小话数据结构-图 (聚焦与于实现的理解)
Posted simon5ei
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了小话数据结构-图 (聚焦与于实现的理解)相关的知识,希望对你有一定的参考价值。
数学使我们能够发现概念和联系这些概念的规律,这些概念和规律给了我们理解自然现象的钥匙。
——爱因斯坦
前言
本文代码基于C++实现,阅读本文,需要有以下知识
-
教熟练使用C++ STL库中的vector,map,pair等;
-
对于递归和简单搜索算法(dfs,bfs)有粗浅的理解;
-
稍微的离散数学或者是线性代数知识(可能是我瞎掰的,没有也罢 ?? )
本文针对算法或数据结构初学者(比如我)写下,本人不才,如有错误请轻喷 ?? 。
瓶颈
在学习“数据结构”这门课之前,“图论”这个略显高级的词汇看起来还与我那么的遥远,在经过了“离散数学”的学习之后,我慢慢认识到其实数据结构就是离散数学模型的代码实现,并且在不断的学习中,我开始能以我自己的思维去理解图论的知识。
数据结构的教科书上,每个知识点都会系统的从“定义——术语——存储结构——相关操作”娓娓道来,然而,各种各样的障碍阻碍着我们认知的过程。对于离散数学不熟悉的,一时间无法抽象出模型,教材上冗长的代码实现,给读者一种晦涩难懂的感觉。这时候我们就要思考离散数学的本质——将具体问题抽象为一般问题,在由算法解决。因此,我们在一开始不必过于在意方法,而是应该聚焦与实现,像大学物理做实验一样,多操作几遍,自然就熟能生巧,甚至开发出新的理解。
你得从用户的体验出发,推倒用什么技术。 ——乔布斯在1997年回归苹果发布会上回答提问
案例-引入
什么是图?简单说就是点与点之间的网状关系。
比如以下有6个城市之间的铁路线。
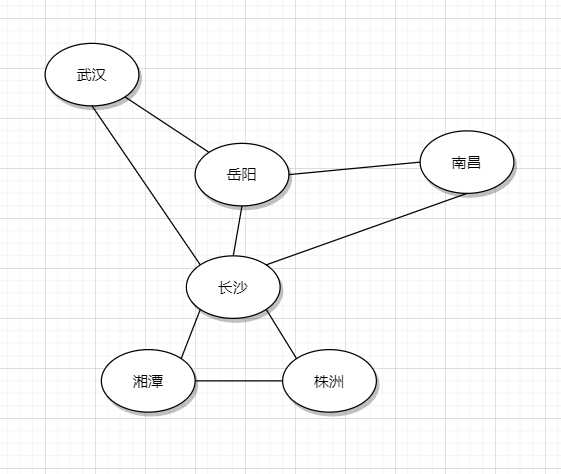
地图就是一个很经典的图
那么,我们是如何表达他们的关系的呢
我们使用邻接表or邻接矩阵
为什么是邻接表/矩阵
邻接表和邻接矩阵是图的两种常用存储表示方式,用于记录图中任意两个顶点之间的连通关系,包括权值。
(在图论相关的案例中,我们会特别频繁的用到这两种表示方式)
我们不谈什么二元组三元组的,想想啊,图重要的顶多就仨玩意:节点,边,权值,而使用邻接表和邻接矩阵已经可以清晰简洁的表达这些关系了。
我们先看看邻接表和邻接矩阵怎么建;
邻接表
emm,用图表示就是上面那张图啊,代码实现的话,我们用stl的vector更方便一点
#include <iostream> #include <vector> ? struct edge{//边信息,边有啥属性往里丢就行 int to;//该边可以去往的下一个节点编号,有明确指向,是单向边。 int value;//存边的权值,如果没有可以直接忽略 edge(int t,int v) :to(t), value(v){};//构造函数 }; ? vector<edge> node[n];//用vector实现邻接表的存储 //ps:边信息只有一个可以直接存int,两个可以用stl的pair,三个及以上就肯定要用struct了 //vector<int> node[n],vector<pair<int, int> >都是可行的,自己清楚意思就行
