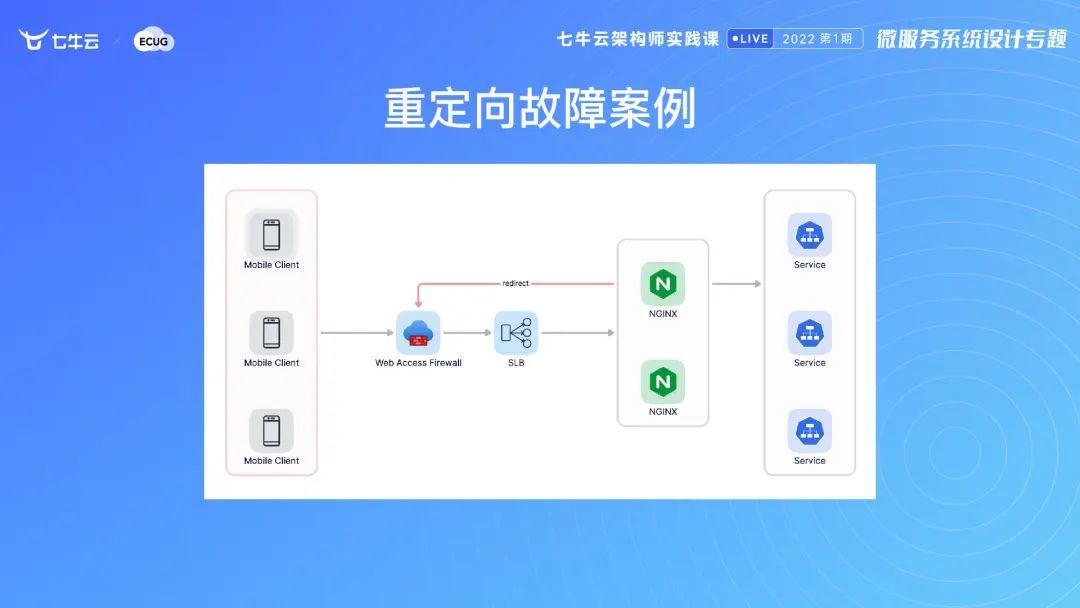
Nginx 反向代理是我踩过的一个大坑。在业务体量非常大的时候,我曾经用过的 Nginx 反向代理,透过前面的 WAF 我们到 Nginx 里配了一个反向代理,然后配重定向打到内网里面来了,已经从 SLB 进到 Nginx 里面,再通过重定向并到外网去。比如说我们有 10台 Nginx 反向代理机器,那我每一个打的 WAF 的点,都是我们 10台里面的一个,但是 WAF 有一个底层的反攻击,意味着同一个 IP 如果量过多,它就认为你是攻击。这样的情况下,一下就把我服务干挂了,后面服务却没有任何压力。通过我们紧急排查,发现问题出在重定向。后来我们就定了一条军规。所有进了内网的请求,一定不能再出外网。我们内网的请求一定都会有"int. "开头,来表示这是一个内网域名,如果我们配重定向的时候,没有这个 "int." 开头是不会通过的。这是一个典型的错误,分享给大家,希望能有所帮助。
对反向代理来讲,经常会有人提这样一个问题,就是前面加了一个反向代理,那在 kubernetes 要不要加一个 ingress 呢?我觉得这取决于你的选择,不管怎么来说,到 ingress 里也是在 kubernetes 机器之间做转发的,这从本质上来说你是逃不掉的。但对我们来讲,Nginx 每台都是一样的,可以统一管理。然后你放到里面来,如果直接暴露,用亲和性把它部署到一些 ingress 的节点上面去。但是因为这上面一定是 kubernetes 的,那么 Kubernetes 跟里面的集群是联在一起的,这种方式相当于 kubernetes 集群不会暴露出去。我基本上用两种,一种是 Nginx 放在外面,一种是 ingress。
关于重定向的问题我很形象地画了一个图,从前面过来了以后,通过 WAF 打到 SRV 里面,然后到 Nginx 里面,接着又重定向又到 WAF 里面去,又返回到我们外网,直接把几个 Nginx IP 全部搞崩溃,就是这样一个问题。
Kubernetes or ECS?

关于这两者的选择,我认为你最早期可以用 ECS,kubernetes 还是需要有节点,你会增加成本。但是 kubernetes 有一个好处,你业务量起来以后,kubernetes 分化是一个最终状态。大家理解 kubernetes 的时候,我觉得两个点比较好去理解。第一个是一个运维工具,你不要觉得这是一个多高深的东西,它帮助我们解决了很多运维的痛点。第二是它让我们日常运维工作变得简单。
负载均衡是比较常见的,在 go-zero 中,把这些都充分集成进去了。资源充分利用也比较好理解,因为你原来的节点里面不一定能调度好,但是 kubernetes 会当成一个大的水池来用,就会让整体的水位比较高,所以你每个节点就比较高。原来你需要自己去调度,十有八九资源利用率是上不去的,而在原云生时代,利用 kubernetes 的系统就能解决这个问题。也希望大家不要闭门造车,一定要充分去跟着时代潮流往前走,享受原云生时代的红利。
kubernetes 集群里也有一个蛮重要的经验,就是包含上前节点的 kubernetes 集群一旦卡住,问题是很难解决的。虽然出现比较少,但是万一遇到就会吃大亏。我曾经就相信了 kubernetes 号称的平滑升级,导致服务挂了两个小时。从此以后我把 kubernetes 集群拆成了好多个集群,每个我就控制在 100个节点,好处在于集群是滚动升级的,可以做灰度,基本上单个服务出现问题不会影响大局。
数据库选型、设计和治理

在数据库的选型问题上,mysql 用的比较多,mongo 也是可以的,主要根据投入产出比来做选择。
数据备份也很重要,要定期演练。不要等到问题出现发现没有办法恢复,我的经验是每个月必须演练数据备份的。
DB 需要有一些波动保护的机制,缓存大家可以通过 go-zero 自动去做。
数据收集、分析要不要做?

