GoDance搜索引擎搜索引擎集群模块实现笔记
Posted Dreamchaser追梦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了GoDance搜索引擎搜索引擎集群模块实现笔记相关的知识,希望对你有一定的参考价值。
文章目录
前言
本文主要是为了记录我自己在编写GoDance集群模块时遇到的一些问题和当时的思考以及解决方案
正文
分布式一致如何去做?
当时有两种方式实现共识算法,一种是ES的默认发现模块(采用Gossip算法),一种采用强一致性的craft算法。
写设计方案的时候一开始是参照ES的来做的,但是发现了一些问题,网上也说明了一些问题,最后决定改用已经证明过正确性的Raft算法来实现分布式一致。
超时RPC如何去做?
利用管道和定时器,但是有gorutine泄露的问题,这让我想到能不能主动关闭gorutine,查询了资料后得到的答案是不能,这确实是合乎常理的
在 Go issues 中也有人提过类似问题,Dave Cheney 给出了一些思考:
- 如果一个 goroutine 被强行停止了,它所拥有的资源会发生什么?堆栈被解开了吗?defer 是否被执行?
- 如果执行 defer,该 goroutine 可能可以继续无限期地生存下去。
- 如果不执行 defer,该 goroutine 原本的应用程序系统设计逻辑将会被破坏,这肯定不合理。
- 如果允许强制停止 goroutine,是要释放所有东西,还是直接把它从调度器中踢出去,你想通过此解决什么问题?
所以gorutine只能主动去退出
停止 Goroutine 有几种方法? - 侃豺小哥 - 博客园 (cnblogs.com)
否定了这种方案后,我在网上又找到了其他思路,RPC通信基于底层网络通信,可以通过设置connection的读写超时时间,达到RPC读写超时的目的
翻了半天资料发现16年有一条冻结该包的issue
最后在他的标准库官方文档中发现,该包冻结不接受新功能,完美踩坑,我谢谢你!

最终使用了rpcx
分包代码规范问题
我在我负责的集群模块下面分了好多模块,这造成了包管理的混乱(内部功能实现居然要将内部的用到的字段暴露)
网上搜索有关go分包的规范,发现这篇
Organize your code with Go packages — Master Tricks | by Inanc Gumus | Learn Go Programming
在我的cluster包下,不应该出现不同层次功能的包,要出现也应该是集群的不同实现的包
- Keep your packages small
- Put related packages into sub-directories
- Create your packages as related clusters
- Hide almost everything
- Depend on things that don’t change often
- Go has no sub-packages
- Put tests into the same directory
- Don’t put your code into ./src folders
- Don’t export from the main
- Smaller programs may not need many packages
Naming packages
- Use simple names
- Do not use double or more words in names
- Let the package path speaks for what the package does
- Don’t repeat the package names
- Use common abbreviations
- Avoid generic package names
- Do not use underscores or camel-casing(Just use lowercase letters)
- Note: Names can contain Unicode characters