这里是什么意思呢,就是我有n个vector数组,每一个数组表示一个点的信息,vector里存的是边(edge),每一个点到点的通路意味着有一个对应的edge信息。
那么,如何把信息存入邻接表呢,我们假设用一下流程输入(大概就是平时做题的时候题目要求的输出啦)
先假设每条边的权值都是一样的,就设为“1”吧
//第一行为两个整数n,e,分别表示节点数,边数,随后n行,输入节点信息,在随后e行,接受边信息
6 8
武汉 岳阳 南昌 长沙 株洲 湘潭
武汉 岳阳
岳阳 南昌
武汉 长沙
南昌 长沙
岳阳 长沙
长沙 株洲
长沙 湘潭
湘潭 株洲
#EOF
那么,在C语言里面我们这么处理输入
map<string,int> tab; map<int,string> tab0; //建立散列表(哈希表),使每个城市的编号和名字可以相互连接 int n,m; cin>>n>>m; for(int i=0;i<n;i++){ string name; cin>>name; tab0.insert({i,name}); tab.insert({name,i}); //给每一个城市编号 } while(m--){ edge tmp; string a,b; node[map[a]].push_back(edge(map[b],1)); //构造函数中map[a]表示名为a的城市对应的编号,1表示权值,存入vector数组g中 node[map[b]].push_back(edge(map[a],1)); //因为是双向边所以正向反向都存一遍 }
这样的话,我们的邻接表就完全存储好了
对于任意一个点,我们要遍历其相邻点,只需要用一下代码
//输入城市名字 输出其相邻所有城市的名字 ? string name; cin>>name; for(auto it=node[tab[name]].begin();it!=g[tab[name]].begin();it++){//遍历name节点的所有边 cout<<tab0[it->to]<<endl; }
假如我们输入
岳阳
那么就会返回
武汉
南昌
长沙
整个邻接表的存储和访问过程就是以上的样子了
邻接矩阵
这个就很好理解了,就是一个n*n的二维数组模拟矩阵,表达的是点与点之间的关系,我们沿用上一个例子里的输入,我们建立出来的矩阵大概是这样
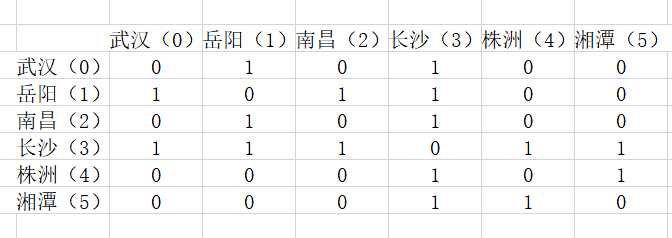
这个邻接矩阵只是判定有无直接相连的,我们用一个6*6的二维数组可以很轻松的建出来,没有自旋,未联通和自我比较设置为0(false),已联通即设置为1(true)。
案例-常见问题
