Elasticsearch 7.0 正式发布,盘他!
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch 7.0 正式发布,盘他!相关的知识,希望对你有一定的参考价值。
Elastic{ON}北京分享了Elasticsearch7.0在Speed,Scale,Relevance等方面的很多新特性。
比快更快,有传说中的那么牛逼吗?盘他!
通过本文,你能了解到:
Elasticsearch&Kibana 7.部署体验
Elasticsearch7 革命性更新
Elasticsearch 7升级注意事项
Elasticsearch 版本更新太快了,学不动了,肿么办?
1、Elasticsearch&Kibana 7.部署体验
1.1 Elasticsearch 7.0 默认自带 JDK
不用再为安装什么版本的 JDK和环境冲突而苦恼了,下载安装即可使用。
对比可知,包大了200MB+,正是JDK的大小。
在这里插入图片描述
1.2 默认节点名称为主机名。
不过仍然可以在elasticsearch.yml中显式配置。
实际业务场景中,以主机名区分不同节点比随机起名字更便于甄别,不易混淆。
1.3 默认分片数改为1,不再是5。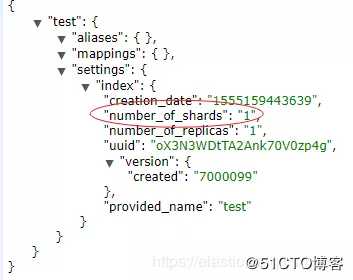
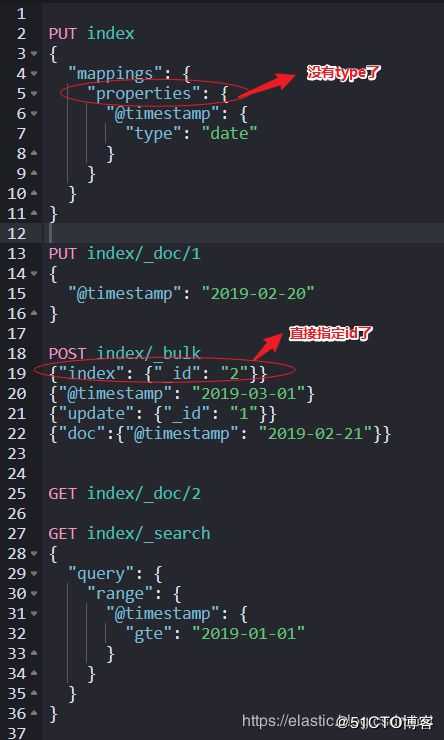
1.4 Elasticsearch 7.0 没有 Type 了,包括 API 层面的。
如下所示,确切的说,正确的使用方法,使用默认的_doc作为type就可以了。
type会在8.X版本彻底移除。
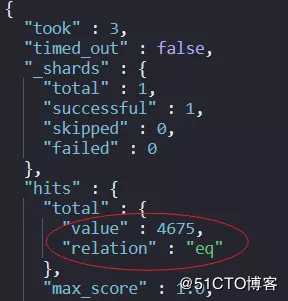
1.5 hits.total返回对象,而非仅结果值
现在,与搜索请求匹配的总命中数将作为具有值和关系的对象返回。
value表示匹配的匹配数,
关系表示值是准确的(eq)还是非准确的(gte)。
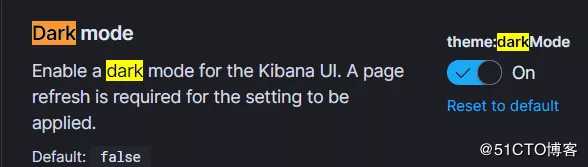
1.6 Kibana 支持全局开启“黑暗”模式
用户可以选择打开主题:Kibana->高级设置->dark Mode,而不是必须在很多地方打开黑暗模式,它将适用于所有应用程序。
2、Elasticsearch7 革命性更新
2.1 查询相关性速度优化
Weak-AND算法在Term Query查询场景有3700%的性能提升。
如下所示,除了Term检索,Fuzzy,Phrase, Bool And .Bool OR都有大幅的性能提升!
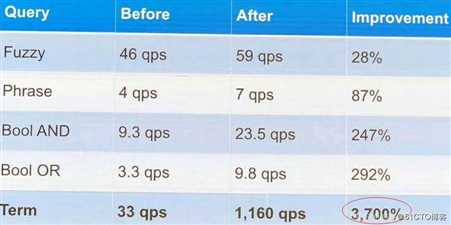
啥是weak-and算法?
