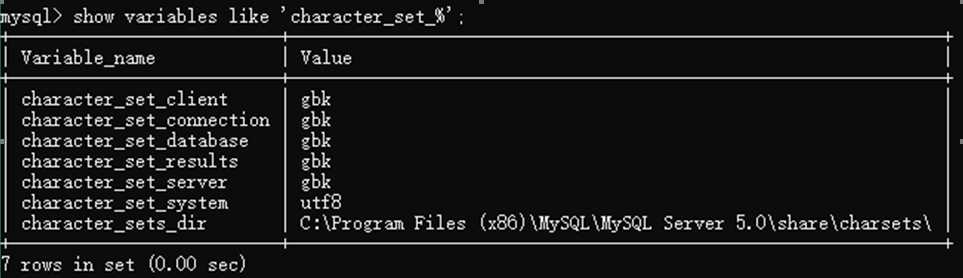
$通配符,匹配字符串结尾
import re
email_list = ["xiaoWang@163.com", "xiaoWang@163.comheihei", ".com.xiaowang@qq.com"]
for email in email_list:
ret = re.match("[w]{4,20}@163.com$", email)
# w 匹配字母或数字# {4,20}匹配前一个字符4到20次if ret:
print("%s 是符合规定的邮件地址,匹配后的结果是:%s" % (email, ret.group()))
elif ret == None :
print("%s 不符合要求" % email)
‘‘‘
xiaoWang@163.com 是符合规定的邮件地址,匹配后的结果是:xiaoWang@163.com
xiaoWang@163.comheihei 不符合要求
.com.xiaowang@qq.com 不符合要求
‘‘‘
re.match匹配
import re
# re.match匹配字符(仅匹配开头)
string = ‘Hany‘# result = re.match(string,‘123Hany hanyang‘)
result = re.match(string,‘Hany hanyang‘)
# 使用group方法提取数据if result:
print("匹配到的字符为:",result.group( ))
else:
print("没匹配到以%s开头的字符串"%(string))
‘‘‘匹配到的字符为: Hany‘‘‘
re中findall用法
import re
ret = re.findall(r"d+","Hany.age = 22, python.version = 3.7.5")
# 输出全部找到的结果 d + 一次或多次print(ret)
# [‘22‘, ‘3‘, ‘7‘, ‘5‘]
re中search用法
import re
ret = re.search(r"d+",‘阅读次数为:9999‘)
# 只要找到规则即可,从头到尾print(ret.group())
‘‘‘9999‘‘‘
re中匹配 [ ] 中列举的字符
import re
# 匹配[]中列举的字符
# 如果hello的首字符小写,那么正则表达式需要小写的h
ret = re.match("h","hello Python")
print(ret.group())
# 如果hello的首字符大写,那么正则表达式需要大写的H
ret = re.match("H","Hello Python")
print(ret.group())
# 大小写h都可以的情况
ret = re.match("[hH]","hello Python")
print(ret.group())
ret = re.match("[hH]","Hello Python")
print(ret.group())
ret = re.match("[hH]ello Python","Hello Python")
print(ret.group())
# 匹配0到9第一种写法
ret = re.match("[0123456789]Hello Python","7Hello Python")
print(ret.group())
# 匹配0到9第二种写法
ret = re.match("[0-9]Hello Python","7Hello Python")
print(ret.group())
# 匹配0到3 5到9的数字
ret = re.match("[0-3,5-9]Hello Python","7Hello Python")
print(ret.group())
# 下面这个正则不能够匹配到数字4,因此ret为None
ret = re.match("[0-3,5-9]Hello Python","4Hello Python")
# print(ret.group())‘‘‘
h
H
h
H
Hello Python
7Hello Python
7Hello Python
7Hello Python
‘‘‘
re中匹配不是以4,7结尾的手机号码
import re
tels = ["13100001234", "18912344321", "10086", "18800007777"]
for tel in tels:
ret = re.match("1d{9}[0-3,5-6,8-9]", tel)
if ret:
print("想要的手机号是:{}".format(ret.group()))
else:
print("%s 不是想要的手机号" % tel)
‘‘‘
13100001234 不是想要的手机号
想要的手机号是:18912344321
10086 不是想要的手机号
18800007777 不是想要的手机号
‘‘‘
re中匹配中奖号码
import re
# 匹配中奖号码
str2 = ‘17711602423‘
pattern = re.compile(‘^(1[3578]d)(d{4})(d{4})$‘)
print(pattern.sub(r‘1****3‘,str2))
# r 字符串编码转化‘‘‘177****2423‘‘‘
re中匹配中文字符
import re
pattern = re.compile(‘[u4e00-u9fa5]‘)
strs = ‘你好 Hello hany‘print(pattern.findall(strs))
pattern = re.compile(‘[u4e00-u9fa5]+‘)
print(pattern.findall(strs))
# [‘你‘, ‘好‘]
# [‘你好‘]
re中匹配任意字符
import re
# 匹配任意一个字符
ret = re.match(".","M")
# ret = re.match(".","M123") # M
# 匹配单个字符print(ret.group())
ret = re.match("t.o","too")
print(ret.group())
ret = re.match("t.o","two")
print(ret.group())
‘‘‘
M
too
two
‘‘‘
re中匹配多个字符_加号
import re
#匹配前一个字符出现1次或无限次
names = ["name1", "_name", "2_name", "__name__"]
for name in names:
ret = re.match("[a-zA-Z_]+[w]*",name)
if ret:
print("变量名 %s 符合要求" % ret.group())
else:
print("变量名 %s 非法" % name)
‘‘‘
变量名 name1 符合要求