(PS:本人才疏学浅,只介绍部分案例的大致思维路线,细节欢迎各位深入思考)
我们接着上一个案例看,对于很多情况,邻接矩阵像上面这样,就算建出来了,但是我们现在用的,是一个实实在在的生活中的例子,谁都直到武汉和南昌之间必定可以通过铁路线到达,只是会经过别的站台。
这个时候就引出了一个问题,按照邻接表来看,武汉和南昌实际上是通过其他的节点连接起来了的,只是没有直接连接。
然而此时,从“武汉“到”南昌”实际上有多条线路
武汉->岳阳->南昌
武汉->长沙->南昌
武汉->长沙->岳阳->南昌
武汉->岳阳->长沙->南昌
武汉->长沙->湘潭->株洲->南昌
………………
那我们给其付的权值到底是2,3,4还是多少呢?
这就可以引入到一个常见的图论问题——“最短路”了
最短路
(PS:最短路问题在算法竞赛和数学建模竞赛中都是非常常见的)
故名思意,当我们想要直接去往某个目的地时,一定是讲究时间效率的,我们不愿意走太长,更不愿意绕圈子,用规范的话说就是:“找最短路,并且避免系统资源浪费”,那我们就要先走一遍所有路径,看看哪个路径可行(好比每天高铁第一班车是“探路车”)。
假设我们要从武汉出发,去南昌:
我们从武汉开始遍历武汉接下来可以到达每一个城市
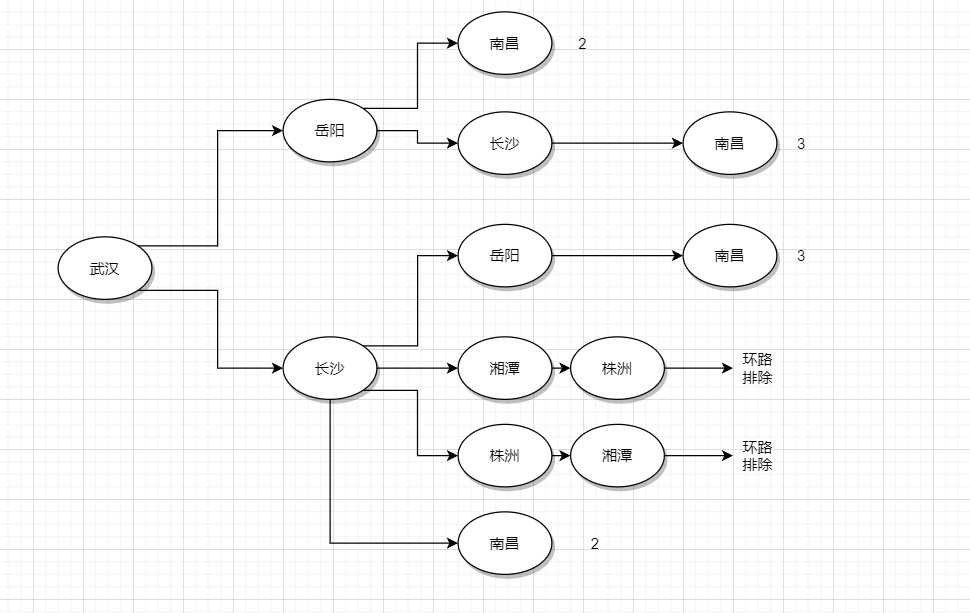
如此以来,逐个分析每个为直接相连的点,我们可以得到整个图的带权值的的邻接矩阵表示,其中有一个要点,即点不能重复访问,而BFS按照层次遍历邻接表的模式非常契合这个目的。我们沿用上方的输入和邻接表的存储形式,以下给出大致的伪代码:
#include<queue>//stl的queue容器 ? void bfs(int st){ queue<edge> qu;//创建队列 qu.push(起始状态入队); while(!qu.empty()){//当队列非空 if(当前状态x方向可走) qu.push(当前状态->x);//该状态入队 if(当前状态向y方向可走) qu.push(当前状态->y);//该状态入队 ………………… 处理(队顶)qu.top(); 相应操作; qu.pop();//队首弹出队 }//一次循环结束,执行下一次循环 }
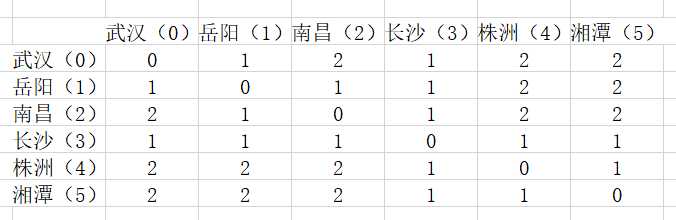
如此以来,我们就得到了整个图,每个节点的详细信息,可以根据需求进行更细节的操作。
这便是最短路的基本思想,当然,实际情况会更加复杂,比如边的权值各有不同,是有向边,出现负权值等情况,也会有相应的算法(迪特斯科拉,贝尔曼-福德,弗洛伊德,SPFA,A_Star等算法),同时,在图的遍历时,通过邻接矩阵我们也可以瞥见连通图的很多性质,优美的现象能吸引人的思考,数学之美就在于这些奇妙之处。
欧拉路
我们有目的性出行,肯定也有旅游出行,肯定有人喜欢欣赏沿途的风景,我举个例子,加入有一个岳阳人,他很喜欢看火车沿路的风景,他把以上6个城市作为了自己旅行可规划的目的地,他想在各个路线中穿梭,路线越长越好,但是他不喜欢看重复的风景,他想规划一个走过的路不重复,而且最长的路线。走过的路不重复,就是所谓的欧拉路。