核心原理:取TOP N结果集,估算命中记录数。
简单来说,一般我们在计算文本相关性的时候,会通过倒排索引的方式进行查询,通过倒排索引已经要比全量遍历节约大量时间,但是有时候仍然很慢。
原因是很多时候我们其实只是想要top n个结果,一些结果明显较差的也进行了复杂的相关性计算,
而weak-and算法通过计算每个词的贡献上限来估计文档的相关性上限,从而建立一个阈值对倒排中的结果进行减枝,从而得到提速的效果。
2.2 间隔查询(Intervals queries)
某些搜索用例(例如,法律和专利搜索)引入了查找单词或短语彼此相距一定距离的记录的需要。
Elasticsearch 7.0中的间隔查询引入了一种构建此类查询的全新方式,与之前的方法(跨度查询span queries)相比,使用和定义更加简单。
与跨度查询相比,间隔查询对边缘情况的适应性更强。
2.3 引入新的集群协调子系统
移除 minimum_master_nodes 参数,让 Elasticsearch 自己选择可以形成仲裁的节点。
典型的主节点选举现在只需要很短的时间就可以完成。
集群的伸缩变得更安全、更容易,并且可能造成丢失数据的系统配置选项更少了。
节点更清楚地记录它们的状态,有助于诊断为什么它们不能加入集群或为什么无法选举出主节点。
2.4 升级 Elasticsearch 7,0 ,不再内存溢出
新的 Circuit Breaker 在JVM 堆栈层面监测内存使用,Elasticsearch 比之前更加健壮。
设置indices.breaker.fielddata.limit的默认值已从JVM堆大小的60%降低到40%。
2.5 时间戳纳秒级支持,提升数据精度
利用纳秒精度支持加强时间序列用例
到目前为止,Elasticsearch仅以毫秒精度存储时间戳。 7.0增加了几个零并带来了纳秒精度,这提高了高频数据采集用户存储和排序所需数据的精度。
显然,7.0的特性远不止这些,更多新版本特性推荐阅读:
3、Elasticsearch 7升级注意事项
3.0 升级前必知必会
查看新版本的重大更改特性,并对7.0.0的代码和配置进行必要的更改。
如果您使用自定义插件,请确保兼容版本可用。
在升级生产集群之前,在开发环境中测试升级。
备份您的数据! 您必须拥有数据快照才能回滚到早期版本。
3.1 升级API
Rolling upgrade ——滚动升级允许Elasticsearch集群一次升级一个节点,升级不会中断服务。
不支持在升级期间在同一群集中运行多个版本的Elasticsearch,因为无法将已升级的节点复制到运行旧版本的节点。
3.2 版本升级路线
小版本之间升级:举例:5.4.1升级到5.6
平滑升级——从5.6版本到6.7版本
平滑升级——从6.7版本到7.0.0版本
3.3 借助Reindex升级索引数据
Elasticsearch可以读取在先前主要版本中创建的索引。如果您在5.x或之前创建了索引,则必须在升级到7.0.0之前重新索引或删除它们。
如果存在不兼容的索引,Elasticsearch节点将无法启动。
3.4 ELK Stack要一起升级
升级到新版本的Elasticsearch时,需要升级Elastic Stack中的每个产品。
3.5 6.6或更早版本集群,需要先关闭
要从6.6或更早版本直接升级到7.0.0,必须关闭群集,安装7.0.0并重新启动。
3.6 切记,7.0+版本无type的索引结构。
这点,如果考虑未来更新版本,在6.X或者更早版本的项目中,就严格按照7.x规范走,这样升级会相对比较省事。
4、Elasticsearch 版本更新太快了,学不动了,肿么办?
一方面,我们感叹ES的更新速度,的确从2016年的2.X到2019年的7.0,版本更新速度超乎想象。
另一方面,实际业务开发中,还在使用1.X,2.X,5.X,甚至还没有用过6.X的朋友非常多,小伙伴不禁有了“学不动了”的感慨。
4.1 新版本的变
变是永恒的,尤其是基于开源软件加上上市公司的推动。
实际上,高版本较低版本,主要在性能上的提升和部分新功能点的实现。
新版本更高效。
比如:6.6+提出的ilm索引生命周期管理,你如果关注Elastic Meetup的话,印象ebay和阿里还有其他公司自己就实现过类似功能。
原有版本有类似的功能,只不过是非常、非常麻烦、繁琐,所以,才有了ilm的诞生。
新版本迎合了市场的需求。
比如:7.0的黑暗模式,实际在grafana或类似竞品BI中都有类似的功能,猜测Kibana升级一方面是用户需求,另一方面也是竞品分析的结果。
新版本性能极大提升。
比如:7.0的terms融合新算法,有37倍的提升。
4.2 新版本的不变
《暗时间》作者刘未鹏说过“底层的技术永远不过时”。
不必说倒排索引机制不会变,也不必说Lucene的改动也相对较小。单是:ES的基础功能全文检索、多种聚合等几乎不会有太大的变动。
4.3 还存在学不动吗?
夯实打牢基础基本功,理解ELK更新的变与不变。80-90%+的时间关注基础,10%左右的时间关注增量的变化即可。
以不变应万变,方为生存之道!
参考:
以上是关于Elasticsearch 7.0 正式发布,盘他!的主要内容,如果未能解决你的问题,请参考以下文章
Volcano 社区 v1.7.0 版本正式发布 | 云原生批量计算
Volcano 社区 v1.7.0 版本正式发布 | 云原生批量计算
Elasticsearch 7.0:过滤 must_not 查询错误