数据分析-机器学习面试题
Posted ucasljq
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据分析-机器学习面试题相关的知识,希望对你有一定的参考价值。
1.数据处理时缺失指怎么处理
2.L1和L2的区别
3.高维数据如何降维
4.特征处理,连续型和非连续性,给了个例子,年龄和user_id两个特征如何处理
5.LR了解吗,如何解决过拟合问题
6.如何评估模型结果,我把分类和回归分别解释,介绍各种评估方式的不足,还问了ROC曲线横纵坐标
7.Random Forest & GBDT 的区别, max depth哪个倾向于更深一点
8.Logistic regression 的Loss Function是什么,为什么不用和LR一样的loss
9.如何预测今年12月底的每日投稿量(如何建模,需要用什么数据)
10.逻辑回归拟合的好坏怎么看,ROC的横轴纵轴是什么
(1)直接对模型的拟合优劣进行检验(2)对模型的一个或者几个参数进行显著性检验
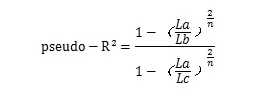
如图所示,La 表示系数β似然最大时的似然方程最大值;Lb表示截距似然最大时的似然方程最大值;Lc表示La的理论最大值,等于1。这就是拟合优度,越接近1代表模型拟合优度越好。
横轴:FPR 纵轴:TPR
11.决策树熟悉吗?过拟合怎么办?逻辑回归过拟合怎么办?
决策树结构:根部节点+非叶子节点(测试条件)+分支(测试结果)+叶子节点(分类后的分类标记)
优点:速度快,准确度高,可处理连续和离散变量,无需参数假设,可处理高维数据(特征值较多的数据)
缺点:容易过拟合,忽略了属性之间的相关性
减缓过拟合:缩小树结构的规模
逻辑回归过拟合解决:
1)减少特征值
2)特征值数量不变的情况下,引入正则化惩罚项,缩小最适参数的值
12.你觉得数据分析和算法有什么区别
数据挖掘就是从海量数据中找到隐藏的规则,数据分析一般要分析的目标比较明确。
有一些人总是不及时向电信运营商缴钱,如何发现它们?
数据分析:通过对数据的观察,我们发现不及时缴钱人群里的贫困人口占82%。所以结论是收入低的人往往会缴费不及时。结论就需要降低资费。
数据挖掘:通过编写好的算法自行发现深层次的原因。原因可能是,家住在五环以外的人,由于环境偏远不及时缴钱。结论就需要多设立一些营业厅或者自助缴费点,普及网络缴费
13.准确率和召回率的定义
准确率precision:查准率,预测为正样本的样本中,真正为正样本的占比
召回率recall:查全率=真正率,真正为正样本的样本中,预测正确的有多少
14.梯度下降有了解吗
15.讲一下交叉验证
CV是用来验证分类器的性能一种统计分析方法,基本思想是把在某种意义下将原始数据(dataset)进行分组,一部分做为训练集(train set),另一部分做为验证集(validation set),首先用训练集对分类器进行训练,在利用验证集来测试训练得到的模型(model),以此来做为评价分类器的性能指标.
16.smote过采样做法,会出现什么问题
1)过采样单纯重复了正例(少例),可能放大噪声,风险是过拟合。
2)欠采样抛弃了大部分反例(多例),浪费数据,模型偏差较大。另一种做法是反复欠采样,把多例分成不重叠的N份,分别与少例组合,训练N个模型,然后组合。缺点是训练多个模型开销大,组合时可能有额外错误,少例被反复利用,风险是过拟合。
3)SMOTE相较于一般的过采样,降低了过拟合,是soft 过采样,抗噪能力强,缺点是运算开销大,可能会生成异常点。
17.过采样,一个样本点复制多次会导致的问题
过采样对少数类样本进行了多次复制, 扩大了数据规模, 增加了模型训练的复杂度, 同时也容易造成过拟合
以上是关于数据分析-机器学习面试题的主要内容,如果未能解决你的问题,请参考以下文章