Elasticsearch实战 | 如何从数千万手机号中识别出情侣号?
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch实战 | 如何从数千万手机号中识别出情侣号?相关的知识,希望对你有一定的参考价值。
1、问题描述
您好,请教个问题。我现在有2千多万的手机号码信息保存在es里。5个分片,3个节点。
现在的需求是将后八位相同的号码匹配到一起,重新放到一个index里。组成情侣号。方便后续查询情侣号列表。
我目前的做法是用scroll查询出一万条,多线程循环一万条中的每条,去全库扫描---但是这种做法一分钟才能处理一万条。您有什么新的思路没。
死磕Elasticsearch知识星球 https://t.zsxq.com/Iie66qV
问题补充:索引存储了手机号,同时存储了插入时间。
2、问题分析
2.1 情侣号的定义
后八位相同的号码即为情侣号。
举例:
13011112222
13511112222
13711112222
2.2 如何对后8位建立索引,以方便后续的识别?
方案一 不单独建索引,用script来实现
缺点:script效率低一些
方案二:写入数据的时候,同时基于后八位创建新的字段。
2.3 8位相同的号码匹配到一起,重新放到一个index里怎么实现?
Elasticsearch自带reindex功能就是实现索引迁移的,当然自定义读写也可以实现。
方案一:遍历方式+写入。
步骤 1:基于时间递增循环遍历,以起始的手机号为种子数据,满足后八位相同的加上标记flag=1。
步骤 2:循环步骤1,满足flag=1直接跳过,直到所有手机号遍历一遍。
步骤 3:将包含flag=1的字段,reindex到情侣号索引。
方案二:聚合出情侣号组,将聚合结果reindex到情侣号索引。
考虑到数据量级千万级别,全量聚合不现实。
可以,基于时间切片,取出最小时间戳、最大时间戳,根据数据总量和时间范围划分出时间间隔。
举例:以30分钟为单位切割千万级数据。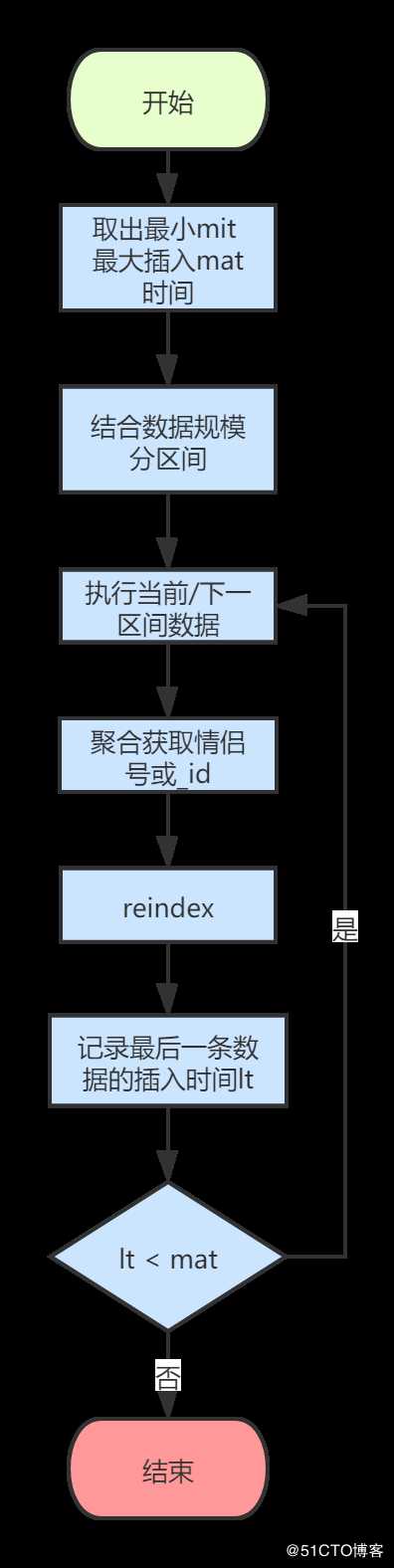
步骤 1:terms聚合后8位手机号。
terms聚合只返回对应:key,value值,默认value值由高到低排序。
key:代表手机号后8位,value:代表相同后8位的数据量。
步骤 2:top_hits子聚合取出手机号详情。
步骤 3:json解析识别出步骤2的所有手机号或_id。
步骤 4:reindex步骤3的_id数据到情侣号索引。
步骤 5:时间切片周期递增,直到所有数据遍历完毕。
2.4 扩展自问:手机号怎么存,才能查出来后8位?