变量名 _name 符合要求
变量名 2_name 非法
变量名 __name__ 符合要求
‘‘‘
re中匹配多个字符_星号
import re
# 匹配前一个字符出现0次或无限次
# *号只针对前一个字符
ret = re.match("[A-Z][a-z]*","M")
# ret = re.match("[a-z]*","M") 没有结果print(ret.group())
ret = re.match("[A-Z][a-z]*","MnnM")
print(ret.group())
ret = re.match("[A-Z][a-z]*","Aabcdef")
print(ret.group())
‘‘‘
M
Mnn
Aabcdef
‘‘‘
re中匹配多个字符_问号
import re
# 匹配前一个字符要么1次,要么0次
ret = re.match("[1-9]?[0-9]","7")
print(ret.group())
ret = re.match("[1-9]?","7")
print(ret.group())
ret = re.match("[1-9]?d","33")
print(ret.group())
ret = re.match("[1-9]?d[1-9]","33")
print(ret.group())
ret = re.match("[1-9]?d","09")
print(ret.group())
‘‘‘
7
7
33
33
0
‘‘‘
re中匹配左右任意一个表达式
import re
ret = re.match("[1-9]?d","8")
# ? 匹配1次或0次print(ret.group()) # 8
ret = re.match("[1-9]?d","78")
print(ret.group()) # 78# 不正确的情况
ret = re.match("[1-9]?d","08")
print(ret.group()) # 0# 修正之后的
ret = re.match("[1-9]?d$","08")
if ret:
print(ret.group())
else:
print("不在0-100之间")
# 添加|
ret = re.match("[1-9]?d$|100","8")
print(ret.group()) # 8
ret = re.match("[1-9]?d$|100","78")
print(ret.group()) # 78
ret = re.match("[1-9]?d$|100","08")
# print(ret.group()) # 不是0-100之间
ret = re.match("[1-9]?d$|100","100")
print(ret.group()) # 100
re中匹配数字
import re
# 普通的匹配方式
ret = re.match("嫦娥1号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥2号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥3号","嫦娥3号发射成功")
print(ret.group())
# 使用d进行匹配
ret = re.match("嫦娥d号","嫦娥1号发射成功")
print(ret.group())
ret = re.match("嫦娥d号","嫦娥2号发射成功")
print(ret.group())
ret = re.match("嫦娥d号","嫦娥3号发射成功")
print(ret.group())
‘‘‘
嫦娥1号
嫦娥2号
嫦娥3号
嫦娥1号
嫦娥2号
嫦娥3号
‘‘‘
re中对分组起别名
#(?P<name>)import re
ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h1></html>")
print(ret.group())
ret = re.match(r"<(?P<name1>w*)><(?P<name2>w*)>.*</(?P=name2)></(?P=name1)>", "<html><h1>www.itcast.cn</h2></html>")
# (?P=name2) ----- (?P<name2>w*)
# ret.group()‘‘‘
<html><h1>www.itcast.cn</h1></html>
‘‘‘
re中将括号中字符作为一个分组
#(ab)将ab作为一个分组import re
ret = re.match("w{4,20}@163.com", "test@163.com")
print(ret.group()) # test@163.com
ret = re.match("w{4,20}@(163|126|qq).com", "test@126.com")
print(ret.group()) # test@126.com
ret = re.match("w{4,20}@(163|126|qq).com", "test@qq.com")
print(ret.group()) # test@qq.com
ret = re.match("w{4,20}@(163|126|qq).com", "test@gmail.com")
if ret:
print(ret.group())
else:
print("不是163、126、qq邮箱") # 不是163、126、qq邮箱‘‘‘
test@163.com
test@126.com
test@qq.com
不是163、126、qq邮箱
‘‘‘
正则表达式_合集下
re中引用分组匹配字符串
import re
# 能够完成对正确的字符串的匹配
ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</html>")
print(ret.group())
# 如果遇到非正常的html格式字符串,匹配出错</htmlbalabala>会一起输出
ret = re.match("<[a-zA-Z]*>w*</[a-zA-Z]*>", "<html>hh</htmlbalabala>")
#
print(ret.group())
# 正确的理解思路:如果在第一对<>中是什么,按理说在后面的那对<>中就应该是什么# 通过引用分组中匹配到的数据即可,但是要注意是元字符串,即类似 r""这种格式
ret = re.match(r"<([a-zA-Z]*)>w*</1>", "<html>hh</html>")
# </1>匹配第一个规则print(ret.group())
# 因为2对<>中的数据不一致,所以没有匹配出来
test_label = "<html>hh</htmlbalabala>"
ret = re.match(r"<([a-zA-Z]*)>w*</1>", test_label)
if ret:
print(ret.group())
else:
print("%s 这是一对不正确的标签" % test_label)
‘‘‘
<html>hh</html>
<html>hh</htmlbalabala>
<html>hh</html>
<html>hh</htmlbalabala> 这是一对不正确的标签
‘‘‘
re中引用分组匹配字符串_2
import re
labels = ["<html><h1>www.itcast.cn</h1></html>", "<html><h1>www.itcast.cn</h2></html>"]
for label in labels:
ret = re.match(r"<(w*)><(w*)>.*</2></1>", label)
# <2>和第二个匹配一样的内容if ret:
print("%s 是符合要求的标签" % ret.group())
else:
print("%s 不符合要求" % label)
‘‘‘
<html><h1>www.itcast.cn</h1></html> 是符合要求的标签
<html><h1>www.itcast.cn</h2></html> 不符合要求
‘‘‘
re中提取区号和电话号码
import re
ret = re.match("([^-]*)-(d+)","010-1234-567")
# 除了 - 的所有字符
# 对最后一个-前面的所有字符进行分组,直到最后一个数字为止print(ret.group( ))
print(ret.group(1))#返回-之前的数据,不一定是最后一个-之前print(ret.group(2))
re中的贪婪
import re
s= "This is a number 234-235-22-423"
r=re.match(".+(d+-d+-d+-d+)",s)
# .+ 尽量多的匹配任意字符,匹配到-前一个数字之前
# . 匹配任意字符print(type(r))
print(r.group())
print(r.group(0))
print(r.group(1))
r=re.match(".+?(d+-d+-d+-d+)",s)
print(r.group())
print(r.group(1))#到数字停止贪婪‘‘‘
<class ‘re.Match‘>
This is a number 234-235-22-423
This is a number 234-235-22-423
4-235-22-423
This is a number 234-235-22-423
234-235-22-423
‘‘‘import re
ret = re.match(r"aa(d+)","aa2343ddd")
# 尽量多的匹配字符print(ret.group())
# 使用? 将re贪婪转换为非贪婪
ret = re.match(r"aa(d+?)","aa2343ddd")
# 只输出一个数字print(ret.group())
‘‘‘
aa2343
aa2
‘‘‘
re使用split切割字符串
import re
ret = re.split(r":| ","info:XiaoLan 22 Hany.control")
# | 或 满足一个即可print(ret)
str1 = ‘one,two,three,four‘
pattern = re.compile(‘,‘)
# 按照,将string分割后返回print(pattern.split(str1))
# [‘one‘, ‘two‘, ‘three‘, ‘four‘]
str2 = ‘one1two2three3four‘print(re.split(‘d+‘,str2))
# [‘one‘, ‘two‘, ‘three‘, ‘four‘]
re匹配中subn,进行替换并返回替换次数
import re
pattern = re.compile(‘d+‘)
strs = ‘one1two2three3four‘print(pattern.subn(‘-‘,strs))
# (‘one-two-three-four‘, 3) 3为替换的次数
re匹配中sub将匹配到的数据进行替换
# import re
# ret = re.sub(r"d+", ‘替换的字符串998‘, "python = 997")
# # python = 替换的字符串998
# print(ret)
# # 将匹配到的数据替换掉,替换成想要替换的数据
# re.sub("规则","替换的字符串","想要替换的数据")import re
def add(temp):
strNum = temp.group()
# 匹配到的数据.group()方式print("原来匹配到的字符:",int(temp.group()))
num = int(strNum) + 5 #字符串强制转换return str(num)
ret = re.sub(r"d+", add, "python = 997")
# re.sub(‘正则规则‘,‘替换的字符串‘,‘字符串‘)print(ret)
ret = re.sub(r"d+", add, "python = 99")
print(ret)
pattern = re.compile(‘d‘)
str1 = ‘one1two2three3four‘print(pattern.sub(‘-‘,str1))
# one-two-three-fourprint(re.sub(‘d‘,‘-‘,str1))
# one-two-three-four‘‘‘
原来匹配到的字符: 997
python = 1002
原来匹配到的字符: 99
python = 104
one-two-three-four
one-two-three-four
‘‘‘
re匹配的小例子
import re
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?.jpg", src)
print(ret.group())
res = re.compile(‘[a-zA-Z]{1}‘)
strs = ‘123abc456‘print(re.search(res,strs).group( ))
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# print(re.finditer(res,strs)) #返回迭代器对象‘‘‘
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
a
[‘a‘, ‘b‘, ‘c‘]
‘‘‘
匹配前一个字符出现m次
import re
src="https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg"
ret = re.search(r"https://.*?.jpg", src)
