PyTorch实现TPU版本CNN模型
Posted panchuangai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了PyTorch实现TPU版本CNN模型相关的知识,希望对你有一定的参考价值。
作者|DR. VAIBHAV KUMAR
编译|VK
来源|Analytics In Diamag
随着深度学习模型在各种应用中的成功实施,现在是时候获得不仅准确而且速度更快的结果。
为了得到更准确的结果,数据的大小是非常重要的,但是当这个大小影响到机器学习模型的训练时间时,这一直是一个值得关注的问题。
为了克服训练时间的问题,我们使用TPU运行时环境来加速训练。为此,PyTorch一直在通过提供最先进的硬件加速器来支持机器学习的实现。
PyTorch对云TPU的支持是通过与XLA(加速线性代数)的集成实现的,XLA是一种用于线性代数的编译器,可以针对多种类型的硬件,包括CPU、GPU和TPU。

本文演示了如何使用PyTorch和TPU实现深度学习模型,以加快训练过程。
在这里,我们使用PyTorch定义了一个卷积神经网络(CNN)模型,并在PyTorch/XLA环境中对该模型进行了训练。
XLA将CNN模型与分布式多处理环境中的Google Cloud TPU(张量处理单元)连接起来。在这个实现中,使用8个TPU核心来创建一个多处理环境。
我们将用这个PyTorch深度学习框架进行时装分类测试,观察训练时间和准确性。
用PyTorch和TPU实现CNN
我们将在Google Colab中实现执行,因为它提供免费的云TPU(张量处理单元)。
在继续下一步之前,在Colab笔记本中,转到“编辑”,然后选择“设置”,从下面屏幕截图中的列表中选择“TPU”作为“硬件加速器”。
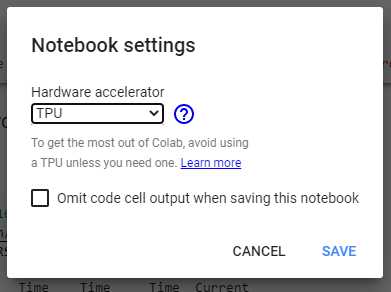
验证TPU下面的代码是否正常运行。
import os
assert os.environ[‘COLAB_TPU_ADDR‘]
如果启用了TPU,它将成功执行,否则它将返回‘KeyError: ‘COLAB_TPU_ADDR’’。你也可以通过打印TPU地址来检查TPU。
TPU_Path = ‘grpc://‘+os.environ[‘COLAB_TPU_ADDR‘]
print(‘TPU Address:‘, TPU_Path)
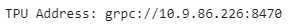
启用TPU后,我们将安装兼容的控制盘和依赖项,以使用以下代码设置XLA环境。
VERSION = "20200516"
!curl https://raw.githubusercontent.com/pytorch/xla/master/contrib/scripts/env-setup.py -o pytorch-xla-env-setup.py
!python pytorch-xla-env-setup.py --version $VERSION
一旦安装成功,我们将继续定义加载数据集、初始化CNN模型、训练和测试的方法。首先,我们将导入所需的库。
import numpy as np
import os
import time
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import torch_xla
import torch_xla.core.xla_model as xm
import torch_xla.debug.metrics as met
import torch_xla.distributed.parallel_loader as pl
import torch_xla.distributed.xla_multiprocessing as xmp
import torch_xla.utils.utils as xu
from torchvision import datasets, transforms
之后,我们将进一步定义需要的超参数。
# 定义参数
FLAGS = {}
FLAGS[‘datadir‘] = "/tmp/mnist"
FLAGS[‘batch_size‘] = 128
FLAGS[‘num_workers‘] = 4
FLAGS[‘learning_rate‘] = 0.01
FLAGS[‘momentum‘] = 0.5
FLAGS[‘num_epochs‘] = 50
FLAGS[‘num_cores‘] = 8
FLAGS[‘log_steps‘] = 20
FLAGS[‘metrics_debug‘] = False
下面的代码片段将把CNN模型定义为PyTorch实例,以及用于加载数据、训练模型和测试模型的函数。
SERIAL_EXEC = xmp.MpSerialExecutor()
class FashionMNIST(nn.Module):
def __init__(self):
super(FashionMNIST, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.bn1 = nn.BatchNorm2d(10)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.bn2 = nn.BatchNorm2d(20)
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = self.bn1(x)
x = F.relu(F.max_pool2d(self.conv2(x), 2))
x = self.bn2(x)
x = torch.flatten(x, 1)
x = F.relu(self.fc1(x))
x = self.fc2(x)
return F.log_softmax(x, dim=1)
# 只在内存中实例化一次模型权重。
WRAPPED_MODEL = xmp.MpModelWrapper(FashionMNIST())
def train_mnist():
torch.manual_seed(1)
def get_dataset():
norm = transforms.Normalize((0.1307,), (0.3081,))
train_dataset = datasets.FashionMNIST(
FLAGS[‘datadir‘],
train=True,
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), norm]))
test_dataset = datasets.FashionMNIST(
FLAGS[‘datadir‘],
train=False,
download=True,
transform=transforms.Compose(
[transforms.ToTensor(), norm]))
return train_dataset, test_dataset
#使用串行执行器可以避免多个进程下载相同的数据
train_dataset, test_dataset = SERIAL_EXEC.run(get_dataset)
train_sampler = torch.utils.data.distributed.DistributedSampler(
train_dataset,
num_replicas=xm.xrt_world_size(),
rank=xm.get_ordinal(),
shuffle=True)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=FLAGS[‘batch_size‘],
sampler=train_sampler,
num_workers=FLAGS[‘num_workers‘],
drop_last=True)
test_loader = torch.utils.data.DataLoader(
test_dataset,
batch_size=FLAGS[‘batch_size‘],
shuffle=False,
num_workers=FLAGS[‘num_workers‘],
drop_last=True)
# 调整学习率
lr = FLAGS[‘learning_rate‘] * xm.xrt_world_size()
# 获取损失函数、优化器和模型
device = xm.xla_device()
model = WRAPPED_MODEL.to(device)
optimizer = optim.SGD(model.parameters(), lr=lr, momentum=FLAGS[‘momentum‘])
loss_fn = nn.NLLLoss()
def train_fun(loader):
tracker = xm.RateTracker()
model.train()
for x, (data, target) in enumerate(loader):
optimizer.zero_grad()
output = model(data)
loss = loss_fn(output, target)
loss.backward()
xm.optimizer_step(optimizer)
tracker.add(FLAGS[‘batch_size‘])
if x % FLAGS[‘log_steps‘] == 0:
print(‘[xla:{}]({}) Loss={:.5f}‘.format(
xm.get_ordinal(), x, loss.item(), time.asctime()), flush=True)
def test_fun(loader):
total_samples = 0
correct = 0
model.eval()
data, pred, target = None, None, None
for data, target in loader:
output = model(data)
pred = output.max(1, keepdim=True)[1]
correct += pred.eq(target.view_as(pred)).sum().item()
total_samples += data.size()[0]
accuracy = 100.0 * correct / total_samples
print(‘[xla:{}] Accuracy={:.2f}%‘.format(
xm.get_ordinal(), accuracy), flush=True)
return accuracy, data, pred, target
# 训练和评估循环
accuracy = 0.0
data, pred, target = None, None, None
for epoch in range(1, FLAGS[‘num_epochs‘] + 1):
para_loader = pl.ParallelLoader(train_loader, [device])
train_fun(para_loader.per_device_loader(device))
xm.master_print("Finished training epoch {}".format(epoch))
para_loader = pl.ParallelLoader(test_loader, [device])
accuracy, data, pred, target = test_fun(para_loader.per_device_loader(device))
if FLAGS[‘metrics_debug‘]:
xm.master_print(met.metrics_report(), flush=True)
return accuracy, data, pred, target
现在,要将结果绘制为测试图像的预测标签和实际标签,将使用以下功能模块。
# 结果可视化
import math
from matplotlib import pyplot as plt
M, N = 5, 5
RESULT_IMG_PATH = ‘/tmp/test_result.png‘
def plot_results(images, labels, preds):
images, labels, preds = images[:M*N], labels[:M*N], preds[:M*N]
inv_norm = transforms.Normalize((-0.1307/0.3081,), (1/0.3081,))
num_images = images.shape[0]
fig, axes = plt.subplots(M, N, figsize=(12, 12))
fig.suptitle(‘Predicted Lables‘)
for i, ax in enumerate(fig.axes):
ax.axis(‘off‘)
if i >= num_images:
continue
img, label, prediction = images[i], labels[i], preds[i]
img = inv_norm(img)
img = img.squeeze() # [1,Y,X] -> [Y,X]
label, prediction = label.item(), prediction.item()
if label == prediction:
ax.set_title(u‘Actual {}/ Predicted {}‘.format(label, prediction), color=‘blue‘)
else:
ax.set_title(
‘Actual {}/ Predicted {}‘.format(label, prediction), color=‘red‘)
ax.imshow(img)
plt.savefig(RESULT_IMG_PATH, transparent=True)
现在,我们都准备好在MNIST数据集上训练模型。训练开始前,我们将记录开始时间,训练结束后,我们将记录结束时间并打印50个epoch的总训练时间。
# 启动训练流程
def train_cnn(rank, flags):
global FLAGS
FLAGS = flags
torch.set_default_tensor_type(‘torch.FloatTensor‘)
accuracy, data, pred, target = train_mnist()
if rank == 0:
# 检索TPU核心0上的张量并绘制。
plot_results(data.cpu(), pred.cpu(), target.cpu())
xmp.spawn(train_cnn, args=(FLAGS,), nprocs=FLAGS[‘num_cores‘],
start_method=‘fork‘)