举例:查询“11112222”,返回2.1列表的三个手机号。
方案1:wildcard模糊匹配。
优点:无需额外字段存储。
缺点:效率低。
方案2:ngram分词+match_phrase处理。
优点:效率高。
缺点:需要独立存储的后8位字段。
3、实战一把
3.1 数据建模
3.1.1 字段设计
只包含非业务的有效必要字段。
(1)插入时间戳字段 insert_time, date类型。
由:ingest默认生成,不手动添加,提高效率。
(2)手机号字段 phone_number, text和keyword类型。
text类型基于ngram分词,主要方便phone_number全文检索。
keyword类型方便:排序和聚合使用。
(3)后8位手机号字段 last_eight_number, keyword类型。
只聚合和排序用,不检索。
3.1.2 ingest处理初始化数据先行
ingest pipeline的核心功能可以理解为写入前数据的ETL。
而:insert_time可以自动生成、last_eight_number可以基于phone_number提取。
定义如下:
0.create ingest_pipeline of insert_time and last_eight_number
PUT _ingest/pipeline/initialize
{
"description": "Adds insert_time timestamp to documents",
"processors": [
{
"set": {
"field": "_source.insert_time",
"value": "{{_ingest.timestamp}}"
}
},
{
"script": {
"lang": "painless",
"source": "ctx.last_eight_number = (ctx.phone_number.substring(3,11))"
}
}
]
}
3.1.3 模板定义
两个索引:
索引1:phone_index,存储全部手机号(数千万)
索引2:phone_couple_index,存储情侣号
由于两索引Mapping结构一样,使用模板管理会更为方便。
定义如下:
1.create template of phone_index and phone_couple_index
PUT _template/phone_template
{
"indexpatterns": "phone*",
"settings": {
"number_of_replicas": 0,
"index.default_pipeline": "initialize",
"index": {
"max_ngram_diff": "13",
"analysis": {
"analyzer": {
"ngram_analyzer": {
"tokenizer": "ngram_tokenizer"
}
},
"tokenizer": {
"ngram_tokenizer": {
"token_chars": [
"letter",
"digit"
],
"min_gram": "1",
"type": "ngram",
"max_gram": "11"
}
}
}
}
},
"mappings": {
"properties": {
"insert_time":{
"type":"date"
},
"last_eight_number":{
"type":"keyword"
},
"phone_number": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
},
"analyzer": "ngram_analyzer"
}
}
}
}
3.1.4 索引定义
PUT phone_index
PUT phone_couple_index
3.2 数据写入
采用模拟数据,实际业务会有所区别。
POST phone_index/_bulk
{"index":{"_id":1}}
{"phone_number" : "13511112222"}
{"index":{"_id":2}}
{"phone_number" : "13611112222"}
{"index":{"_id":3}}
{"phone_number" : "13711112222"}
{"index":{"_id":4}}
{"phone_number" : "13811112222"}
{"index":{"_id":5}}
{"phone_number" : "13844248474"}
{"index":{"_id":6}}
{"phone_number" : "13866113333"}
{"index":{"_id":7}}
{"phone_number" : "15766113333"}
模拟数据显示,有两组情侣号。
第一组情侣号尾数:“11112222”
第二组情侣号尾数:“66113333”
3.2 数据聚合
如前所述,聚合的目的是:提取出情侣号(>=2)的手机号或对应id。
GET phone_index/_search
{
"size": 0,
"query": {
"range": {
"insert_time": {
"gte": 1584871200000,
"lte": 1584892800000
}
}
},
"aggs": {
"last_aggs": {
"terms": {
"field": "last_eight_number",
"min_doc_count": 2,
"size": 10,
"shard_size": 30
},
"aggs": {
"sub_top_hits_aggs": {
"top_hits": {
"size": 100,
"_source": {
"includes": "phone_number"
},
"sort": [
{
"phone_number.keyword": {
"order": "asc"
}
}
]
}
}
}
}
}
}
注意:
查询的目的:按时间间隔取数据。原因:「聚合全量性能太差」。
外层聚合last_aggs统计:情侣号分组及数量。
内层子聚合sub_top_hits_aggs统计:下钻的手机号或_id等信息。
min_doc_count作用:聚合后的分组记录最小条数,情侣号必须>=2,则设置为2。
3.4 数据迁移
基于3.3 取出的满足条件的id进行跨索引迁移。
POST _reindex
{
"source": {
"index": "phone_index",
"query": {
"terms": {
"_id": [
1,
2,
3,
4,
6,
7
]
}
}
},
"dest": {
"index": "phone_couple_index"
}
}
注意:实际业务需要考虑数据规模,划定轮询时间间隔区间。
建议:按照2.3章节的流程图执行。
4、方案进一步探究
第3节的实战一把实际是基于基础数据都写入ES了再做的处理。
核心的操作都是基于Elasticsearch完成的。
试想一下,这个环节如果提前是不是更合理呢?