print(ret.group())
res = re.compile(‘[a-zA-Z]{1}‘)
strs = ‘123abc456‘print(re.search(res,strs).group( ))
print(re.findall(res,strs)) #findall返回列表元素对象不具有group函数
# print(re.finditer(res,strs)) #返回迭代器对象‘‘‘
https://rpic.douyucdn.cn/appCovers/2016/11/13/1213973_201611131917_small.jpg
a
[‘a‘, ‘b‘, ‘c‘]
‘‘‘
引用分组
import re
strs = ‘hello 123,world 456‘
pattern = re.compile(‘(w+) (d+)‘)
# for i in pattern.finditer(strs):
# print(i.group(0))
# print(i.group(1))
# print(i.group(2))#当存在第二个分组时‘‘‘hello 123
hello
123
world 456
world
456
‘‘‘print(pattern.sub(r‘2 1‘,strs))
# 先输出第二组,后输出第一组print(pattern.sub(r‘1 2‘,strs))
当findall遇到分组时,只匹配分组
import re
pattern = re.compile(‘([a-z])[a-z]([a-z])‘)
strs = ‘123abc456asd‘# print(re.findall(pattern,strs))
# [(‘a‘, ‘c‘), (‘a‘, ‘d‘)]返回分组匹配到的结果
result = re.finditer(pattern,strs)
for i in result:
print(i.group( )) #match对象使用group函数输出print(i.group(0))#返回匹配到的所有结果print(i.group(1))#返回第一个分组匹配的结果print(i.group(2))#返回第二个分组匹配的结果
# <re.Match object; span=(3, 6), match=‘abc‘>
# <re.Match object; span=(9, 12), match=‘asd‘>
# 返回完整的匹配结果‘‘‘
abc
abc
a
c
asd
asd
a
d
‘‘‘
线程_apply堵塞式
‘‘‘
创建三个进程,让三个进程分别执行功能,关闭进程
Pool 创建 ,apply执行 , close,join 关闭进程
‘‘‘from multiprocessing import Pool
import os,time,random
def worker(msg):
# 创建一个函数,用来使进程进行执行
time_start = time.time()
print("%s 号进程开始执行,进程号为 %d"%(msg,os.getpid()))
# 使用os.getpid()获取子进程号# os.getppid()返回父进程号
time.sleep(random.random()*2)
time_end = time.time()
print(msg,"号进程执行完毕,耗时%0.2f"%(time_end-time_start))
# 计算运行时间if__name__ == ‘__main__‘:
po = Pool(3)#创建三个进程print("进程开始")
for i in range(3):
# 使用for循环,运行刚刚创建的进程
po.apply(worker,(i,))#进程池调用方式apply堵塞式# 第一个参数为函数名,第二个参数为元组类型的参数(函数运行会用到的形参)#只有当进程执行完退出后,才会新创建子进程来调用请求
po.close()# 关闭进程池,关闭后po不再接收新的请求# 先使用进程的close函数关闭,后使用join函数进行等待
po.join() # 等待po中所有子进程执行完成,必须放在close语句之后print("进程结束")
‘‘‘创建->apply应用->close关闭->join等待结束‘‘‘
线程_FIFO队列实现生产者消费者
import threading # 导入线程库import time
from queue import Queue # 队列class Producer(threading.Thread):
# 线程的继承类,修改 run 方法def run(self):
global queue
count = 0
while True:
if queue.qsize() <1000:
for i in range(100):
count = count + 1
msg = ‘生成产品‘+str(count)
queue.put(msg)#向队列中添加元素print(msg)
time.sleep(1)
class Consumer(threading.Thread):
# 线程的继承类,修改 run 方法def run(self):
global queue
while True:
if queue.qsize() >100 :
for i in range(3):
msg = self.name + ‘消费了‘ + queue.get() #获取数据# queue.get()获取到数据print(msg)
time.sleep(1)
if__name__ == ‘__main__‘:
queue = Queue()
# 创建一个队列for i in range(500):
queue.put(‘初始产品‘+str(i))
# 在 queue 中放入元素 使用 put 函数for i in range(2):
p = Producer()
p.start()
# 调用Producer类的run方法for i in range(5):
c = Consumer()
c.start()
线程_multiprocessing实现文件夹copy器
import multiprocessing
import os
import time
import random
def copy_file(queue,file_name,source_folder_name,dest_folder_name):
f_read = open(source_folder_name+"/"+file_name,"rb")
f_write = open(source_folder_name+"/"+file_name,"wb")
while True:
time.sleep(random.random())
content = f_read.read(1024)
if content:
f_write.write(content)
