KNNImputer:一种可靠的缺失值插补方法
Posted panchuangai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了KNNImputer:一种可靠的缺失值插补方法相关的知识,希望对你有一定的参考价值。
作者|KAUSHIK
编译|VK
来源|Analytics Vidhya
概述
-
学会用KNNImputer来填补数据中的缺失值
-
了解缺失值及其类型
介绍
scikit learn公司的KNNImputer是一种广泛使用的缺失值插补方法。它被广泛认为是传统插补技术的替代品。
在当今世界,数据是从许多来源收集的,用于分析、产生见解、验证理论等等。从不同的资源收集的这些数据通常会丢失一些信息。这可能是由于数据收集或提取过程中的问题导致的,该问题可能是人为错误。
处理这些缺失值,成为数据预处理中的一个重要步骤。插补方法的选择至关重要,因为它会对工作产生重大影响。
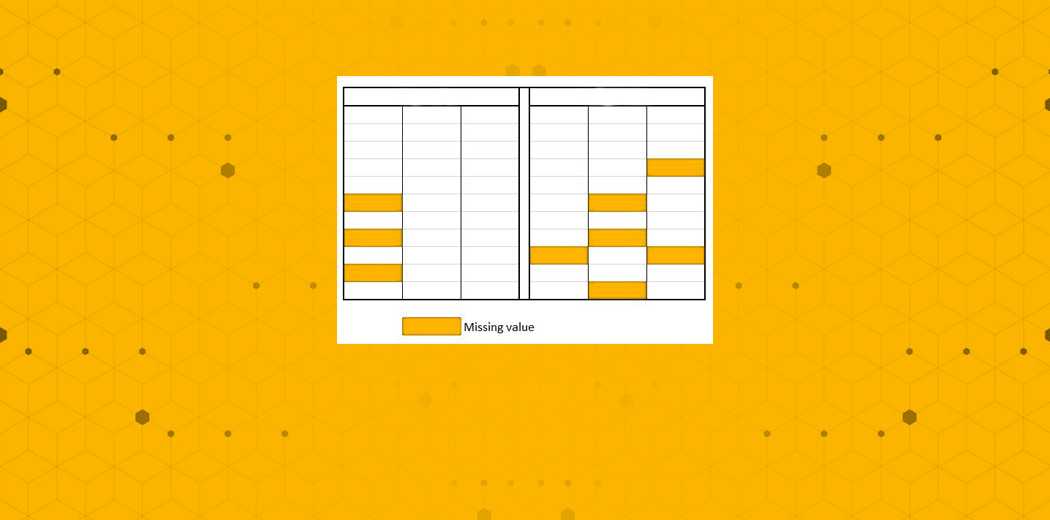
大多数统计和机器学习算法都是针对数据集的完整观测。因此,处理丢失的信息变得至关重要。
统计学中的一些文献涉及缺失值的来源和克服这个问题的方法。最好的方法是用估计值来估算这些缺失的观测值。
在本文中,我们介绍了一个使用相邻数据点的观测值来填充数据集中缺失值的指南。为此,我们使用scikit-learn的KNNImputer实现。
目录
-
自由度问题
-
缺失值模式
-
kNN算法的本质
-
存在缺失值时的距离计算
-
KNNImputer插补方法
自由度问题
对于任何数据科学家来说,数据集中缺失的值都可能是一个马蜂窝。缺失值的变量可能是一个非常重要的问题,因为没有简单的方法来处理它们。
一般来说,如果数据中缺失观测值的比例相对于观测值总数很小,我们可以简单地删除这些观测值。
然而,这种情况并不常见。删除包含缺失值的行可能会导致放弃有用的信息。
