padans 关于数据处理的杂谈 -- 时序数
Posted cycxtz
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了padans 关于数据处理的杂谈 -- 时序数相关的知识,希望对你有一定的参考价值。
情况:业务数据基本字段会有如下:
Index([‘时间‘, ‘地区‘, ‘产品‘, ‘字段‘, ‘数值‘], dtype=‘object‘)
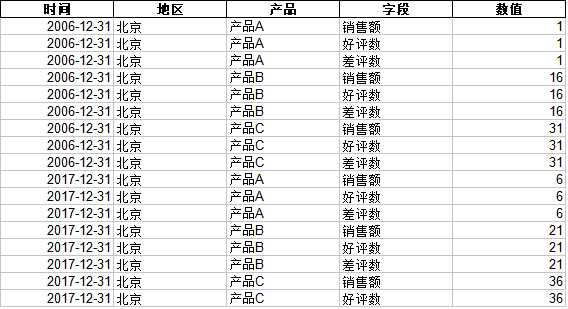
这样就会引发一个经典“三角不可能定理”,如何同时简约展现分时序、分产品、分字段数据。)一般来说,
1、时序为作为单独的分类,
2、然后剩下两个标签就是,要么:
2.1、每个字段一张表,然后列为时序,行为产品
2.2、要么每个产品一张表,列为时序,行为产品。
2.3、要么将“产品”、“字段”组成新的列。
那么实现2.1、2.2,不过这样的瓶颈就是,如果有很多个字段,则会组合成很多张表。
# 使用数据透视表,假设现在,逐字段,分产品时序 # 获取所有产品,去重 cp = df[‘产品‘].to_frame().drop_duplicates(subset=[‘产品‘]) # 得到 3个 工作表,每个工作表为相关字段的分产品分时序,这样一来,如果涉及很多个字段,则会有很多个表 with pd.ExcelWriter(‘data/test2-shuchu.xls‘) as writer: for zd in df[‘字段‘].unique(): table = pd.pivot_table(df[df[‘字段‘] == zd], values=‘数值‘, index=[‘产品‘],columns=[‘时间‘], aggfunc=np.sum) table = pd.merge(cp,table,how=‘left‘,on=‘产品‘) table.to_excel(writer,index=False,sheet_name = zd)
实现2.3
# 通过将 产品 字段 组合为一个,形成二维表 with pd.ExcelWriter(‘data/test2-shuchu2.xls‘) as writer: table = pd.pivot_table(df, values=‘数值‘, index=[‘产品‘,‘字段‘],columns=[‘时间‘], aggfunc=np.sum) table.reset_index().to_excel(writer,index=False,sheet_name = zd)
输出一张工作表即可。
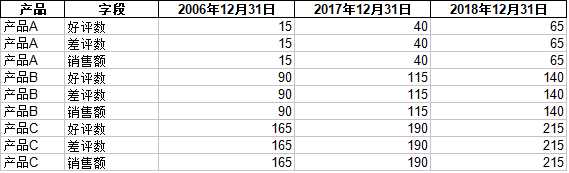
有时还需要处理成,具有环比、比年初、同比等值。则采取给源数据增加字段。
先通过类似方法给源数据增加一个比去年同期列
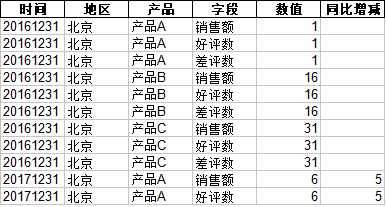
def add_year_on_year(x): d = ‘‘ if x[‘时间‘] == ‘20161231‘: return None elif x[‘时间‘] == ‘20171231‘: d = ‘20161231‘ elif x[‘时间‘] == ‘20181231‘: d = ‘20171231‘ # 获取相应的数值 v = df[(df[‘时间‘] == d) & (df[‘地区‘] == x[‘地区‘]) & (df[‘产品‘] == x[‘产品‘]) & (df[‘字段‘] == x[‘字段‘])] #print(‘d:‘,d) if len(v) == 0: return x[‘数值‘] else: return x[‘数值‘] - v.iloc[0][‘数值‘] df[‘同比增减‘] = df.apply(add_year_on_year,axis=1) with pd.ExcelWriter(‘data/test2-huanyuan-add.xls‘) as writer: df.to_excel(writer,index=False,sheet_name = ‘Sheet1‘)
输出如下:
最后在再把数据打回stack,再执行数据透视表操作
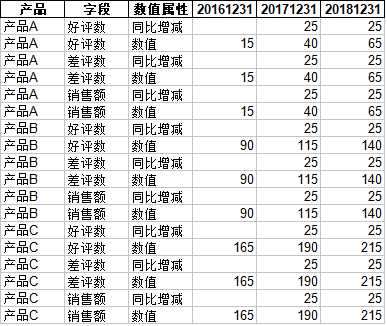
df2 = df.set_index([‘时间‘, ‘地区‘, ‘产品‘,‘字段‘]) df2 = df2.stack() df2 = df2.reset_index() with pd.ExcelWriter(‘data/test2-huanyuan2.xls‘) as writer: df2.to_excel(writer,index=False,sheet_name = ‘Sheet1‘) df2.rename(columns={‘level_4‘:‘数值属性‘,0:‘数值‘},inplace=True) # 通过将 产品 字段 组合为一个,形成二维表 with pd.ExcelWriter(‘data/test2-shuchu3.xls‘) as writer: table = pd.pivot_table(df2, values=‘数值‘, index=[‘产品‘,‘字段‘,‘数值属性‘],columns=[‘时间‘], aggfunc=np.sum) table.reset_index().to_excel(writer,index=False,sheet_name = ‘h‘)
最终输出:
以上是关于padans 关于数据处理的杂谈 -- 时序数的主要内容,如果未能解决你的问题,请参考以下文章