几天后继续补充,由于之前是写Java的,所以很自然而然的就把Java那套给搬过来了。这里我就把模块和包弄混了,所以在一个项目里建了不同模块,实际上应该共用一个mod,这样有利于版本发布。而权限问题应该由包来解决
日志同步问题
由于我是用raft来实现分布式共识的,而在raft算法中日志同步是增量修改的,并不是修改状态。所以我需要对涉及到的操作进行定义,比如节点增加,增加的参数等等
元数据修改操作:
- 节点增加(还有分片信息)
- 节点删除(同时删除对应的分片)
- 分片增加
- 分片删除
GoDance是一款用go语言编写的分布式搜索引擎,同时也是一款分布式文档数据库。支持分布式搜索以及分布式存储功能,对外提供restful Api接口来操作GoDance。
GoDance整体采用主从架构,实现了Raft算法来保证元数据的一致,并有一系列机制比如tranlog、分片存储、分片迁移、故障转移等来保证集群的高可用和高拓展性;在存储方面,利用了段的思想来提升搜索和插入的性能,同时支持正排索引(B+树)和倒排索引(BST和MAP)来提升搜索能力,并自己实现了相应的数据结构和Linux系统上的持久化机制(MMAP);在路由方面,根据索引内存负载率和机器配置会优先路由效率高的分片节点,同时使用了rpcx来进行rpc调用;在搜索方面,实现了TF-IDF等搜索算法,并利用其实现了相关度搜索。
如何去抽象操作不同类型的日志(日志增加)
- 类型嵌入
- 空接口,实现多种类型的数据结构
- 空接口字段定义操作参数(强制转换,接口+反射)
- 使用1.18新加入的泛型
Go 1.18 泛型全面讲解:一篇讲清泛型的全部 - SegmentFault 思否
仔细想了想发现自己的这个场景还是不太一样的,无法用泛型
最终使用类型断言和反射解决问题
如何实现Raft的日志一致性
可以理解为二阶段提交,但是有个问题——当确定是否要提交之前(等待那个大多数),是否允许提交新的日志
经过一番推演,我的结论是要的,这样可以保证领导者的日志都是最终状态,有利于跟随者向领导者同步日志,同时也是为了保证日志顺序的一致性
如何设计内存中的状态日志的数据结构
需求:
- 日志是一项一项递增的
- 日志存在未提交和提交两种状态,提交的数据需要更新到集群中的状态机中
- Leader的探活请求会携带当前最大的提交日志,跟随者需要根据此来提交之前的
节点删除策略
非主节点直接移除,非主节点保留该数据结构,修改其状态为Dead
go语言没有子包的概念,有点伤,自己写模块的时候会有点乱
go模块依赖问题
今天一早发现项目依赖爆红,跟我说reading tree note: note has no verifiable signatures
验证签名失败,搜了半天,大概明白是mod机制的验证问题,最后受不了了,干脆把pkg依赖全删了重新导,最后成功解决
后来搜索资料发现

大概是我某个依赖包被无意篡改了,或者官方同个版本的依赖包更新,hash变了。总之就是校验失败了
go的程序初始化问题
因为我负责的集群模块依赖配置模块的导入,所以在编写init方法是有一些顾虑
搜了下才发现
golang程序初始化先于main函数执行,由runtime进行初始化,初始化顺序如下:
- 初始化导入的包(包的初始化顺序并不是按导入顺序(“从上到下”)执行的,runtime需要解析包依赖关系,没有依赖的包最先初始化,与变量初始化依赖关系类似,参见golang变量的初始化);
- 初始化包作用域的变量(该作用域的变量的初始化也并非按照“从上到下、从左到右”的顺序,runtime解析变量依赖关系,没有依赖的变量最先初始化,参见golang变量的初始化);
- 执行包的init函数;
所以为了达到效果,config包尽量不要依赖于其他包
节点间自动发现的初始机制
raft算法解决的是分布式共识问题,利用一系列机制来确保日志的一致性。而最开始的节点发现问题并没有解决,所以我需要设计一种机制来促使初始节点的自动发现。
这里总体借鉴ES的设计思路,将集群节点分为Master节点和Data节点
Master节点可以参与Leader的竞选,Data节点主要参与数据存储,一个节点既可以是Master节点,也可以是Data节点,这可以在配置文件中cluster.master 和cluster.Data 进行配置。