从统计学的角度来看,随着独立信息条数的减少,自由度降低。
缺失值模式
对于真实的数据集,缺失值是一个令人担忧的原因。收集有关变量的观察值时,可能会由于以下各种原因而丢失值
-
机器/设备中的错误
-
研究者的错误
-
无法联系的受访者
-
意外删除
-
部分受访者健忘
-
会计差错等。
缺失值的类型通常可分为:
完全随机缺失(MCAR)
当缺失的值对任何其他变量或观察值的任何特征没有隐藏的依赖性时,就会发生这种情况。如果医生忘记记录每10个进入ICU的病人的年龄,缺失值的存在并不取决于病人的特征。
随机缺失(MAR)
在这种情况下,丢失值的概率取决于可观测数据的特征。在调查数据中,高收入受访者不太可能告知研究人员拥有的房产数量。所拥有房产的可变数量的缺失值将取决于收入变量。
非随机缺失(MNAR)
当缺失的值既取决于数据的特征,也取决于缺失的值时,就会发生这种情况。在这种情况下,很难确定缺失值的生成机制。例如,血压等变量的缺失值可能部分取决于血压值,因为低血压患者不太可能经常检查血压。
kNN算法的本质
用于缺失值插补的单变量方法是估计值的简单方法,可能无法始终提供准确的信息。
例如,假设我们有与道路上汽车密度和空气中污染物水平相关的变量,并且几乎没有关于污染物水平的观察结果,用均值或者中位数污染物水平来估算污染物水平可能不一定是一个合适的策略。
在这种情况下,像k-最近邻(kNN)这样的算法可以帮助对缺失数据的值进行插补。
社会学家和社区研究人员认为,人类之所以生活在一个社区中,是因为邻居们产生了一种安全感、对社区的依恋感以及通过参与各种活动而产生社区认同感的人际关系。
对数据起作用的一种类似的插补方法是k-最近邻(kNN),它通过距离测量来识别相邻点,并且可以使用相邻观测值的完整值来估计缺失值。
例子
假设你家里的必需食品已经没有存货了,由于封锁,附近的商店都没有营业。因此,你向你的邻居寻求帮助,你最终会接受任何他们提供给你的东西。
这是一个来自3-NN的插补示例。
