pytorch中的parametervariable和buffer
Posted jiangkejie
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pytorch中的parametervariable和buffer相关的知识,希望对你有一定的参考价值。
parameter
官网API
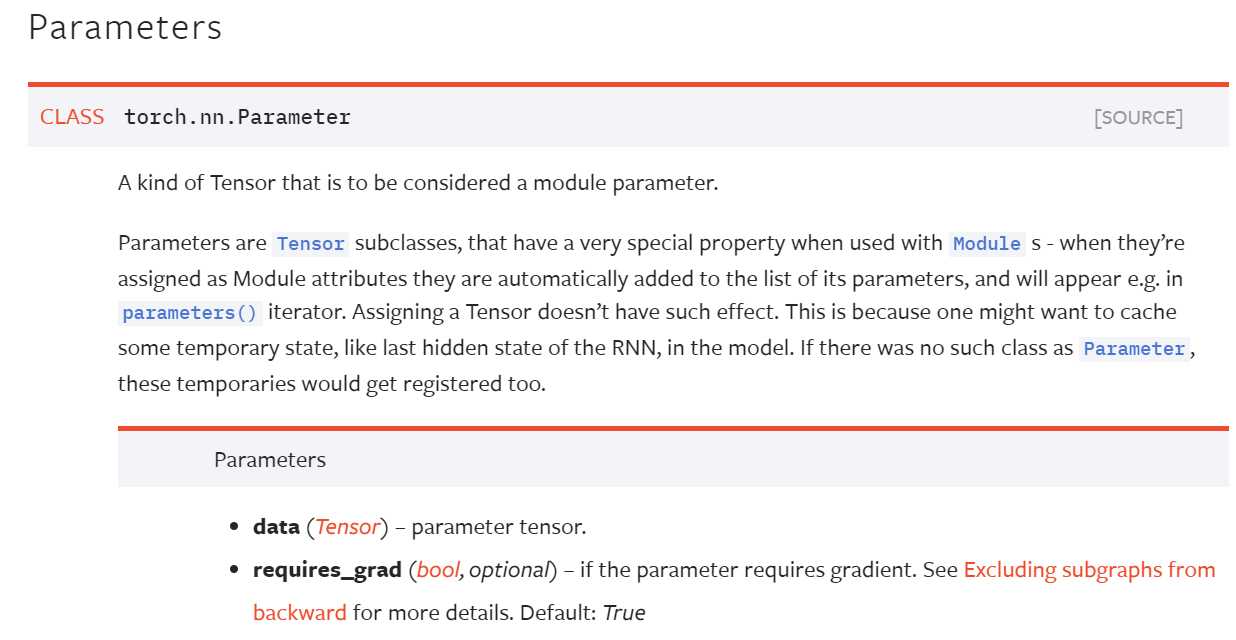
其可以将普通张量转变为模型参数的一部分。Parameters是Tensor的一个子类,当用于Module时具有非常特殊的属性,当其被赋予为模块的属性时,他们自动地添加到模块参数列表中,且将会出现在如parameters()迭代器中。如果赋予一个普通张量则没有这样的效果。这是由于人们可能想要在模型中缓存一些临时状态,如RNN中的上一个隐层状态。如果没有像Parameter这样的类,这些缓存状态也将被注册(只需要缓存,而不是反复注册)。
Answer 1
I will break it down for you. Tensors, as you might know, are multi dimensional matrices. Parameter, in its raw form, is a tensor i.e. a multi dimensional matrix. It sub-classes the Variable class.
The difference between a Variable and a Parameter comes in when associated with a module. When a Parameter is associated with a module as a model attribute, it gets added to the parameter list automatically and can be accessed using the ‘parameters‘ iterator.
Initially in Torch, a Variable (which could for example be an intermediate state) would also get added as a parameter of the model upon assignment. Later on there were use cases identified where a need to cache the variables instead of having them added to the parameter list was identified.
One such case, as mentioned in the documentation is that of RNN, where in you need to save the last hidden state so you don‘t have to pass it again and again. The need to cache a Variable instead of having it automatically register as a parameter to the model is why we have an explicit way of registering parameters to our model i.e. nn.Parameter class.
最初在Torch中,Variable(例如可以是中间状态)也会在赋予时作为模型的参数添加。 后来,确定了需要缓存变量而不是将它们添加到参数列表中的情况。这种情况下,如文档中提到的RNN,您需要保存最后一个隐藏状态,这样就不必一次又一次地传递它。需要缓存一个变量,而不是让它自动注册为模型的参数,这就是为什么我们有一个显式的方式注册parameter到我们的模型,即nn.Parameter类
Answer 2
Recent PyTorch releases just have Tensors, it came out the concept of the Variable has deprecated. (Variable已被弃用)
Parameters are just Tensors limited to the module they are defined (in the module constructor __init__ method).
They will appear inside module.parameters(). This comes handy when you build your custom modules, that learn thanks to these parameters gradient descent.
Anything that is true for the PyTorch tensors is true for parameters, since they are tensors.
Additionally, if module goes to GPU, parameters goes as well. If module is saved parameters will also be saved.
There is a similar concept to model parameters called buffers.
These are named tensors inside the module, but these tensors are not meant to learn via gradient descent, instead you can think these are like variables. You will update your named buffers inside module forward() as you like.
For buffers, it is also true they will go to GPU with the module, and they will be saved together with the module.
Are Parameters only limited being used in __init__()? No, but it is most common to define them inside the __init__ method.
https://stackoverflow.com/questions/50935345/understanding-torch-nn-parameter
https://www.jianshu.com/p/d8b77cc02410
parameter和variable的区别
https://www.jianshu.com/p/cb739922ce88
https://blog.csdn.net/u014244487/article/details/104372441
parameter和buffer的区别
一个基本的区别是parameter会被更新,而buffer不会。
There is a similar concept to model parameters called buffers. These are named tensors inside the module, but these tensors are not meant to learn via gradient descent, instead you can think these are like variables. You will update your named buffers inside module forward() as you like.
https://www.cnblogs.com/jiangkejie/p/13154058.html
https://zhuanlan.zhihu.com/p/89442276
以上是关于pytorch中的parametervariable和buffer的主要内容,如果未能解决你的问题,请参考以下文章
Pytorch Note37 PyTorch 中的循环神经网络模块