一旦训练成功结束,我们将打印训练所用的总时间。
end_time = time.time()
print(‘Total Training time = ‘,end_time-start_time )
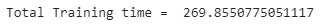
正如我们在上面看到的,这种方法花费了269秒或大约4.5分钟,这意味着50个epoch训练PyTorch模型不到5分钟。最后,我们将通过训练的模型来可视化预测。
from google.colab.patches import cv2_imshow
import cv2
img = cv2.imread(RESULT_IMG_PATH, cv2.IMREAD_UNCHANGED)
cv2_imshow(img)

因此,我们可以得出这样的结论:使用TPU实现深度学习模型可以实现快速的训练,正如我们前面所看到的那样。
在不到5分钟的时间内,对50个epoch的40000张训练图像进行了CNN模型的训练。我们在训练中也获得了89%以上的准确率。
因此,在TPU上训练深度学习模型在时间和准确性方面总是有好处的。
参考文献:
- Joe Spisak, “Get started with PyTorch, Cloud TPUs, and Colab”.
- “PyTorch on XLA Devices”, PyTorch release.
- “Training PyTorch models on Cloud TPU Pods”, Google Cloud Guides.
原文链接:https://analyticsindiamag.com/how-to-implement-cnn-model-using-pytorch-with-tpu/
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
以上是关于PyTorch实现TPU版本CNN模型的主要内容,如果未能解决你的问题,请参考以下文章