相反,如果你确定了3个向你寻求帮助的邻居,并选择将3个离你最近的邻居提供的物品组合在一起,这就是3-NN的插补示例。
类似地,数据集中的缺失值可以借助数据集中k近邻的观察值来推算。数据集的邻近点通过一定的距离度量来识别,通常是欧氏距离。
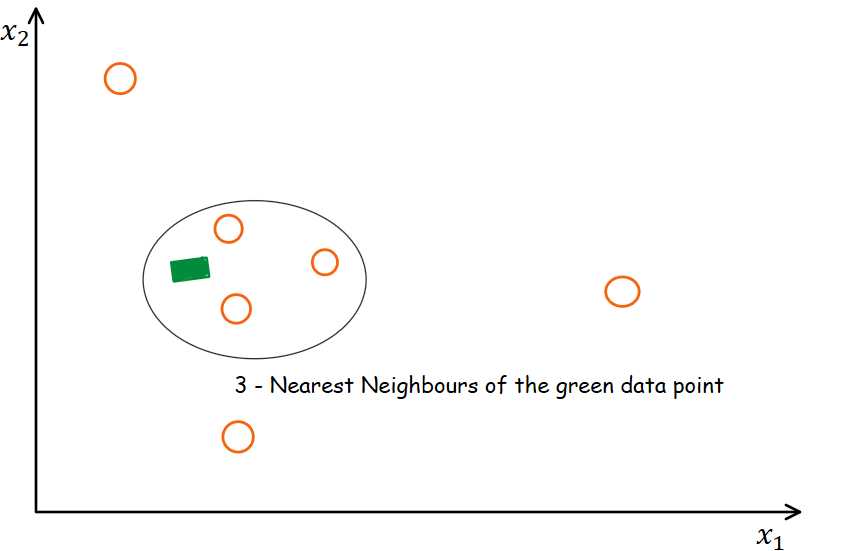
考虑一下上面表示kNN工作的图。在本例中,椭圆形区域表示绿色方形数据点的相邻点。我们用距离来确定邻居。
kNN方法的思想是在数据集中识别空间相似或相近的k个样本。然后我们使用这些“k”样本来估计缺失数据点的值。每个样本的缺失值使用数据集中找到的“k”邻域的平均值进行插补。
存在缺失值时的距离计算
让我们看一个例子来理解这一点。考虑二维空间(2,0)、(2,2)、(3,3)中的一对观测值。这些点的图形表示如下:
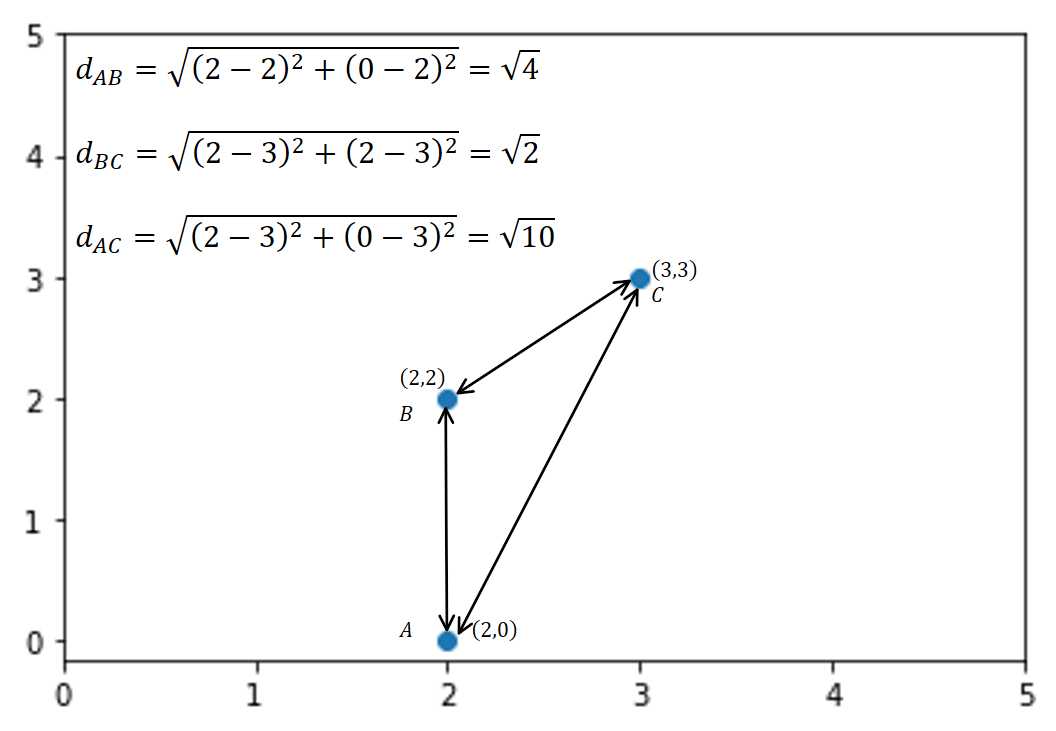
基于欧氏距离的最短距离点被认为是最近邻点。例如,点A的1最近邻点是点B。对于点B,1最近邻点是点C。
在存在缺失坐标的情况下,通过忽略缺失值并放大非缺失坐标的权重来计算欧几里德距离。
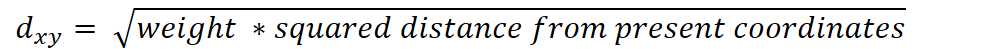
其中
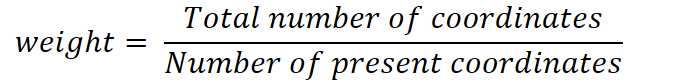
例如,两点(3,NA,5)和(1,0,0)之间的欧几里德距离为:
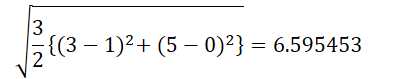
现在我们使用sklearn包pairwise metric模块中的nan_euclidean_distances 函数来计算缺失值两点之间的距离。

尽管nan_euclidean_distances 适用于由X和Y参数提供的两个一维数组,但它也可以适用于具有多个维度的单个数组。

因此,距离矩阵是一个2×2矩阵,它表示观测对之间的欧几里德距离。此外,合成矩阵的对角线元素为0,因为它表示单个观测值与其自身之间的距离。