为了使自动发现成为可能,我们加入了种子节点的概念,种子节点可以通过cluster.seedNodes进行配置,它是一个数组,每个字符串代表了一个可访问的节点地址。
在节点启动时,开启心跳检查,如果发现自己不在集群中,会向种子节点们发送rpc查询,获取当前的Leader节点地址。如果有Leader节点地址,说明现在已经有Leader,则向该Leader节点发JoinLeader RPC调用;否则则根据自己是否是Master节点来决定自己是否要参与竞选还是不断向种子节点获取当前Leader的地址。
PS:这里要注意就算是参与竞选也不能无脑一直参与,而是得判断自己是否在集群当中,如果不在,则意味着自己根本不在集群,人家根本不知道当前节点存在,所以在这种情况下,竞选失败需要尝试tryJoin的逻辑
- 成功选举,但是种子节点发送失败,这就意味着后期其他节点节点加入时,Leader永远是无法被发现
- 新增一个节点但是该节点没有在clients中就无法发送心跳
Leader删除一个节点同时需要把对应client给删除,同时sendHeart需要判定当前节点是否存在nodes中,如果不存在,则停止发送信息
集群模块的测试问题
在完成了集群模块的功能后,发现测试成了一个问题。
它不像普通的程序那样简单的测试方法,它主要有以下难点:
- 集群模块需要多台机器进行运行测试
- 集群模块中涉及大量的并发编程和网络调用
Raft算法问题思考
由于Raft算法比较复杂,看论文看的晕乎乎的,看网上资料质量又参差不齐,所以在理解这个算法的时候踩了很多坑。其中一个就是term对于选举的影响,当时我忽略了在拉票请求中节点无论投不投票都会更新为更大的term。所以在后面思考问题的时候绕了进去,发现了算法不成立的地方(其中一个节点因为网络延时开始竞选,但此时其他节点又接受到Leader的日志更新,根据不给日志完整性低的节点投票的原则,当前节点陷入无限选举的情况),当时还想着能不能竞选失败去重新尝试加入主节点等其他方案。
明白了term更新的机制也就解开了疑惑,但随之而来还有一些问题,当一个Follower节点仅仅因为网络延时导致开始竞选,那么必然会导致新一轮的竞选,因为term变大的,尽管这个Leader可能不是那个网络时延的节点,但肯定是最完整的节点,这样容易在
raft算法的局限: 1、强领导模型对于写功能基本退化单机性能,量大任然会出现性能瓶颈,适得其反。 2、选举期间会集群将出现短暂不可用现象,影响时长与选举时间相关。
日志完整性问题
如果新领导者不包含这部分日志,这部分日志会覆盖,即“以领导者日志为准,实现各节点日志的一致”,需要我们注意的是,复制到大多数节点的日志项,是不会丢失和改变的,而只被成功复制到少数节点的日志项,可能会被覆盖,也可能最终会被提交。
这里的大多数并不保证提交的大多数,所以在判断日志完整性时,我们不该以Committed的日志Id为标准,而应该以最新插入的日志Id为标准。
这里为了需要有个机制来保证新领导者有大多数的committed:
领导者选举能保证新领导者一定包含这条committed的日志项,但这条日志项在新领导者上处于未提交状态,这时新领导者,会尝试从最新日志项开始,向其他节点复制日志,如果,某条uncommitted的日志项,被发现已经成功复制到大多数节点上,这时这条日志项将处于提交状态,并被应用到状态机,通知其他节点提交这条日志。
此时集群会短暂不可用
如何理解“大多数”
集群配置不是随时变化的,需要按照一定的算法,比如联合共识、单节点变更,来添加和移除节点,也就是集群当前的节点数是已知的
采用哪种数据分片方式?
hash
一致性hash
range hash
function hash+range hash
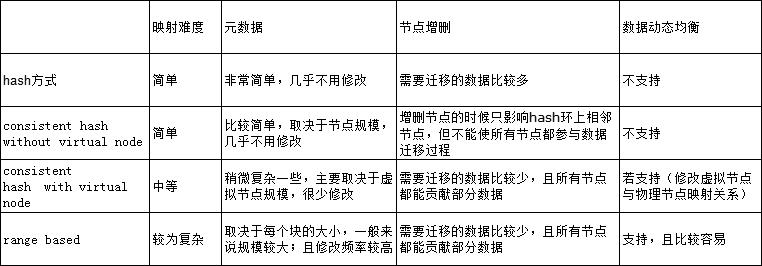
最终还是参考MongoDB的分片方案——hashfunction+ hash range
分布式ID如何生成?
暂时采用UUID的解决方案
特征值如何选定?
特征值由用户选定
以上是关于GoDance搜索引擎搜索引擎集群模块实现笔记的主要内容,如果未能解决你的问题,请参考以下文章