The option-critic architecture(下)
Posted codonu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了The option-critic architecture(下)相关的知识,希望对你有一定的参考价值。
Experiments
我们首先考虑四个房间域中的导航任务(Sutton、Precup和Singh 1999)。我们的目标是评估一组完全自主学习的option从环境的突然变化中恢复过来的能力。(Sutton,Precup,and Singh 1999)对一组预先指定的选项提出了一个类似的实验;我们的结果中的选项并不是事先指定的。
最初目标位于 east doorway ((G1)),初始状态从所有其他单元统一绘制。 1000episode之后,目标移动到右下角房间的一个随机位置。
原始移动可能以1/3的概率失败,在这种情况下,代理会随机过渡到一个空的相邻单元。折扣系数为0.99,进球时奖励为+1,否则奖励为0。
与(Sutton,1999)设置相同,另(gamma=0.99)
我们选择用Boltzmann分布参数化intra-option策略,用sigmoid函数参数化终止策略。
使用intra-optionQ学习方法学习了options上的策略(high level)。
我们还使用Boltzmann策略实现了原始的actor-critic(表示为AC-PG)。
我们还比较了option-critic和使用Boltzmann exploration和没有eligibility trace的原始的SARSA agent。对于所有的Boltzmann策略,我们将温度参数设置为0.001。所有的权重都被初始化为零。
Boltzmann分布:
Boltzmann策略:
temperature parameter:
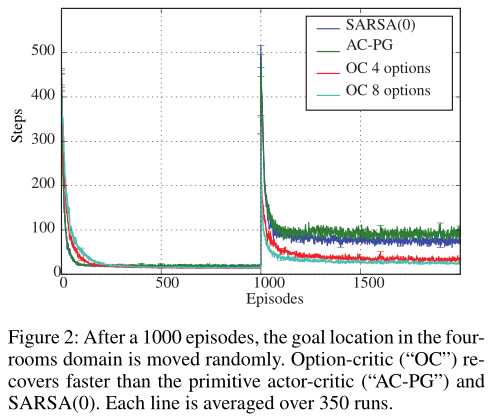
如图2所示,当目标突然改变时,Option-Critic agent恢复得更快。此外,初始的选项集是从零开始学习的速度可与原始方法相媲美。尽管这个领域很简单,但我们还没有发现其他方法可以在不产生比单独使用原始操作时更大的成本的情况下解决这个任务(McGovern和Barto 2001;S?ims?ek和Barto 2009)。
在有4个option和8个option的两个临时扩展设置中,终止事件更可能发生在门口附近(图3),这与直觉一致,即它们是好的子目标。与(Sutton,Precup,and Singh 1999)相反,我们自己并没有对这些知识进行编码,而是让agent找到能够最大化expected discounted return的option。
Pinball Domain
在弹球领域(Konidaris and Barto 2009),球必须通过一个任意形状的多边形迷宫引导到指定的目标位置。状态空间在xy平面上球的位置和速度是连续的。在每一步,代理必须在五个离散的基本动作中进行选择:更快或更慢地移动球,在垂直或水平方向上,或采取null action。与障碍物的碰撞是弹性的,可以利用agent的优势。在这个环境中,当重复选择不动作时,0.995的阻力系数有效地阻止了球在有限步数后的运动。每一个动作都会受到?5的惩罚,而不采取任何行动的代价是?1。当agent到达目标时,该事件将以+10000奖励结束。我们中断了超过10000episode的任何episode,并将折扣系数设置为0.99。
我们在critic中使用了intra-option的Q-学习,在 order 3 的 Fourier base上使用线性函数逼近(Konidaris et al.2011)。
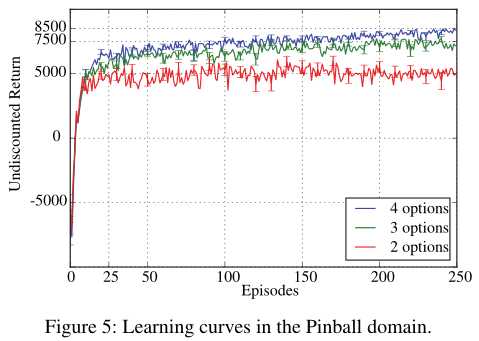
我们尝试了2,3或4个option。我们使用Boltzmann策略作为intra-option策略,线性sigmoid函数用于终止函数。critic的学习率设为0.01,内部和终止梯度的学习率设为0.001。我们在期权上使用了epsilon-greedy政策,(epsilon=0.01)。
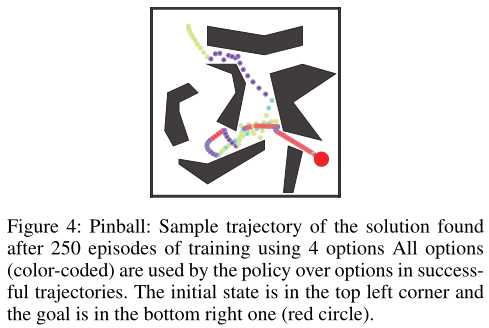
在(Konidaris and Barto 2009)中,只有在gestation为10期后才可以使用和更新option。由于学习是完全整合在选项评论家,到40集,一个近乎最佳的option集合已经学习在所有的设置。从定性的角度来看,这些option表现出时间上的扩展和专门化(图4)。我们还观察到,在许多成功的轨迹中,红色option将始终用于目标附近。
Arcade Learning Environment
