MHA搭建
Posted tcy1
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MHA搭建相关的知识,希望对你有一定的参考价值。
一、MHA介绍
准备三台机器:
第一台:IP:10.0.0.51 db01 2G内存
第二台:IP:10.0.0.52 db02 2G内存
第三台:IP:10.0.0.53 db03 2G内存
1.简介
MHA能够在较短的时间内实现自动故障检测和故障转移,通常在10-30秒以内;在复制框架中,MHA能够很好地解决复制过程中的数据一致性问题,由于不需要在现有的replication中添加额外的服务器,仅需要一个manager节点,而一个Manager能管理多套复制,所以能大大地节约服务器的数量;另外,安装简单,无性能损耗,以及不需要修改现有的复制部署也是它的优势之处。
MHA还提供在线主库切换的功能,能够安全地切换当前运行的主库到一个新的主库中(通过将从库提升为主库),大概0.5-2秒内即可完成。
MHA由两部分组成:MHA Manager(管理节点)和MHA Node(数据节点)。MHA Manager可以独立部署在一台独立的机器上管理多个Master-Slave集群,也可以部署在一台Slave上。当Master出现故障时,它可以自动将最新数据的Slave提升为新的Master,然后将所有其他的Slave重新指向新的Master。整个故障转移过程对应用程序是完全透明的。
#在切换过程我们可以查看日志
2.原理
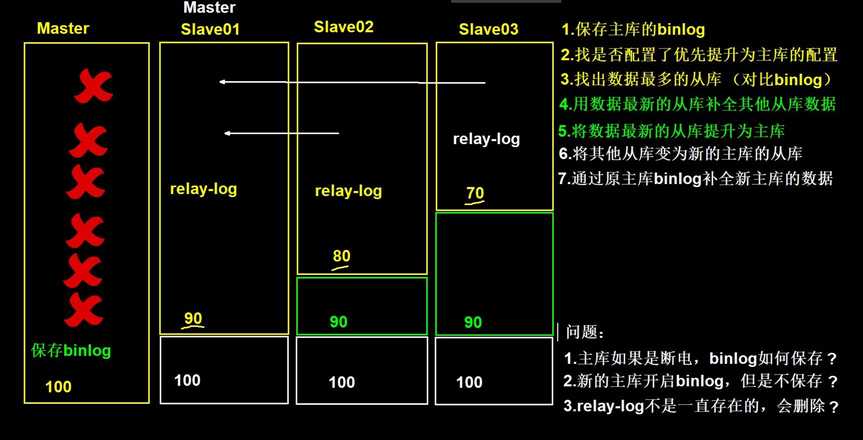
1.把宕机的master二进制日志保存下来。
2.找到binlog位置点最新的slave。
3.在binlog位置点最新的slave上用relay-log(差异日志)修复其它slave。
4.将宕机的master上保存下来的二进制日志恢复到含有最新位置点的slave上。
5.将含有最新位置点binlog所在的slave提升为master。
6.将其它slave重新指向新提升的master,并开启主从复制。
3.架构
1.MHA属于C/S结构
2.一个manager节点可以管理多套集群
3.集群中所有的机器都要部署node节点
4.node节点才是管理集群机器的
5.manager节点通过ssh连接node节点,管理
6.manager可以部署在集群中除了主库以外的任意一台机器上
4.工具
1)manager节点的工具
#解压tar包,查看
[root@db01 ~]# ll mha4mysql-manager-0.56/bin/
#检查主从状态
masterha_check_repl
#检查ssh连接(配置免密)
masterha_check_ssh
#检查MHA状态
masterha_check_status
#删除死掉机器的配置
masterha_conf_host
[server2]
hostname=10.0.0.52
port=3306
[server3]
hostname=10.0.0.53
port=3306
#启动程序
masterha_manager
#检测master是否宕机
masterha_master_monitor
#手动故障转移
masterha_master_switch
#建立TCP连接从远程服务器
masterha_secondary_check
#关闭进程的程序
masterha_stop
2)node节点工具
#解压node安装包
[root@db01 ~]# ll mha4mysql-node-0.56/bin/
#对比relay-log
apply_diff_relay_logs
#防止回滚事件
filter_mysqlbinlog
#删除relay-log
purge_relay_logs
#保存binlog
save_binary_logs
5.MHA优点
1)Masterfailover and slave promotion can be done very quickly
自动故障转移快
2)Mastercrash does not result in data inconsistency
主库崩溃不存在数据一致性问题
3)Noneed to modify current MySQL settings (MHA works with regular MySQL)
不需要对当前mysql环境做重大修改
4)Noneed to increase lots of servers
不需要添加额外的服务器(仅一台manager就可管理上百个replication)
5)Noperformance penalty
性能优秀,可工作在半同步复制和异步复制,当监控mysql状态时,仅需要每隔N秒向master发送ping包(默认3秒),所以对性能无影响。你可以理解为MHA的性能和简单的主从复制框架性能一样。
6)Works with any storage engine
只要replication支持的存储引擎,MHA都支持,不会局限于innodb
二、搭建MHA
1.保证主从的状态
#主库
mysql> show master status;
#从库
mysql> show slave statusG
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
#从库
mysql> show slave statusG
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
2.部署MHA之前配置
1.关闭从库删除relay-log的功能
relay_log_purge=0
2.配置从库只读
read_only=1
3.从库保存binlog
log_slave_updates
#禁用自动删除relay log 功能
mysql> set global relay_log_purge = 0;
#设置只读
mysql> set global read_only=1;
#编辑配置文件
[root@mysql-db02 ~]# vim /etc/my.cnf
#在mysqld标签下添加
[mysqld]
#禁用自动删除relay log 永久生效