KNNImputer插补方法
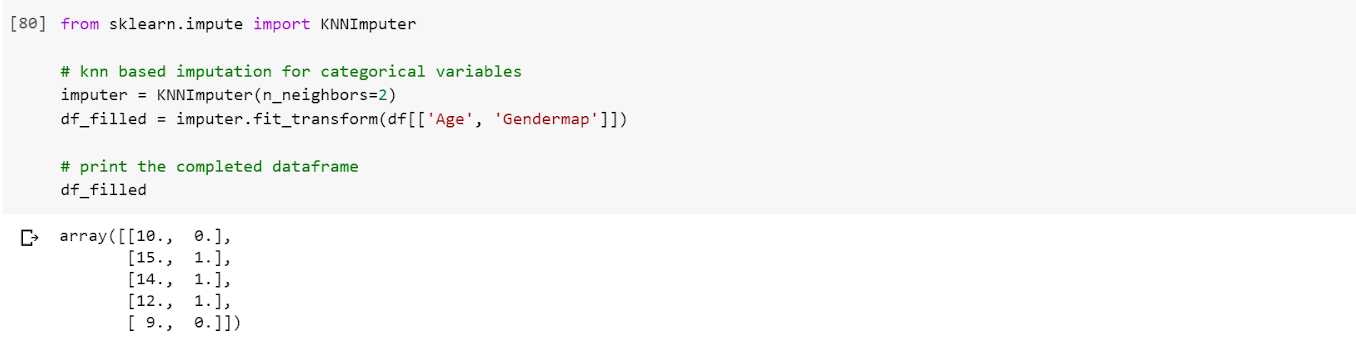
我们将使用sklearn的impute 模块中的KNNImputer 函数。KNNImputer通过欧几里德距离矩阵寻找最近邻,帮助估算观测中出现的缺失值。

在这种情况下,上面的代码显示观测1(3,NA,5)和观测3(3,3,3)在距离上最接近(~2.45)。
因此,用一个1-最近邻对观测值1(3,NA,5)中的缺失值进行插补,得到的估计值为3,与观测值3(3,3,3)的第二维度的估计值相同。
此外,用一个2-最近邻来估算观测值1(3,NA,5)中的缺失值将得到1.5的估计值,这与观测值2和3的第二维度的平均值相同,即(1,0,0)和(3,3,3)。

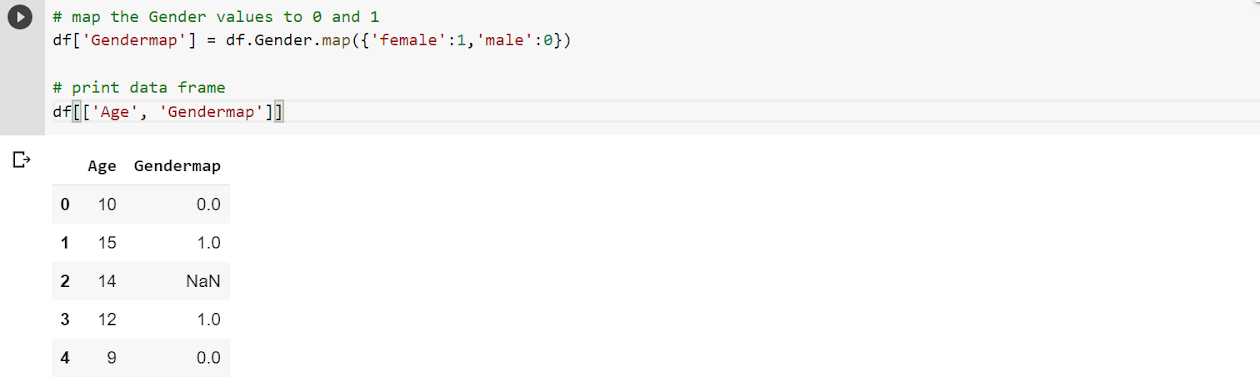
到目前为止,我们讨论了用KNNImputer处理连续变量的缺失值。下面,我们创建一个数据框,其中包含离散变量中缺少的值。
为了填补离散变量中的缺失值,我们必须将离散值编码成数值,因为KNNImputer只对数值变量有效。我们可以使用类别到数值变量的映射来执行此操作。

结尾
在本文中,我们了解了缺失值、原因,以及如何使用KNNImputer 来填充缺失值。选择k来使用kNN算法来填充缺失值可能是争论的焦点。
此外,研究表明,在使用不同k值进行插补后,有必要使用交叉验证来检验模型。尽管缺失值的插补是一个不断发展的研究领域,但kNN是一种简单而有效的策略。
欢迎关注磐创AI博客站:
http://panchuang.net/
sklearn机器学习中文官方文档:
http://sklearn123.com/
欢迎关注磐创博客资源汇总站:
http://docs.panchuang.net/
以上是关于KNNImputer:一种可靠的缺失值插补方法的主要内容,如果未能解决你的问题,请参考以下文章