else:
break
f_read.close()
f_write.close()
# 发送已经拷贝完毕的文件名字 queue.put(file_name)
def main():
# 获取要复制的文件夹
source_folder_name = input("请输入要复制的文件夹名字:")
# 整理目标文件夹
dest_folder_name = source_folder_name + "副本"# 创建目标文件夹try:
os.mkdir(dest_folder_name)#创建文件夹except:
pass# 获取这个文件夹中所有的普通文件名
file_names = os.listdir(source_folder_name)
# 创建Queue
queue = multiprocessing.Manager().Queue()
# 创建线程池
pool = multiprocessing.Pool(3)
for file_name in file_names:
# 向线程池中添加任务
pool.apply_async(copy_file,args=(queue,file_name,source_folder_name,dest_folder_name))#不堵塞执行# 主进程显示进度 pool.close()
all_file_num = len(file_names)
while True:
file_name = queue.get()
if file_name in file_names:
file_names.remove(file_name)
copy_rate = (all_file_num - len(file_names)) * 100 / all_file_num
print("
%.2f...(%s)" % (copy_rate, file_name) + "" * 50, end="")
if copy_rate >= 100:
breakprint()
if__name__ == "__main__":
main()
线程_multiprocessing异步
from multiprocessing import Pool
import time
import os
def test():
print("---进程池中的进程---pid=%d,ppid=%d--"%(os.getpid(),os.getppid()))
for i in range(3):
print("----%d---"%i)
time.sleep(1)
return"hahah"def test2(args):
print("---callback func--pid=%d"%os.getpid())
print("---callback func--args=%s"%args)
if__name__ == ‘__main__‘:
pool = Pool(3)
pool.apply_async(func=test,callback=test2)
# 异步执行
time.sleep(5)
print("----主进程-pid=%d----"%os.getpid())
线程_Process实例
from multiprocessing import Process
import os
from time import sleep
def run_proc(name,age,**kwargs):
for i in range(10):
print("子进程运行中,名字为 = %s,年龄为 = %d,子进程 = %d..."%(name,age,os.getpid()))
print(kwargs)
sleep(0.5)
if__name__ == ‘__main__‘:
print("父进程: %d"%(os.getpid()))
pro = Process(target=run_proc,args=(‘test‘,18),kwargs={‘kwargs‘:20})
print("子进程将要执行")
pro.start( )
sleep(1)
pro.terminate()#将进程进行终止 pro.join()
print("子进程已结束")
from gevent import monkey
import gevent
import urllib.request
#有IO操作时,使用patch_all自动切换monkey.patch_all()
def my_downLoad(file_name, url):
print(‘GET: %s‘ % url)
resp = urllib.request.urlopen(url)
# 使用库打开网页
data = resp.read()
with open(file_name, "wb") as f:
f.write(data)
print(‘%d bytes received from %s.‘ % (len(data), url))
gevent.joinall([
gevent.spawn(my_downLoad, "1.mp4", ‘http://oo52bgdsl.bkt.clouddn.com/05day-08-%E3%80%90%E7%90%86%E8%A7%A3%E3%80%91%E5%87%BD%E6%95%B0%E4%BD%BF%E7%94%A8%E6%80%BB%E7%BB%93%EF%BC%88%E4%B8%80%EF%BC%89.mp4‘),
gevent.spawn(my_downLoad, "2.mp4", ‘http://oo52bgdsl.bkt.clouddn.com/05day-03-%E3%80%90%E6%8E%8C%E6%8F%A1%E3%80%91%E6%97%A0%E5%8F%82%E6%95%B0%E6%97%A0%E8%BF%94%E5%9B%9E%E5%80%BC%E5%87%BD%E6%95%B0%E7%9A%84%E5%AE%9A%E4%B9%89%E3%80%81%E8%B0%83%E7%94%A8%28%E4%B8%8B%29.mp4‘),
])
from gevent import monkey
import gevent
import urllib.request
# 有耗时操作时需要monkey.patch_all()
def my_downLoad(url):
print(‘GET: %s‘ % url)
resp = urllib.request.urlopen(url)
data = resp.read()
print(‘%d bytes received from %s.‘ % (len(data), url))
gevent.joinall([
gevent.spawn(my_downLoad, ‘http://www.baidu.com/‘),
gevent.spawn(my_downLoad, ‘http://www.itcast.cn/‘),