relay_log_purge = 0
3.配置
1)主库配置
[root@db01 ~]# vim /etc/my.cnf
[mysqld]
server_id=1
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
2)从库01配置
[root@db02 ~]# vim /etc/my.cnf
[mysqld]
server_id=2
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
3)从库02配置
[root@db03 ~]# vim /etc/my.cnf
[mysqld]
server_id=3
log_bin=/usr/local/mysql/data/mysql-bin
gtid_mode=on
enforce_gtid_consistency
log-slave-updates
relay_log_purge=0
read_only=1
4.部署MHA
1)安装依赖(所有机器)
[root@db01 ~]# yum install perl-DBD-MySQL -y
[root@db02 ~]# yum install perl-DBD-MySQL -y
[root@db03 ~]# yum install perl-DBD-MySQL -y
2)安装manager依赖(manager机器,10.0.0.53)
[root@db03 ~]# yum install -y perl-Config-Tiny epel-release perl-Log-Dispatch perl-Parallel-ForkManager perl-Time-HiRes
3)部署node节点
[root@db01 ~]# rz mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db02 ~]# rz mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db03 ~]# rz mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db01 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db02 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
[root@db03 ~]# yum localinstall -y mha4mysql-node-0.56-0.el6.noarch.rpm
4)部署manager节点
[root@db03 ~]# rz mha4mysql-manager-0.56-0.el6.noarch.rpm
[root@db03 ~]# yum localinstall -y mha4mysql-manager-0.56-0.el6.noarch.rpm
5)配置MHA
#创建MHA配置目录
[root@db03 ~]# mkdir -p /service/mha
#配置MHA
[root@db03 ~]# vim /service/mha/app1.cnf
[server default]
#指定日志存放路径
manager_log=/service/mha/manager
#指定工作目录
manager_workdir=/service/mha/app1
#binlog存放目录
master_binlog_dir=/usr/local/mysql/data
#MHA管理用户
user=mha
#MHA管理用户的密码
password=mha
#检测时间
ping_interval=2
#主从用户
repl_user=rep
#主从用户的密码
repl_password=123
#ssh免密用户
ssh_user=root
[server1]
hostname=172.16.1.51
port=3306
[server2]
#candidate_master=1
#check_repl_delay=0
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
#设置为候选master,如果设置该参数以后,发生主从切换以后将会将此从库提升为主库,即使这个主库不是集群中事件最新的slave。
candidate_master=1
#默认情况下如果一个slave落后master 100M的relay logs的话,MHA将不会选择该slave作为一个新的master,因为对于这个slave的恢复需要花费很长时间,通过设置check_repl_delay=0,MHA触发切换在选择一个新的master的时候将会忽略复制延时,这个参数对于设置了candidate_master=1的主机非常有用,因为这个候选主在切换的过程中一定是新的master
check_repl_delay=0
6)创建MHA管理用户
#主库执行即可
mysql> grant all on *.* to mha@‘172.16.1.%‘ identified by ‘mha‘;
Query OK, 0 rows affected (0.03 sec)
7)ssh免密(三台机器每一台都操作一下内容)
#创建秘钥对
[root@db01 ~]# ssh-keygen -t dsa -P ‘‘ -f ~/.ssh/id_dsa >/dev/null 2>&1
#发送公钥,包括自己
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.51
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.52
[root@db01 ~]# ssh-copy-id -i /root/.ssh/id_dsa.pub root@172.16.1.53
8)检测MHA状态
#检测主从
[root@db03 ~]# masterha_check_repl --conf=/service/mha/app1.cnf
MySQL Replication Health is OK.