这个问题主要看大家的业务需要,如果数据采集在业务上,需要考虑怎么呈现,为业务决策提供依据。另一方面也要看公司认不认可,需要充分沟通。
监控报警
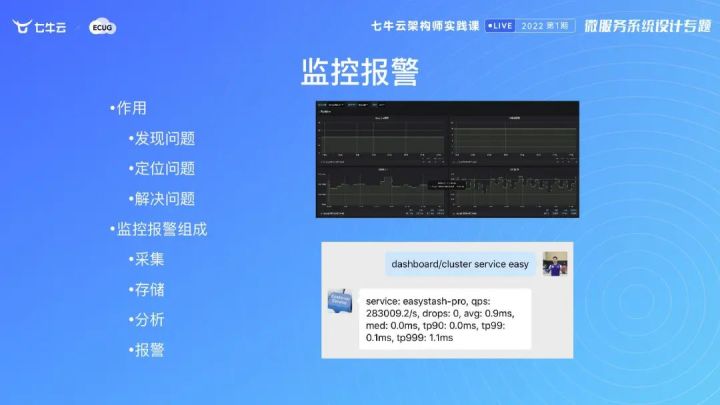
监控报警非常非常重要,如果你没有监控报警,就会变得非常盲目。我经常说没有度量就没有优化,都不知道系统是什么样,其他一切都没有进行的基础。
代码仓库,单仓 or 多仓?

多仓的边界清晰,代码权限容易控制。单仓比较受代码规范,比较容易重用和重构。所以我一直是用单仓,因为一些不好的东西我可能忍不住就想改掉,但是多仓我就不知道要到哪搞了。
持续集成、持续交付和持续部署
我是比较强调单元测试的,我们把各种规范落到持续集成里面,自动去跑。尽量不要人工去强制一些规定,落到 CI 里面,不对代码的东西提交不了,大家规范规定,执行得非常到位。
持续集成可以到 go-zero 里面看,我们还是很严格的。
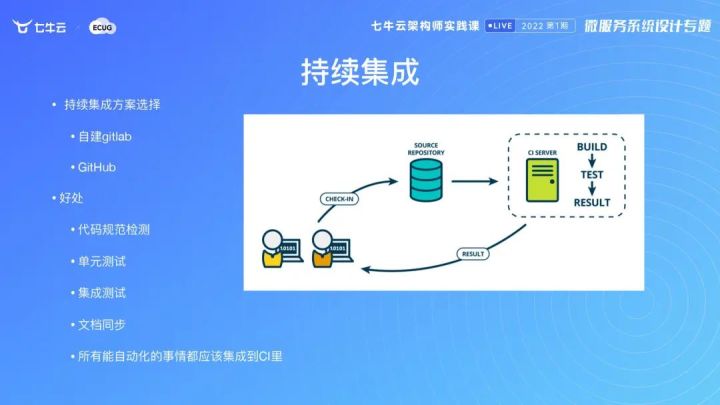
交付分几种,你可以用自动测试、自动 CI 方式,然后人为触发到线上。
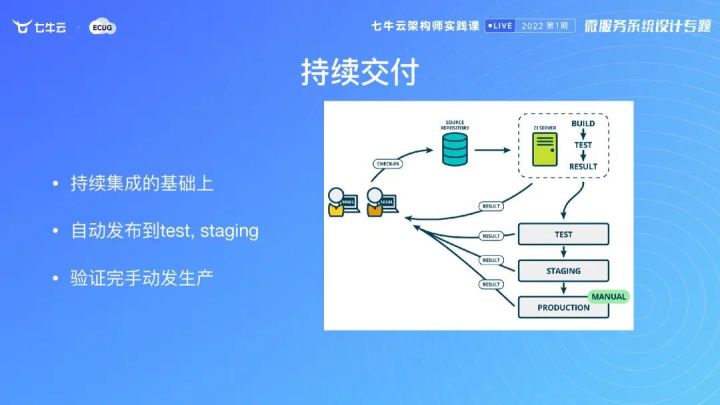
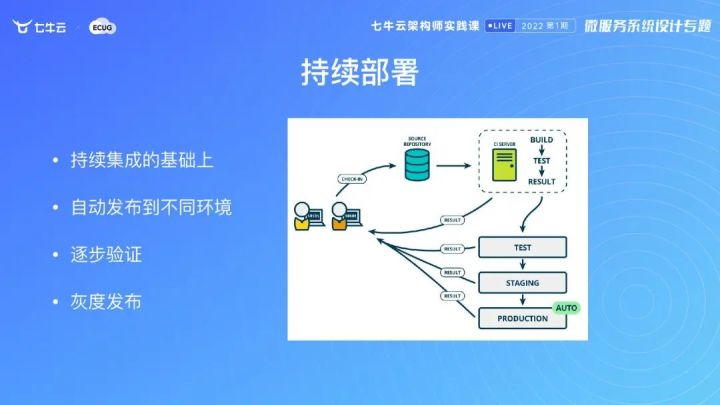
在不确定的时候,你需要通过手动触发。如果你的机制建得比较健全,你可以用灰度的方式去做自动触发。自动触发要有保障,逐步放量逐步验证,然后通过灰度的方式,逐步上到所有的集群。
以上就是我想分享给大家的内容,欢迎大家持续关注我们的架构师实践课,后续会有更多知识干货带给大家,谢谢。
以上是关于架构师实践课微服务如何拆分?大型微服务项目从何下手?的主要内容,如果未能解决你的问题,请参考以下文章