数据图如下所示: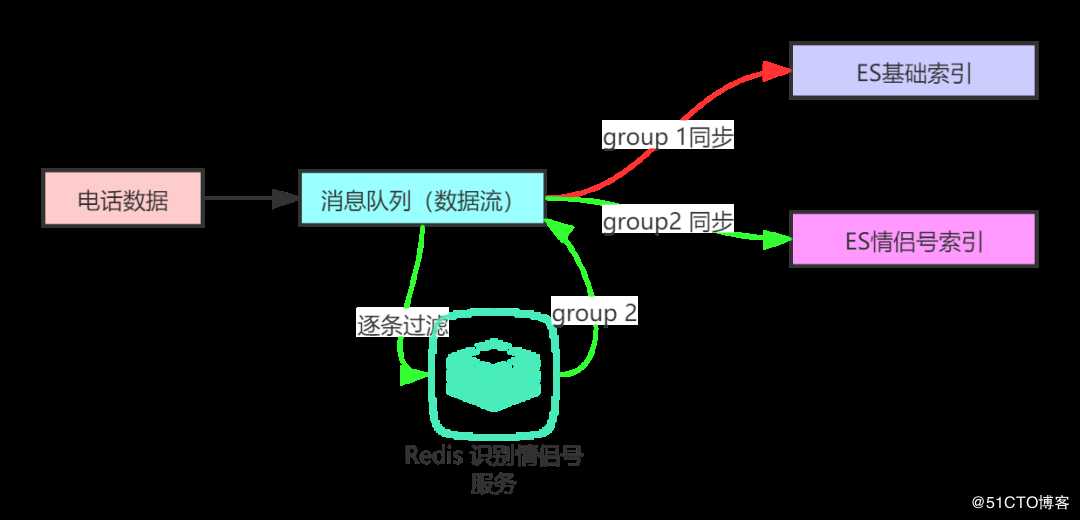
电话数据信息写入消息队列(如:kafka、rocketmq、rabbitmq等)。
消息队列可以直接同步到ES的phone_index索引。如:红线所示。
情侣号的处理借助第三方redis服务实现,逐条过滤,满足条件的数据同步到ES的情侣号索引phone_couple_index。如:绿线所示。
这样,Elasticsearch只干它最擅长的事情,剩下的工作前置交给消息队列完成。
5、小结
本文就提出问题做了详细的阐述和实践,用到Elasticsearch 模板、Ingest、reindex等核心知识点和操作,给线上业务提供了理论参考。
大家对本文有异议或者有更好的方案,欢迎留言交流。
以上是关于Elasticsearch实战 | 如何从数千万手机号中识别出情侣号?的主要内容,如果未能解决你的问题,请参考以下文章
《从Lucene到Elasticsearch:全文检索实战》学习笔记四
ElasticSearch分布式搜索引擎从入门到实战应用(实战篇-仿京东首页搜索商品高亮显示)