因为我们着重考虑路径,所以使用之前判定有无直接连接的邻接矩阵就可以了,我们使用DFS来遍历所有边并找出最长的一条。
int g[N][N];//邻接矩阵2维数组 //默认邻接矩阵信息已经存入了该二维数组中 bool st[N][N];//标记某一条边是否被访问过 int ans;//存储答案 ? void dfs(int start, int res) { for (int i = 0; i < n; i++) { if (g[start][i] == 1 || st[start][i] || st[i][start]) //该边可以通过并且是第一次通过 continue; st[u][i] = st[i][u] = true;//标记 dfs(i, res + 1);//下一步 st[u][i] = st[i][u] = false;//回溯 } ans = max(ans, res);//保证得到最大的结果 }
欧拉(回)路问题其实就是经典的“一笔画问题”,应为我们每一步的判定和操作都是固定的,通过dfs的“自相性”我们往往能简洁而优美的解决这一系列问题。
为了继续思考图论的模型,我们接下来不使用代码讨论另外两种模型,这两种模型的代码模板很方便理解,了解了基本思路和模型,就很方便应用了。
并查集
我们都知道每个省有很多地放,现在随意给你两个市区的名称,想要你判断以下他们是否属于同一个省份。
我们将每个城市存入其数据结构,可以得出以下的情况
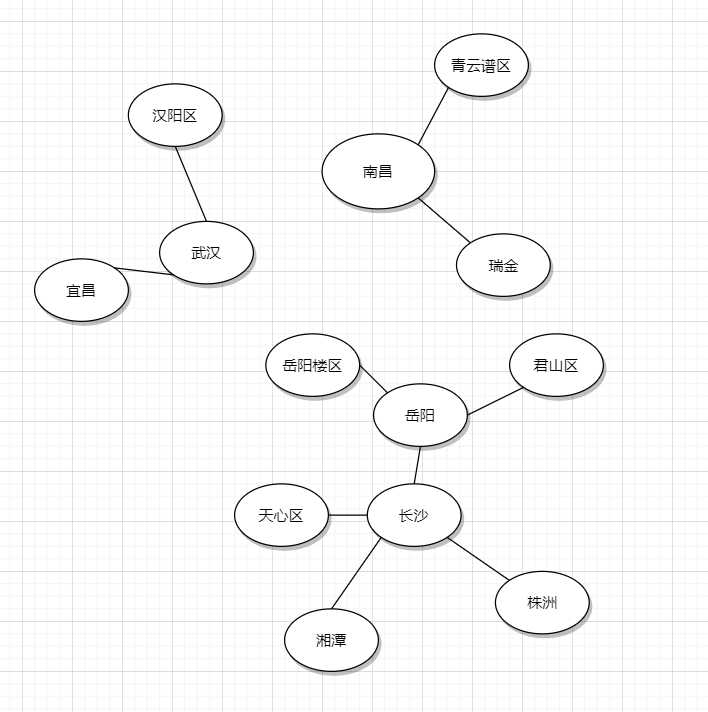
并查集的关键在于处理父子节点的关系,这样的数据架构可以处理大量的“集合合并”操作
最小生成树
再来一个例子,假设我们要再部分城市之间架设最新最快的交通轨道,为了使成本最低,现在要你选出一个方案,使架设的轨道线路最低:(现在我们给边附上权值)
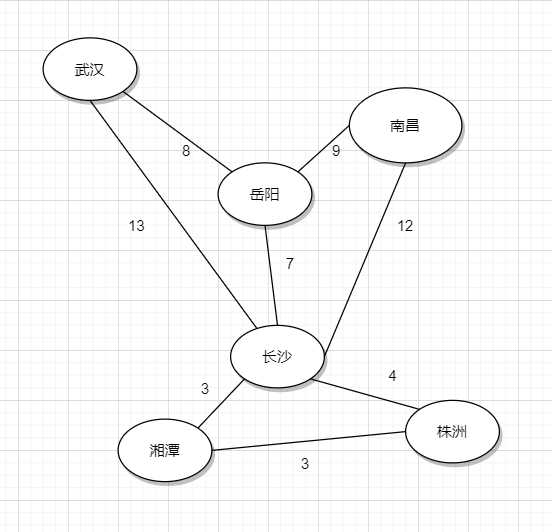
这样便是一个基础的无向图最小生成树问题,我们根据我们已经建立的关系,采用并查集的数据结构,采用Kruskal或者Prim算法的模板可以求出以下结果
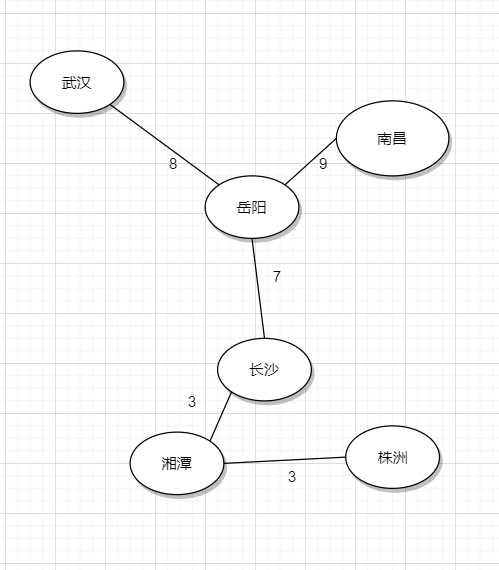
更多……
图论的问题和每一个节点的信息息息相关,而如何使用图论模型,关键在于如何定义“节点”。
关于这个问题,我很喜欢《算法图解》里的讲解方式——将“状态”转化为“信息”储存到“节点”里,每个状态是一个“节点”,状态变化的过程就是“边”。这便是连接实际问题和图论算法的桥梁,理解了这个思想,很多模型建立的困惑就能迎刃而解了,图论的其他问题基本都能通过这个思想来建模。
希望我的抛砖引玉能引起更多的思考! ?? (蒟蒻鞠躬)。
以上是关于小话数据结构-图 (聚焦与于实现的理解)的主要内容,如果未能解决你的问题,请参考以下文章