gevent.spawn(my_downLoad, ‘http://www.itheima.com/‘),
])
线程_gevent自动切换CPU协程
import gevent
def f(n):
for i in range(n):
print (gevent.getcurrent(), i)
# gevent.getcurrent() 获取当前进程
g1 = gevent.spawn(f, 3)#函数名,数目
g2 = gevent.spawn(f, 4)
g3 = gevent.spawn(f, 5)
g1.join()
g2.join()
g3.join()
import gevent
def f(n):
for i in range(n):
print (gevent.getcurrent(), i)
#用来模拟一个耗时操作,注意不是time模块中的sleep
gevent.sleep(1)
g1 = gevent.spawn(f, 2)
g2 = gevent.spawn(f, 3)
g3 = gevent.spawn(f, 4)
g1.join()
g2.join()
g3.join()
import gevent
import random
import time
def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
gevent.joinall([
# 添加可以切换的协程
gevent.spawn(coroutine_work, "work0"),
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work, "work2")
])
from gevent import monkey
import gevent
import random
import time
# 有耗时操作时需要
monkey.patch_all()#自动切换协程
# 将程序中用到的耗时操作的代码,换为gevent中自己实现的模块def coroutine_work(coroutine_name):
for i in range(10):
print(coroutine_name, i)
time.sleep(random.random())
gevent.joinall([
gevent.spawn(coroutine_work, "work"),
gevent.spawn(coroutine_work, "work1"),
gevent.spawn(coroutine_work, "work2")
])
线程_使用multiprocessing启动一个子进程及创建Process 的子类
from multiprocessing import Process
import os
# 子进程执行的函数def run_proc(name):
print("子进程运行中,名称:%s,pid:%d..."%(name,os.getpid()))
if__name__ == "__main__":
print("父进程为:%d..."%(os.getpid()))
# os.getpid()获取到进程名
pro = Process(target=run_proc,args=(‘test‘,))
# target=函数名 args=(参数,)print("子进程将要执行")
pro.start()#进程开始
pro.join()#添加进程print("子进程执行结束...")
from multiprocessing import Queue
from multiprocessing import Process
import os,time,random
def write(q):
for value in [‘a‘,‘b‘,‘c‘]:
print("Put %s to q ..."%(value))
q.put(value)
time.sleep(random.random())
def read(q):
while True:
ifnot q.empty():
value = q.get(True)
print("Get %s from Queue..."%(value))
time.sleep(random.random())
else:
breakif__name__ == ‘__main__‘:
#父进程创建Queue,传给各个子进程
q = Queue()
pw = Process(target=write,args=(q,))
pr = Process(target=read,args=(q,))
pw.start()
# 等待pw结束 pw.join()
pr.start()
pr.join()
print("数据写入读写完成")
from multiprocessing import Manager,Pool
import os,time,random
# 名称为reader 输出子进程和父进程 os 输出q的信息def reader(q):
print("reader启动,子进程:%s,父进程:%s"%(os.getpid(),os.getppid()))
for i in range(q.qsize()):#在0 ~ qsize范围内print("获取到queue的信息:%s"%(q.get(True)))
def writer(q):
print("writer启动,子进程:%s,父进程:%s"%(os.getpid(),os.getppid()))
for i in"HanYang":#需要写入到 q 的数据 q.put(i)
if__name__ == ‘__main__‘:
print("%s 开始 "%(os.getpid()))
q = Manager().Queue()#Queue使用multiprocessing.Manager()内部的
po = Pool()#创建一个线程池
po.apply(writer,(q,))#使用apply阻塞模式 po.apply(reader,(q,))
po.close()#关闭
po.join()#等待结束print("(%s) 结束"%(os.getpid()))
线程_进程池
from multiprocessing import Pool
import os,time,random
def worker(msg):
start_time = time.time()
print("(%s)开始执行,进程号为(%s)"%(msg,os.getpid()))
time.sleep(random.random()*2)
end_time = time.time()
print(msg,"(%s)执行完毕,执行时间为:%.2f"%(os.getpid(),end_time-start_time))
if__name__ == ‘__main__‘:
po = Pool(3)#定义一个进程池,最大进程数为3for i in range(0,6):
po.apply_async(worker,(i,))
# 参数:函数名,(传递给目标的参数元组)# 每次循环使用空闲的子进程调用函数,满足每个时刻都有三个进程在执行print("---开始---")
po.close()
po.join()
print("---结束---")
"""
multiprocessing.Pool的常用函数:
apply_async(func[,args[,kwds]]):
使用非阻塞方式调用func,并行执行
args为传递给func的参数列表
kwds为传递给func的关键字参数列表
apply(func[,args[,kwds]])
使用堵塞方式调用func
堵塞方式:必须等待上一个进程退出才能执行下一个进程
close()
关闭Pool,使其不接受新的任务
terminate()
无论任务是否完成,立即停止
join()
主进程堵塞,等待子进程的退出
注:必须在terminate,close函数之后使用
"""
线程_可能发生的问题
from threading import Thread
g_num = 0
def test1():
global g_num
for i in range(1000000):
g_num += 1
print("---test1---g_num=%d"%g_num)
def test2():
global g_num
for i in range(1000000):
g_num += 1
print("---test2---g_num=%d"%g_num)
p1 = Thread(target=test1)
p1.start()
# time.sleep(3)
p2 = Thread(target=test2)
p2.start()
print("---g_num=%d---"%g_num)
内存泄漏
import gc
class ClassA():
def__init__(self):
print(‘对象产生 id:%s‘%str(hex(id(self))))
def f2():
while True:
c1 = ClassA()
c2 = ClassA()
c1.t = c2#引用计数变为2
c2.t = c1
del c1#引用计数变为1 0才进行回收del c2
#把python的gc关闭gc.disable()
f2()
== 和 is 的区别
import copy
a = [‘a‘,‘b‘,‘c‘]
b = a #b和a引用自同一块地址空间print("a==b :",a==b)
print("a is b :",a is b)
c = copy.deepcopy(a)# 对a进行深拷贝print("a的id值为:",id(a))
print("b的id值为:",id(b))
print("c的id值为:",id(c))#深拷贝,不同地址print("a==c :",a==c)
print("a is c :",a is c)
"""
is 是比较两个引用是否指向了同一个对象(引用比较)。
== 是比较两个对象是否相等。
"""‘‘‘
a==b : True
a is b : True
a的id值为: 2242989720448
b的id值为: 2242989720448
c的id值为: 2242989720640
a==c : True
a is c : False
‘‘‘
class Round2Float(float):
def__new__(cls,num):
num = round(num,2)
obj = float.__new__(Round2Float,num)
return obj
f=Round2Float(4.324599)
print(f)
‘‘‘派生不可变类型‘‘‘
ctime使用及datetime简单使用
from time import ctime,sleep
def Clock(func):
def clock():
print("现在是:",ctime())
func()
sleep(3)
print("现在是:",ctime())
return clock
@Clock
def func():
print("函数计时")
func()
import datetime
now = datetime.datetime.now()#获取当前时间
str = "%s"%(now.strftime("%Y-%m-%d-%H-%M-%S"))
"""
Y 年 y
m 月
d 号
H 时
M 分
S 秒
"""# 设置时间格式print(str)
__slots__属性
使用__slots__时,子类不受影响
class Person(object):
__slots__ = ("name","age")
def__str__(self):
return"姓名:%s,年龄:%d"%(self.name,self.age)
p = Person()
class man(Person):
pass
m = man()
m.score = 78
print(m.score)
使用__slots__限制类添加的属性
class Person(object):
__slots__ = ("name","age")
def__str__(self):
return"姓名:%s,年龄:%d"%(self.name,self.age)
p = Person()
p.name = "Xiaoming"
p.age = 15
print(p)
try:
p.score = 78
except AttributeError :
print(AttributeError)
isinstance方法判断可迭代和迭代器
from collections import Iterable
print(isinstance([],Iterable))
print(isinstance( {}, Iterable))
print(isinstance( (), Iterable))
print(isinstance( ‘abc‘, Iterable))
print(isinstance( ‘100‘, Iterable))
print(isinstance((x for x in range(10) ), Iterable))
‘‘‘
True
D:/见解/Python/Python代码/vacation/python高级/使用isinstance判断是否可以迭代.py:1: DeprecationWarning: Using or importing the ABCs from ‘collections‘ instead of from ‘collections.abc‘ is deprecated since Python 3.3, and in 3.9 it will stop working