#检测ssh
[root@db03 ~]# masterha_check_ssh --conf=/service/mha/app1.cnf
Mon Jul 27 11:40:06 2020 - [info] All SSH connection tests passed successfully.
9)启动MHA
#启动
[root@db03 ~]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
nohup ... & #后台启动
masterha_manager #启动命令
--conf=/service/mha/app1.cnf #指定配置文件
--remove_dead_master_conf #移除挂掉的主库配置
--ignore_last_failover #忽略最后一次切换
< /dev/null > /service/mha/manager.log 2>&1
#MHA保护机制:
1.MHA主库切换后,8小时内禁止再次切换
2.切换后会生成一个锁文件,下一次启动MHA需要检测该文件是否存在
5.测试MHA
#停掉主库
[root@db01 ~]# systemctl stop mysqld
#查看MHA的日志
[root@db03 ~]# tail -20 /service/mha/manager
----- Failover Report -----
app1: MySQL Master failover 172.16.1.51(172.16.1.51:3306) to 172.16.1.52(172.16.1.52:3306) succeeded
Master 172.16.1.51(172.16.1.51:3306) is down!
Check MHA Manager logs at db03:/service/mha/manager for details.
Started automated(non-interactive) failover.
The latest slave 172.16.1.52(172.16.1.52:3306) has all relay logs for recovery.
Selected 172.16.1.52(172.16.1.52:3306) as a new master.
172.16.1.52(172.16.1.52:3306): OK: Applying all logs succeeded.
172.16.1.53(172.16.1.53:3306): This host has the latest relay log events.
Generating relay diff files from the latest slave succeeded.
172.16.1.53(172.16.1.53:3306): OK: Applying all logs succeeded. Slave started, replicating from 172.16.1.52(172.16.1.52:3306)
172.16.1.52(172.16.1.52:3306): Resetting slave info succeeded.
Master failover to 172.16.1.52(172.16.1.52:3306) completed successfully
#登录数据库查看状态(在db03中查看)
mysql> show slave statusG
*************************** 1. row ***************************
Slave_IO_State: Waiting for master to send event
Master_Host: 172.16.1.52
Master_User: rep
Master_Port: 3306
Connect_Retry: 60
Master_Log_File: mysql-bin.000003
Read_Master_Log_Pos: 120
Relay_Log_File: db03-relay-bin.000002
Relay_Log_Pos: 283
Relay_Master_Log_File: mysql-bin.000003
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
三、恢复MHA
1.修复数据库
[root@db01 ~]# systemctl start mysqld.service
2.恢复主从
#将恢复的数据库当成新的从库加入集群
#找到binlog位置点
[root@db03 ~]# grep ‘CHANGE MASTER‘ /service/mha/manager | awk -F: ‘NR==1 {print $4}‘
CHANGE MASTER TO MASTER_HOST=‘172.16.1.52‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘rep‘, MASTER_PASSWORD=‘xxx‘;
#恢复的数据库执行change master to
mysql> CHANGE MASTER TO MASTER_HOST=‘172.16.1.52‘, MASTER_PORT=3306, MASTER_AUTO_POSITION=1, MASTER_USER=‘rep‘, MASTER_PASSWORD=‘123‘;
Query OK, 0 rows affected, 2 warnings (0.20 sec)
mysql> start slave;
Query OK, 0 rows affected (0.05 sec)
3.恢复MHA
#将恢复的数据库配置到MHA配置文件
[root@db03 ~]# vim /service/mha/app1.cnf
......
[server1]
hostname=172.16.1.51
port=3306
[server2]
hostname=172.16.1.52
port=3306
[server3]
hostname=172.16.1.53
port=3306
......
#启动MHA
[root@db03 ~]# nohup masterha_manager --conf=/service/mha/app1.cnf --remove_dead_master_conf --ignore_last_failover < /dev/null > /service/mha/manager.log 2>&1 &
以上是关于MHA搭建的主要内容,如果未能解决你的问题,请参考以下文章