我们在Arcade Learning Enviroment(ALE)(Bellemare等人。2013年)使用深度神经网络来近似临界值(critic)并表示内部期权政策和终止函数。我们使用了与(Mnih等人。2013年)网络相同的前3个卷积层。我们在第一层使用32个8×8和4个步长的卷积滤波器,在第二层使用64个4×4的步长为2的滤波器,在第三层使用64个步长为1的3×3滤波器。然后,我们将第三层的输出输入到由512个神经元组成的dense shared layer中,如图6所示。我们将期权内策略和终止梯度的学习率固定为0.00025,并使用RMSProp作为批评函数。
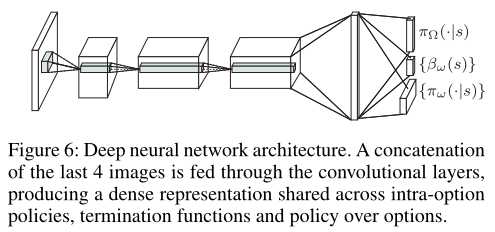
我们将期权内策略表示为第四层(稠密)的线性softmax,以输出基于当前观察的操作的概率分布。终止函数的定义类似于使用sigmoid函数,每个终端有一个输出神经元。
使用带经验回放的option内学习训练critic网络。期权政策和终止被在线更新。我们用的是(epsilon)-greedy的optiion政策 (epsilon)=0.05试验阶段(Mnih等人。2013年)。
(未完)
Related Work
由于期权发现最近受到广泛关注,我们现在更详细地讨论我们的方法相对于其他方法的地位。(Comanici和Precup 2010)使用基于梯度的方法,仅改进半马尔可夫期权的终止函数;终止通过自启动以来观察到的特征的累积测量值的逻辑分布建模。(Levy和Shimkin 2011)也建立在政策梯度方法上,通过明确地构造增广的状态空间,并将停止事件视为额外的控制动作。相反,我们不需要直接构建这个(非常大)空间。(Silver and Ciosek 2012)通过依赖组合特性将期权动态链接到更长的时间序列中。早期关于线性期权的研究(Sorg和Singh,2010年)也使用组合性来规划使用线性预期模型的期权。我们的方法也依赖于Bellman方程和组合性,但与策略梯度方法相结合。
最近几篇论文还试图将期权发现描述为一个优化问题,其解与函数逼近相容。(丹尼尔等人。2016)通过将终止函数作为隐变量来学习收益优化选项,并使用EM学习它们。(V ezhnevets等人。2016)考虑具有开环期权内策略的学习期权问题,也称为宏观行动。与经典规划一样,缓存更频繁的动作序列。一个从状态到动作序列的映射,以及一个承诺模块,在必要时触发重新规划。相反,我们始终使用闭环策略,这些策略对状态信息是反应性的,可以提供更好的解决方案。(Mankowitz,Mann,and Mannor 2016)提出了一种基于梯度的选项学习算法,假设起始集和终止函数具有特定的结构。在这个框架下,在状态空间的任何分区中只有一个选项是活动的。
(Kulkarni et al. 2016)利用DQN框架实现了一个基于梯度的期权学习器,它利用内在的奖励来学习期权的内部政策,而外部的奖励来学习期权的政策。与我们的框架不同,子目标的描述是作为选项学习者的输入。期权批评家在概念上是一般的,不需要内在动机来学习期权。
Discussion
我们开发了一种通用的基于梯度的方法来同时学习期权内策略和终止函数,以及策略优先于期权,以优化当前任务的性能目标。我们的ALE实验证明了在非线性函数逼近下,期权的端到端学习是成功的。如前所述,我们的方法只需要指定选项的数量。然而,如果想要使用额外的伪奖励,option-critic框架将很容易地适应它。在这种情况下,内部策略和终止函数梯度只需考虑伪奖励而不是任务奖励。这个想法的一个简单例子,我们在一些实验中使用了,就是使用额外的奖励来鼓励那些确实在时间上被延长的选项,只要一个转换事件发生就增加一个惩罚。我们的方法可以与任何其他启发式方法无缝地合作,使选项集偏向于某些期望的属性(例如,组合性或稀疏性),只要它可以表示为一个附加的奖励结构。然而,从结果中可以看出,这样的偏差并不是产生良好结果的必要条件。
期权批评家体系结构依赖于策略梯度定理,正如(Thomas 2014)中所讨论的,梯度估计在折扣情况下可能是有偏的。通过引入γt?t i=1(1?βi)在我们的更新(Thomas 2014,公式(3))中,可以获得无偏估计值。然而,我们不推荐这种方法,因为无偏估计量的样本复杂度通常过高,且有偏估计量在我们的实验中表现良好。
也许我们工作的最大的局限性是假设所有的选择都适用于任何地方。在函数逼近的情况下,初始集的一个自然扩展是在特征上使用分类器,或其他形式的函数逼近。因此,确定允许哪些选项可能与评估策略优于选项的成本类似(与表格设置不同,在表格设置中,具有稀疏初始集的选项会导致更快的决策)。这类似于合格跟踪,后者比在表格情况下不使用跟踪更昂贵,但与函数近似具有相同的复杂性。如果要学习初始集,则需要添加的主要约束条件是,在增广状态选项空间中,选项及其上的策略会导致遍历链。这可以表示为连接起始集和终止集的流条件。这个条件的精确描述,以及初始集的稀疏正则化,留待以后的工作。
以上是关于The option-critic architecture(下)的主要内容,如果未能解决你的问题,请参考以下文章