True
from collections import Iterable
True
True
True
True
‘‘‘
from collections import Iterator
print(isinstance( [ ], Iterator))
print(isinstance( ‘abc‘, Iterator))
print(isinstance(() , Iterator))
print(isinstance( {} , Iterator))
print(isinstance( 123, Iterator))
print(isinstance( 5+2j, Iterator))
print(isinstance( (x for x in range(10)) , Iterator))
# 生成器可以是迭代器‘‘‘
False
D:/见解/Python/Python代码/vacation/python高级/使用isinstance判断是否是迭代器.py:1: DeprecationWarning: Using or importing the ABCs from ‘collections‘ instead of from ‘collections.abc‘ is deprecated since Python 3.3, and in 3.9 it will stop working
False
from collections import Iterator
False
False
False
False
True
‘‘‘
metaclass 拦截类的创建,并返回
def upper_attr(future_class_name, future_class_parents, future_class_attr):
#遍历属性字典,把不是__开头的属性名字变为大写
newAttr = {}
for name,value in future_class_attr.items():#遍历字典ifnot name.startswith("__"):#如果不是以__开头
newAttr[name.upper()] = value
# 将future_class_attr字典中的键大写,然后赋值return type(future_class_name, future_class_parents, newAttr)#第三个参数为新修改好的值(类名,父类,字典)class Foo(object, metaclass=upper_attr):
# 使用upper_attr对类中值进行修改
bar = ‘bip‘#一开始创建Foo类时print(hasattr(Foo, ‘bar‘))# hasattr查看Foo类中是否存在bar属性print(hasattr(Foo, ‘BAR‘))
f = Foo()#实例化对象print(f.BAR)#输出
timeit_list操作测试
‘‘‘
timeit库Timer函数
‘‘‘from timeit import Timer
def test1():
l = list(range(1000))
def test2():
l = []
for i in range(1000):
l.append(i)
def test3():
l = []
for i in range(1000):
l = l + [i]
def test4():
l = [i for i in range(1000)]
if__name__ == ‘__main__‘:
# Timer函数,函数名,导入包
t1 = Timer("test1()","from __main__ import test1")
# timeit运行次数print(t1.timeit(number = 1000))
t2 = Timer("test2()","from __main__ import test2")
print(t2.timeit(number =1000))
t3 = Timer("test3","from __main__ import test3")
print(t3.timeit(number=1000))
t4 = Timer("test4","from __main__ import test4")
print(t4.timeit(number=1000))
def func_class(string):
if string == ‘class_one‘:
class class_one:
passreturn class_one
else:
class class_two:
passreturn class_two
MyClass = func_class(‘‘)
print("MyClass为 " , MyClass)
m = MyClass()
print("m为 ",m)
‘‘‘
MyClass为 <class ‘__main__.func_class.<locals>.class_two‘>
m为 <__main__.func_class.<locals>.class_two object at 0x000002BC0491B190>
‘‘‘
查看某一个字符出现的次数
#方法一import random
range_lst = [random.randint(0,100) for i in range(100)]
# 创建一个包含有 100 个数据的随机数
range_set = set(range_lst)
# 创建集合,不包含重复元素for num in range_set:
# 对集合进行遍历,查找元素出现的次数# list.count(元素) 查看元素在列表中出现的次数print(num,":",range_lst.count(num))
# 方法二import random
range_lst = [random.randint(0,5) for i in range(10)]
range_dict = dict()
for i in range_lst:
# 默认为 0 次,如果出现一次就 + 1
range_dict[i] = range_dict.get(i,0) +1
print(range_dict)
在类外创建函数,然后使用类的实例化对象进行调用
def f(self,x):
y = x + 3
return y
class Add:
# 创建一个 Add 类def add(self,a):
return a + 4
f1 = f
# 让 f1 等于外面定义的函数 f
n = Add()
# 创建实例化对象print(n.add(4))
# 调用类内定义方法print(n.f1(4))
# 调用类外创建的方法
运行结果:
8
7
[Finished in 0.2s]
需要注意的点:
外部定义的函数第一个参数为 self
创建类的实例化对象使用 Add()
括号不要丢